Linux 正则表达式与文本处理器 三剑客
Linux 正则表达式与文本处理器 三剑客
一、正则表达式
正则就是用一些具有特殊含义的符号组合到一起(称为正则表达式)来描述字符或者字符串的方法。或者说:正则就是用来描述一类事物的规则。
在linux中,通配符是由shell解释的,而正则表达式则是由命令解释的,下面我们就为大家介绍三种文本处理工具/命令:grep、sed、awk,它们三者均可以解释正则。
正则介绍:
^行首
$行尾
.除了换行符以外的任意单个字符
.*所有字符
*:左边的那一个字符有0个到无穷个
+:左边的那一个字符有1个到无穷个
?:左边的那一个字符有0个到1个
{n}:左边的那一个字符有n个
{n,m}:左边的那一个字符有n个到m个
{n,}:左边的那一个字符有n个到无穷个
[]字符组内的任一字符
[^]对字符组内的每个字符取反(不匹配字符组内的每个字符)
^[^]非字符组内的字符开头的行
[a-z]:所有的小写字母
[A-Z]:所有的大写字母
[a-zA-Z]:所有的大小写字母,等于[a-Z]
[0-9]:数字
\<单词头 单词一般以空格或特殊字符做分隔,连续的字符串被当做单词
\>单词尾
注意的一点是:如果要匹配的字符就是-本身话,必须放到最后去[123123\-]
扩展正则sed 加 -r参数或转义
grep 加-E或egrep或转义
awk直接支持,但不包含{n,m}
可以使用--posix支持
awk '/ro{1,3}/{print}' /etc/passwd
awk --posix '/ro{1,3}/{print}' /etc/passwd
sed -n '/roo\?/p' /etc/passwd
sed -rn '/roo?/p' /etc/passwd
?前导字符零个或一个
+前导字符一个或多个
abc|def abc或def
a(bc|de)f abcf或adef
x\{m\}x出现m次
x\{m,\}x出现m次至多次(至少m次)
x\{m,n\}x出现m次至n次
二、Linux三剑客 老三-grep
[命令简介]
Linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹 配的行打印出来。grep全称是Global Regular Expression Print,表示全局正则表达式版本,它的使用权限是所有用户。
[功能说明]
grep***** ==擅长过滤器,把想要的或者不想要的分离开。Linux三剑客 老三。
[用法格式]
grep [选项]... PATTERN [FILE]...
[参数选项]
[options]主要参数:
-c :只输出匹配行的计数。
-i :不区分大 小写(只适用于单字符)。
-h :查询多文件时不显示文件名。
-l :查询多文件时只输出包含匹配字符的文件名。
-n :显示匹配行及 行号。
-s :不显示不存在或无匹配文本的错误信息。
-v :排除,不显示过滤的字符串的行;显示不包含匹配文本的所有行。
-E :过滤多个字符串。
-o :输出精确匹配的字符而不是默认的整行。
-f :指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格式为每行一个规则样式。
#Context control:
-B 除了显示匹配的一行之外,并显示该行之前的num行
-A 除了显示匹配的一行之外,并显示该行之后的num行
-C 除了显示匹配的一行之外,并显示该行之前后各num行
grep "String" -B 10 test.txt #显示匹配的String行和String的前10行。
pattern正则表达式主要参数:
\ :忽略正则表达式中特殊字符的原有含义。
^ :匹配正则表达式的开始行。
$ : 匹配正则表达式的结束行。
\< :从匹配正则表达 式的行开始。
\> :到匹配正则表达式的行结束。
[ ] :单个字符,如 [Gg]rep 匹配Grep和grep。
[ - ] :范围,如[A-Z],即A、B、C一直到Z都符合要求。
[^] :匹配一个不在指定范围内的字符,如:'[^A-FH-Z]rep'匹配不包含A-F和H-Z的一个字母开头,紧跟rep的行。
x\{m\} :重复字符x,m次,如:'0\{5\}'匹配包含5个0的行。
x\{m,\} :重复字符x,至少m次,如:'0\{5,\}'匹配至少有5个0的行。
x\{m,n\} :重复字符x,至少m次,不多于n次,如:'0\{5,10\}'匹配5 -- 10个0的行。
. :所有的单个字符。
* :有字符,长度可以为0。
[实践案例]
实战准备:
1、调整别名
alias grep='grep --color=auto'
注意字符集:可能带来的问题
export LC_ALL=C
1、查找指定进程:
[root@localhost ~]# ps -ef|grep svn
root 4943 1 0 Dec05 ? 00:00:00 svnserve -d -r /opt/svndata/grape/
