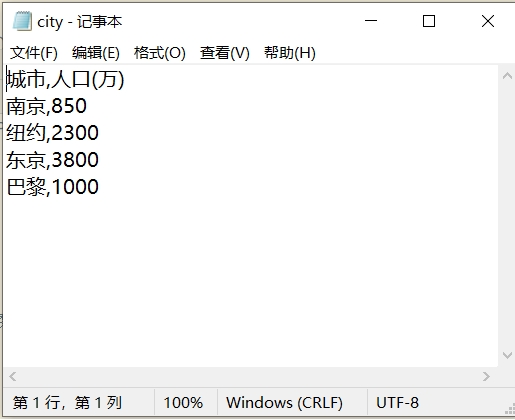
1 #task1_1
2 title=['城市', '人口(万)']
3 info=[['南京', '850'],
4 ['纽约', '2300'],
5 ['东京', '3800'],
6 ['巴黎', '1000']]
7 with open('city.csv','w',encoding='utf-8')as f:
8 f.write(','.join(title)+'\n')
9 for item in info:
10 f.write(','.join(item)+'\n')
11
12 #task1_2
13 with open('city.csv','r',encoding='utf-8')as f:
14 print(f.read().rstrip('\n'))
15 f.close()
16
17 #task1_3
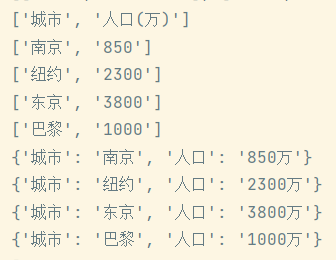
18 with open('city.csv','r',encoding='utf-8')as f:
19 data=f.readlines()
20 print('data=')
21 print(data)
22 info=[line.rstrip('\n').split(',') for line in data]
23 print('info=')
24 print(info)
![]()
![]()
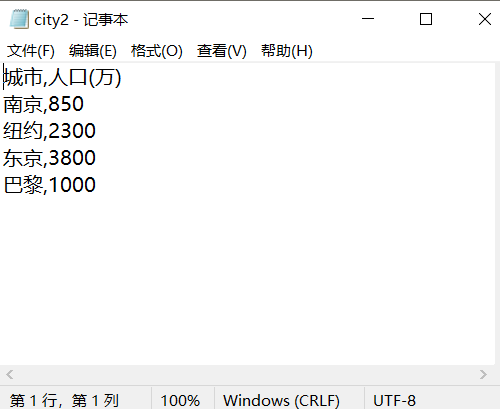
#task2_1
import csv
title=['城市', '人口(万)']
info=[['南京', '850'],
['纽约', '2300'],
['东京', '3800'],
['巴黎', '1000']]
with open('city2.csv','w',encoding='utf-8',newline='') as f:
f_writer=csv.writer(f)
f_writer.writerow(title)
f_writer.writerows(info)
#task2_2
import csv
with open('city2.csv','r',encoding='utf-8') as f:
f_reader=csv.reader(f)
for line in f_reader:
print(line)
#task2_3