root 16867 16838 0 19:53 pts/0 00:00:00 grep svn
[root@localhost ~]#
#第一条记录是查找出的进程;第二条结果是grep进程本身,并非真正要找的进程。
2、查找指定进程个数:
[root@localhost ~]# ps -ef|grep svn -c
2
[root@localhost ~]# ps -ef|grep -c sshd
6
[root@localhost ~]#
#匹配进程输出多少行的计数。这里表示sshd输出有6行。
3、从文件中读取关键词进行搜索:
[root@localhost test]# cat test.txt
hnlinux
peida.cnblogs.com
ubuntu
ubuntu linux
redhat
Redhat
linuxmint
[root@localhost test]# cat test2.txt
linux
Redhat
[root@localhost test]# cat test.txt | grep -f test2.txt
hnlinux
ubuntu linux
Redhat
linuxmint
[root@localhost test]#
#输出test.txt文件中含有从test2.txt文件中读取出的关键词的内容行。
4、从文件中读取关键词进行搜索 且显示行号:
[root@localhost test]# cat test.txt
hnlinux
peida.cnblogs.com
ubuntu
ubuntu linux
redhat
Redhat
linuxmint
[root@localhost test]# cat test2.txt
linux
Redhat
[root@localhost test]# cat test.txt | grep -nf test2.txt
1:hnlinux
4:ubuntu linux
6:Redhat
7:linuxmint
[root@localhost test]#
#输出test.txt文件中含有从test2.txt文件中读取出的关键词的内容行,并显示输出每一行的行号。
5、从文件中查找关键词 并显示行号:
[root@localhost test]# grep 'linux' test.txt
hnlinux
ubuntu linux
linuxmint
[root@localhost test]# grep -n 'linux' test.txt
1:hnlinux
4:ubuntu linux
7:linuxmint
[root@localhost test]#
#显示匹配字符串’linux’的行,并且显示输出行的行号。
6、从多个文件中查找关键词:
[root@localhost test]# grep -n 'linux' test.txt test2.txt
test.txt:1:hnlinux
test.txt:4:ubuntu linux
test.txt:7:linuxmint
test2.txt:1:linux
#文件名:行号:匹配内容的行
[root@localhost test]# grep 'linux' test.txt test2.txt
test.txt:hnlinux
test.txt:ubuntu linux
test.txt:linuxmint
test2.txt:linux
[root@localhost test]#
#多文件时,输出查询到的信息内容行时,会把文件的命名在行最前面输出并且加上":"作为标示符。
7、grep不显示本身进程:
[root@localhost test]# ps aux|grep ssh
root 2720 0.0 0.0 62656 1212 ? Ss Nov02 0:00 /usr/sbin/sshd
root 16834 0.0 0.0 88088 3288 ? Ss 19:53 0:00 sshd: root@pts/0
root 16901 0.0 0.0 61180 764 pts/0 S+ 20:31 0:00 grep ssh
[root@localhost test]# ps aux|grep [s]sh
root 2720 0.0 0.0 62656 1212 ? Ss Nov02 0:00 /usr/sbin/sshd
root 16834 0.0 0.0 88088 3288 ? Ss 19:53 0:00 sshd: root@pts/0
[root@localhost test]# ps aux | grep ssh | grep -v "grep"
root 2720 0.0 0.0 62656 1212 ? Ss Nov02 0:00 /usr/sbin/sshd
root 16834 0.0 0.0 88088 3288 ? Ss 19:53 0:00 sshd: root@pts/0