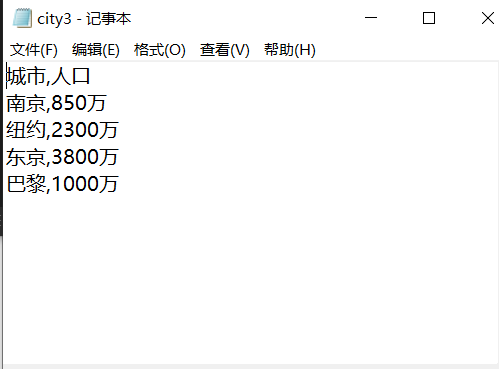
import csv
with open('city3.csv','w',encoding='utf-8',newline='') as f:
title = ['城市', '人口']
f_writer=csv.DictWriter(f,fieldnames=title)
f_writer.writeheader()
f_writer.writerow({'城市':'南京', '人口': '850万'})
f_writer.writerow({'城市':'纽约', '人口': '2300万'})
f_writer.writerow({'城市':'东京', '人口': '3800万'})
f_writer.writerow({'城市': '巴黎', '人口': '1000万'})
#task2_4
import csv
with open('city3.csv','r',encoding='utf-8')as f:
f_reader=csv.DictReader(f)
for line in f_reader:
print(line)
![]()
![]()
![]()
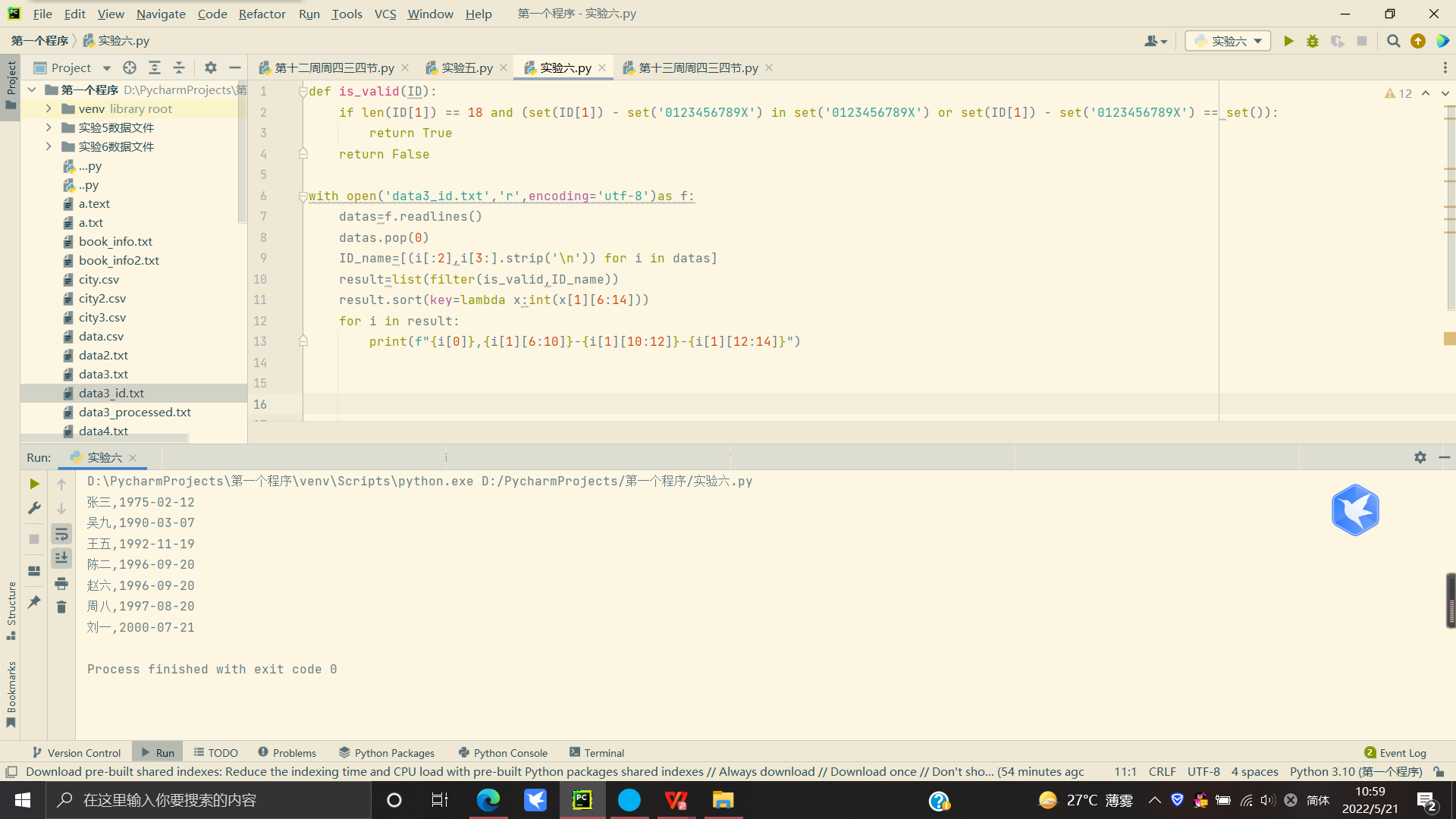
1 #task3
2 def is_valid(ID):
3 if len(ID[1]) == 18 and (set(ID[1]) - set('0123456789X') in set('0123456789X') or set(ID[1]) - set('0123456789X') == set()):
4 return True
5 return False
6
7 with open('data3_id.txt','r',encoding='utf-8')as f:
8 datas=f.readlines()
9 datas.pop(0)
10 ID_name=[(i[:2],i[3:].strip('\n')) for i in datas]
11 result=list(filter(is_valid,ID_name))
12 result.sort(key=lambda x:int(x[1][6:14]))
13 for i in result:
14 print(f"{i[0]},{i[1][6:10]}-{i[1][10:12]}-{i[1][12:14]}")
![]()
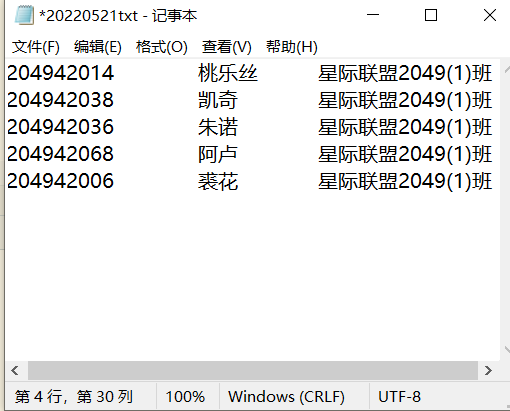