#ps -aux|grep [s]sh这句命令意思笔者也不是很清楚,但是能实现效果;ps aux | grep ssh 输出结果继续交给管道后面的grep -v "grep"命令处理,-v过滤掉了 grep 本身进程。
8、找出以u开头的行内容:
[root@localhost test]# cat test.txt |grep ^u
ubuntu
ubuntu linux
[root@localhost test]#
#使用正则表达式“ ^ ”匹配以u字母的开始行;“ ^ ”放在要匹配的字符串前。
9、输出非u开头的行内容:
[root@localhost test]# cat test.txt |grep ^[^u]
hnlinux
peida.cnblogs.com
redhat
Redhat
linuxmint
[root@localhost test]#
10、输出以hat结尾的行内容:
[root@localhost test]# cat test.txt |grep hat$
redhat
Redhat
[root@localhost test]#
#使用正则表达式“ $ ”匹配以hat字符串为结尾的行;“ $ ”放在要匹配的字符串后。
11、ifconfig匹配过滤出ip地址:
[root@localhost test]# ifconfig eth0|grep "[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}"
inet addr:192.168.120.204 Bcast:192.168.120.255 Mask:255.255.255.0
[root@localhost test]# ifconfig eth0|grep -E "([0-9]{1,3}\.){3}[0-9]"
inet addr:192.168.120.204 Bcast:192.168.120.255 Mask:255.255.255.0
[root@localhost test]#
#“[0-9]\{1,3\}\.”表示“.”符号前面重复0-9中的数字,至少1个,不多于或等于3个。“\”转义符,把原本的意义(马甲)去掉,比如“\{1,3\}”把“{ 和 }”符号默认的意义转变成其它意义。
# "([0-9]{1,3}\.){3}[0-9]" 表示匹配包含3个 ([0-9]{1,3}\.) 字符串的行,并且后面匹配有[0-9]中的数字。
12、显示包含ed或者at字符的内容行:
[root@localhost test]# cat test.txt |grep -E "peida|com"
peida.cnblogs.com
[root@localhost test]# cat test.txt |egrep "ed|at"
redhat
Redhat
[root@localhost test]#
#使用-E匹配(过滤)出多个字符串,用“|”符号隔开字符串。
#‘egrep’即‘grep -E’。‘fgrep’即‘grep -F’。使用egrep等于使用grep -E。
13、显示当前目录下面以.txt 结尾的文件中的所有包含每个字符串至少有7个连续小写字符的字符串的行:
[root@localhost test]# grep '[a-z]\{7\}' *.txt
test.txt:hnlinux
test.txt:peida.cnblogs.com
test.txt:linuxmint
[root@localhost test]#
#重复匹配所有小写字母7次的行。默认是区分大小写的,所以用小写字母匹配就不会匹配到大写。-i可以解除区分大小写的限制。
14、上下文控制Context control参数选项的使用:
[root@oldboy66-23 ~]# seq 100 >test.txt
[root@oldboy66-23 ~]# grep "20" -A 3 test.txt
20
21
22
23
[root@oldboy66-23 ~]# grep "20" -B 3 test.txt
17
18
19
20
[root@oldboy66-23 ~]# grep "20" -C 2 test.txt
18
19
20
21
22
Context control上下文控制参数小结:
-B 除了显示匹配的一行之外,并显示该行之前的num行
-A 除了显示匹配的一行之外,并显示该行之后的num行
-C 除了显示匹配的一行之外,并显示该行之前后各num行
使用格式: grep "String" -B 10 test.txt
15、正则表达式案例一:
案例文件内容:
[root@oldboy oldboy]# cat oldboy.log
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
============================================
实战举例:
1)^word 搜索以word开头的。vi ^一行的开头
2)word$ 搜索以word结尾的。vi $一行的末尾
3)^$ 表示空行,能理解么?
============================================
a.过滤出来以m开头的行
[root@oldboy log]# grep "^m" oldboy.log
my blog is http://oldboy.blog.51cto.com
my qq num is 49000448.
my god ,i am not oldbey,but OLDBOY!
b.过滤出来以m结尾的行
[root@oldboy log]# grep "m$" oldboy.log
my blog is http://oldboy.blog.51cto.com
[root@oldboy log]# cat -n oldboy.log
1 I am oldboy teacher!
2 I teach linux.
3
4 I like badminton ball ,billiard ball and chinese chess!
5 my blog is http://oldboy.blog.51cto.com
6 our site is http://www.etiantian.org
7 my qq num is 49000448.
8
9 not 4900000448.
10 my god ,i am not oldbey,but OLDBOY!
c.过滤掉空行
[root@oldboy log]# grep -v "^$" oldboy.log
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
[root@oldboy log]# grep -vn "^$" oldboy.log #过滤掉空行且显示行号
1:I am oldboy teacher!
2:I teach linux.
4:I like badminton ball ,billiard ball and chinese chess!
5:my blog is http://oldboy.blog.51cto.com
6:our site is http://www.etiantian.org
7:my qq num is 49000448.
9:not 4900000448.
10:my god ,i am not oldbey,but OLDBOY!
16、正则表达式案例二:
实战举例:
4). 代表且只能代表任意一个字符。
5)\ 例 \. 就只代表点本身,转义符号,让有着特殊身份意义的字符,脱掉马甲,还原原形。\$。
6)* 例 s* 重复0个或多个前面的一个字符
7).* 匹配所有字符。延伸 ^.* 以任意多个字符开头。 .*$ 以任意多个字符结尾
=============================================
a.匹配任意一个字符
[root@oldboy log]# grep "." oldboy.log
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
#没有空行?因为“.”代表任意一个字符,空行没有字符,所以匹配不到。
b.匹配以点为结尾的(错误方法)
[root@oldboy log]# grep ".$" oldboy.log #系统把“.”识别成了正则表达式的字符
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
c.只匹配点, \ 转义。(正确方法)
[root@oldboy log]# grep "\.$" oldboy.log
I teach linux.
my qq num is 49000448.
not 4900000448.
#使用转义符“\”让有着特殊身份意义的字符,脱掉马甲,还原原形。
d.“*”的例子,及-o精确匹配输出。
[root@oldboy log]# grep "0*" oldboy.log #使用“*”不会过滤掉原来的内容
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
[root@oldboy log]# grep -o "0*" oldboy.log
000
00000
=============================================
e.“.*”的匹配。
[root@oldboy log]# grep ".*" oldboy.log #匹配所有字符,所以全部都输出了
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
[root@oldboy log]# grep "^.*" oldboy.log #匹配所有字符任意长度开头
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
[root@oldboy log]# grep ".*$" oldboy.log #匹配所有字符任意长度结尾
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
f.“.”的深入匹配。
[root@oldboy-test ~]# echo 'oldb y' >>oldboy.log
[root@oldboy-test ~]# tail -1 oldboy.log
oldb y
[root@oldboy log]# grep "oldb.y" oldboy.log #匹配oldb“任意字符”y
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
oldb y
[root@oldboy log]# grep -o "oldb.y" oldboy.log #匹配oldb“任意字符”y
oldboy
oldboy
oldbey
oldb y
#空格也算是字符,所以oldb y被匹配出来了。注意,但是空行没有字符。
17、正则表达式案例三:
实战举例:
8)[abc] 匹配字符集合内的任意一个字符[a-zA-Z],[0-9]。
9)[^abc] 匹配不包含^后的任意字符的内容。中括号里的^为取反,注意和以..开头区别。
10)a\{n,m\} 重复n到m次,前一个重复的字符。如果用egrep/sed -r可以去掉转义符。
11)\{n,\} 重复至少n次,前一个重复的字符。如果用egrep/sed -r可以去掉转义符。
12)\{n\} 重复n次,前一个重复的字符。如果用egrep/sed -r可以去掉转义符。
13)\{,m\} ?????? #“\{,m\}”按照man grep的说明来测试,没成功
注意:egrep,grep -E或sed -r过滤一般特殊字符可以不转义。
=============================================
a.过滤出ifconfig eth0的IP行。
[root@localhost test]# ifconfig eth0|grep "[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}"
inet addr:192.168.120.204 Bcast:192.168.120.255 Mask:255.255.255.0
[root@localhost test]# ifconfig eth0|grep -E "([0-9]{1,3}\.){3}[0-9]"
inet addr:192.168.120.204 Bcast:192.168.120.255 Mask:255.255.255.0
[root@localhost test]#
两种匹配的区别:
从下图中可以看出,第一种匹配匹配得不完整,192.168.28.130后面的30没有被匹配到。第二种匹配则把4段ip全部匹配了,推荐用第二种匹配方法,这样更专业、更规范!