1 #task5_1
2 with open('data5_1.txt','r',encoding='utf-8')as f:
3 data=f.readlines()
4 for i in data:
5 i.strip("\n")
6 import random
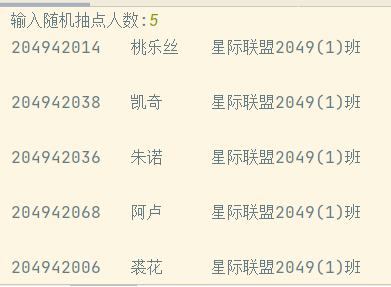
7 n=int(input('输入随机抽点人数:'))
8 sample=random.sample(data,n)
9 import datetime
10 t=datetime.datetime.now()
11 filename=t.strftime('%Y%m%d')+'txt'
12 with open(filename,'w',encoding='utf-8')as f:
13 for i in sample:
14 print(i)
15 f.write(i+'\n')
![]()
![]()
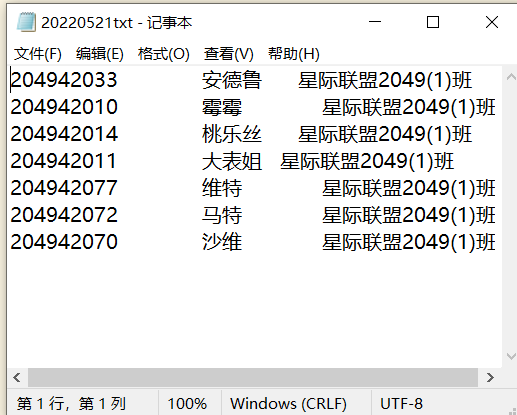
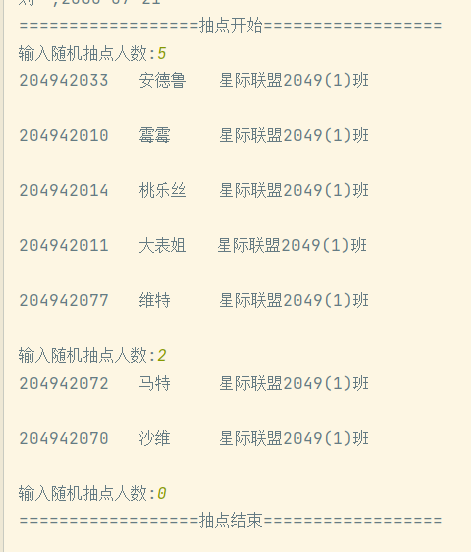
1 #task5_2
2 with open('data5_1.txt','r',encoding='utf-8')as f:
3 data=f.readlines()
4 for i in data:
5 i.strip("\n")
6 import datetime
7 t=datetime.datetime.now()
8 filename=t.strftime('%Y%m%d')+'txt'
9 print(f"{'抽点开始':=^40}")
10 import random
11 while True:
12 n=int(input('输入随机抽点人数:'))
13 sample=random.sample(data,n)
14 for i in sample:
15 data.remove(i)
16 with open(filename, 'a+', encoding='utf-8') as f:
17 for i in sample:
18 print(i)
19 f.write(i)
20 if n==0:
21 print(f"{'抽点结束':=^40}")
22 break
![]()
![]()



 浙公网安备 33010602011771号
浙公网安备 33010602011771号