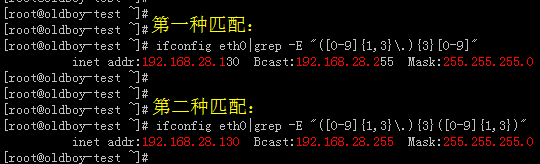
#“[0-9]\{1,3\}\.”表示“.”符号前面重复0-9中的数字,至少1个,不多于或等于3个。“\”转义符,把原本的意义(马甲)去掉,比如“\{1,3\}”把“{ 和 }”符号默认的意义转变成其它意义。
# "([0-9]{1,3}\.){3}[0-9]" 表示匹配包含3个 ([0-9]{1,3}\.) 字符串的行,并且后面匹配有[0-9]中的数字。
小结:
grep一般常用参数:
“*”星越多表示越重要!五星最重要!
-a:在二进制文件中,以文本文件的方式搜索数据
没加-a前,匹配二进制文件会提示:

[root@localhost ~]# grep 1 /bin/cp
Binary file /bin/cp matches
加-a后,就可以匹配二进制文件了。但是匹配后会产生乱码,所以这里就不截图了。
#-a的乱码解决方法可以退出重新进入 或者setup然后退出。
-c:计算找到 ’搜索字符串’ 的次数
[root@localhost ~]# ps -ef|grep svn -c
2
[root@localhost ~]# ps -ef|grep -c sshd
6
[root@localhost ~]#
-o:仅显示出匹配regexp的内容
[root@oldboy oldboy]# cat oldboy.log
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
my qq num is 49000448.
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
[root@oldboy log]# grep -o "0*" oldboy.log
000
00000
-i*****:忽略大小写的不同,所以大小写视为相同*****
[root@oldboy log]# grep -i "OLDb.y" oldboy.log
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
oldb y
[root@oldboy log]# grep -oi "oLDb.Y" oldboy.log
oldboy
oldboy
oldbey
oldb y
-n*****:在行首显示匹配内容行的行号*****
[root@localhost test]# grep -n 'linux' test.txt
1:hnlinux
4:ubuntu linux
7:linuxmint
[root@localhost test]#
-v*****:反向选择,即不显示 ‘搜索字符串’ 内容的那一行*****
[root@localhost test]# ps aux | grep ssh | grep -v "grep"
root 2720 0.0 0.0 62656 1212 ? Ss Nov02 0:00 /usr/sbin/sshd
root 16834 0.0 0.0 88088 3288 ? Ss 19:53 0:00 sshd: root@pts/0
-E*****:扩展的grep,即egrep*****
[root@localhost test]# cat test.txt |grep -E "peida|com"
peida.cnblogs.com
[root@localhost test]# cat test.txt |egrep "ed|at"
redhat
Redhat
[root@localhost test]#
--color=auto***:以特定颜色高亮显示匹配关键字(不是整行)***
效果截图:

#提示: -i -v 为常用参数。
Context control上下文控制参数:
使用格式: grep "String" -B 10 test.txt
-A:After的意思,显示匹配字符串及其后n行的数据
[root@oldboy66-23 ~]# seq 100 >test.txt
[root@oldboy66-23 ~]# grep "20" -A 3 test.txt
20
21
22
23
-B:beforce的意思,显示匹配字符串及其前n行的数据
[root@oldboy66-23 ~]# grep "20" -B 3 test.txt
17
18
19
20
-C:显示匹配字符串及其前后各num行的数据
[root@oldboy66-23 ~]# grep "20" -C 2 test.txt
18
19
20
21
22
grep一般常用参数(以上清单):
-a:在二进制文件中,以文本文件的方式搜索数据
-c:计算找到 ’搜索字符串’ 的次数
-o:仅显示出匹配regexp的内容(用于统计出现在文中的次数)
-i*****:忽略大小写的不同,所以大小写视为相同*****
-n*****:在行首显示匹配内容行的行号*****
-v*****:反向选择,即不显示 ‘搜索字符串’ 内容的那一行*****
-E*****:扩展的grep,即egrep*****
--color=auto***:以特定颜色高亮显示匹配关键字(不是整行)***
#提示: -i -v 为常用参数。
-A:After的意思,显示匹配字符串及其后n行的数据
-B:beforce的意思,显示匹配字符串及其前n行的数据
-C:显示匹配字符串及其前后各num行的数据
三、Linux三剑客 老二-sed
sed***** ==(stream editor)擅长取行、替换 Linux三剑客 老二。
过滤:sed -n '/过滤的内容/处理的命令' 文件
-n 取消sed的默认输出
-i 改变文件内容。
处理的命令:p print打印;d delete删除
例子:
sed '/oldboy/d' test.txt
sed -n '/oldboy/p' test.txt
sed替换:*****
sed -i 's#oldboy#oldgirl#g' test.txt
s 常说的查找并替换,用一个字符串替换成另一个
g (global)与s联合使用时,表示对当前行全局替换(与下一个g意义不同)
-i 修改文件内容
"#"是分隔符,可以用 / @ 等替换
sed -r 's#(.*)#I am \1#g' test.txt
= 表示行号
sed '/$/a\\n' test.txt 可以在文件的每行末尾添加一个回车
sed '$a\eof' test.txt 可以在文件的末尾添加'eof'
sed 选项参数 命令
例如:
#sed -n '3p' test.txt #静默输出第3行内容,3为定位行位置,p为命令
#sed ‘4a abcd’ test.txt #第4行追加abcd字符,a为命令
选项参数:
-n:静默处理,不打印输出结果
命令:
p:打印
c:替换行内容
a:追加内容
i:插入内容
1,4d:删除1到4行内容
1d,4d:删除1行和4行内容
d:删除
//:命令中使用正则表达式放入//中
//d:删除正则匹配到的行
s:替换
s/aaa/bbb/g:将全部行中的aaa替换为bbb,不加g则每行只替换第一个aaa
s/()()/\1\2/g:匹配两个括号中的内容,\1\2表示将第一个括号和第二个括号内容显示
例如:
#sed 's/^(.)(.*)$/\2/' test.txt #test文件中任意行去掉第一个字符,^(.)任意单字符开始,(.*)任意0到无穷字符,\2只显示第二个括号部分
四、Linux三剑客 老大-awk
awk***** ==一门语言,可以过滤内容(擅长取列),打印,删除。Linux三剑客 老大
awk -F "分隔符号" '{print $1}' 文件
<==$1第一列,$2第二列...$NF最后一列,$(NF-1)倒数第二列
例:awk '{if(NR<31 && NR>19) printf $1"\n"}' test.txt
NR代表行号,&&(and)并且,\n回车换行,$0 表示整行
awk多分隔符用法:
[root@oldboy-test ~]# cat oldboy.txt
I am oldboy,myqq is 49000448
[root@oldboy oldboy]# awk -F "[, ]" '{print $3" "$6}' oldboy.txt
oldboy 49000448
测试文件:
[root@sunday ~]# cat test.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
[root@sunday ~]# awk -F ":" '{print $1,$NF}' test.txt
root /bin/bash
bin /sbin/nologin
daemon /sbin/nologin
adm /sbin/nologin
lp /sbin/nologin
sync /bin/sync
shutdown /sbin/shutdown
halt /sbin/halt
mail /sbin/nologin
operator /sbin/nologin
[root@sunday ~]# awk -F ":" '{print $1,$NF}' test.txt
root /bin/bash
bin /sbin/nologin
daemon /sbin/nologin
adm /sbin/nologin
lp /sbin/nologin
sync /bin/sync
shutdown /sbin/shutdown
halt /sbin/halt
mail /sbin/nologin
operator /sbin/nologin
[root@sunday ~]# awk -F ":" '{print $1,NR}' test.txt
root 1
bin 2
daemon 3
adm 4
lp 5
sync 6
shutdown 7
halt 8
mail 9
operator 10
[root@sunday ~]# cat test.txt |cut -d : -f 1,2
root:x
bin:x
daemon:x
adm:x
lp:x
sync:x
shutdown:x
halt:x
mail:x
operator:x
[root@sunday ~]# awk -F ":" 'NR<=3{print NR,$1}' test.txt
1 root
2 bin
3 daemon
[root@sunday ~]# awk -F ":" 'NR<=3{print NR,"-------",$1}' test.txt
1 ------- root
2 ------- bin
3 ------- daemon
[root@sunday ~]# awk -F ":" 'NR<=2 || NR>=7{print NR,"-------",$1}' test.txt
1 ------- root
2 ------- bin
7 ------- shutdown
8 ------- halt
9 ------- mail
10 ------- operator
打印以nologin结尾的用户名:
[root@sunday ~]# awk -F ":" '/nologin$/{print NR,"-------",$1}' test.txt
2 ------- bin
3 ------- daemon
4 ------- adm
5 ------- lp
9 ------- mail
10 ------- operator
测试文件1:
[root@sunday ~]# cat test.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
rat:x:0:0:root:/root:/bin/bash
r1t:x:0:0:root:/root:/bin/bash
[root@sunday ~]# awk -F ":" '$1~/^r.*t$/{print NR,"-------",$1,$3}' test.txt
1 ------- root 0
12 ------- rat 0
13 ------- r1t 0
[root@sunday ~]#
[root@sunday ~]# awk -F ":" '$3>=7 {print NR,"-------",$1,$3}' test.txt
8 ------- halt 7
9 ------- mail 8
10 ------- operator 11
[root@sunday ~]# awk -v x=$count -F ":" '$3>=x {print $1,$3}' test.txt
halt 7
mail 8
operator 11
[root@sunday ~]# count=8
[root@sunday ~]# awk -v x=$count -F ":" '$3>=x {print $1,$3}' test.txt
mail 8
operator 11
测试文件2:
[root@sunday ~]# cat a.txt|sort
2222222222
4444444444
777777777777
99999999999999
99999999999999
99999999999999
aaaaaaaaaa
aaaaaaaaaa
aaaaaaaaaa
aaaaaaaaaa
aaaaaaaaaa
aaaaaaaaaa
aaaaaaaaaa
aaaaaaaaaa
aaaaaaaaaa
aaaaaaaaaa
aaaaaaaaaa
aaaaaaaaaa
aaaaaaaaaa
aaaaaaaaaa
aaaaaaaaaa
aaaaaaaaaa
aaaaaaaaaa
排序去重:
[root@sunday ~]# cat a.txt|sort|uniq
2222222222
4444444444
777777777777
99999999999999
aaaaaaaaaa
[root@sunday ~]# cat a.txt|sort -u
2222222222
4444444444
777777777777
99999999999999
aaaaaaaaaa
[root@sunday ~]# cat a.txt|sort -u|uniq -c
1 2222222222
1 4444444444
1 777777777777
1 99999999999999
1 aaaaaaaaaa

 浙公网安备 33010602011771号
浙公网安备 33010602011771号