Scrapy框架
介绍
Scrapy是一个基于Twisted的异步处理框架, 是纯Python实现的爬虫框架, 其架构清晰, 模块之间的耦合程度低, 可扩展性极强, 可以灵活完成各种需求. 我们只需要定制开发几个模块就可以轻松实现一个爬虫.
Scrapy依赖twisted
安装
linux下,
pip3 install scrapy
目录结构
scrapy.cfg 项目的主配置信息。(真正爬虫相关的配置信息在settings.py文件中)
items.py 设置数据存储模板,用于结构化数据,如:Django的Model
pipelines 数据处理行为,如:一般结构化的数据持久化
settings.py 配置文件,如:递归的层数、并发数,延迟下载等
spiders 爬虫目录,如:创建文件,编写爬虫规则
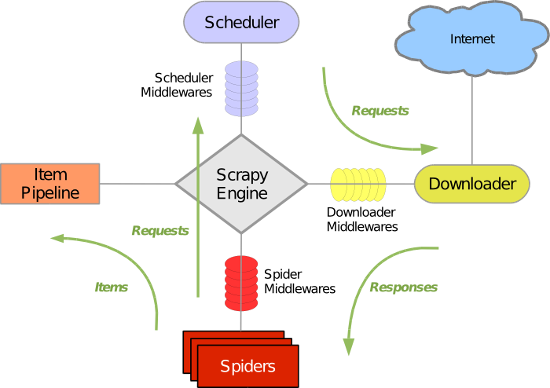
Scrapy主要包括了以下组件
引擎(Scrapy) 用来处理整个系统的数据流处理, 触发事务(框架核心)
调度器(Scheduler) 用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
下载器(Downloader) 用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
爬虫(Spiders) 爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
项目管道(Pipeline) 负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
下载器中间件(Downloader Middlewares) 位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
爬虫中间件(Spider Middlewares) 介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。
调度中间件(Scheduler Middewares) 介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
执行流程
1. 【引擎】找到要执行的爬虫,并执行爬虫的 start_requests 方法,并的到一个 迭代器。 2. 迭代器循环时会获取Request对象,而request对象中封装了要访问的URL和回调函数。 3. 将所有的request对象(任务)放到【调度器】中,用于以后被【下载器】下载。 4. 【下载器】去【调度器】中获取要下载任务(就是Request对象),下载完成后执行回调函数。 5. 回到spider的回调函数中 yield Request() # 再次发起请求 yield Item() # 触发一个信号去pipeline
一. 简单使用
1 创建project scrapy startproject <项目名称> 2 创建爬虫 cd <项目名称> scrapy genspider <爬虫名> <网址> # 如 scrapy genspider chouti chouti.com 3 启动爬虫 scrapy crawl <爬虫名> --nolog # 不打印日志
二. 回调函数中常用用法
def parse(self, response): # response, 封装了响应相关的所有数据 # 1 响应相关 # response.text # response.encoding # response.body # response.requeset # 当前响应时有那个请求发起, 请求中封装了(要访问的url, 回调函数) # 2 解析相关 response.xpath('//div[@href="x1"]/a').extract().extract_first() response.xpath('//div[@href="x1"]/a/text()').extract() tag_list = response.xpath('//div[@href="x1"]/a') for tag in tag_list: tag.xpath('.//p/text()').extract_first() # 3 再次发起请求 yield Request(url='xx', callback=self.parse)
三. pipeline
当Spider解析完Response之后,Item就会传递到Item Pipeline,被定义的Item Pipeline组件会顺次调用,完成一连串的处理过程,比如数据清洗、存储等。
Item Pipeline的主要功能有如下4点。
- 清理HTML数据。
- 验证爬取数据,检查爬取字段。
- 查重并丢弃重复内容。
- 将爬取结果保存到数据库。
主要的方法


1. process_item(item, spider)。 # 核心方法 process_item()是必须要实现的方法,它必须返回Item类型的值或者抛出一个DropItem异常。 返回的是Item对象,那么此Item会被低优先级的Item Pipeline的process_item()方法处理,直到所有的方法被调用完毕。 如果它抛出的是DropItem异常,那么此Item会被丢弃,不再进行处理。 process_item()方法的参数有如下两个。 item,是Item对象,即被处理的Item。 spider,是Spider对象,即生成该Item的Spider。 2. open_spider(spider)。 在Spider开启的时候被自动调用的。在这里我们可以做一些初始化操作,如开启数据库连接等。其中,参数spider就是被开启的Spider对象。 3. close_spider(spider)。 在Spider关闭的时候自动调用的。在这里我们可以做一些收尾工作,如关闭数据库连接等。其中,参数spider就是被关闭的Spider对象。 4. from_crawler(cls, crawler)。 是一个类方法,用@classmethod标识,是一种依赖注入的方式。它的参数是crawler,通过crawler对象,我们可以拿到Scrapy的所有核心组件,如全局配置的每个信息,然后创建一个Pipeline实例。
使用
1. 先写Item类
import scrapy class TxtItem(scrapy.Item): content = scrapy.Field() href = scrapy.Field()
2. 再写pipeline类
# pipeline是所有爬虫公用的, 给某个爬虫定制pipeline, 使用spider.name
from scrapy.exceptions import DropItem class TxtPipeline(object): """ 源码内容: 1. 判断当前XdbPipeline类中是否有from_crawler 有: obj = XdbPipeline.from_crawler(....) 否: obj = XdbPipeline() 2. obj.open_spider() 3. obj.process_item()/obj.process_item()/obj.process_item()/obj.process_item()/obj.process_item() 4. obj.close_spider() """ def __init__(self, path): self.f = None self.path = path @classmethod def from_crawler(cls, crawler): # 初始化时, 用于创建pipeline对象 path = crawler.settings.get('TXTPATH') return cls(path) def open_spider(self, spider): # 爬虫开始执行 print('爬虫开始了') self.f = open(self.path, 'a+', encoding='utf-8') def process_item(self, item, spider): # item为字典数据格式 # yield item对象时, 执行 print('保存在到数据库中...') self.f.write(json.dumps(dict(item), ensure_ascii=False)+'\n') # return item # 交给下一个pipeline的process_item()方法 raise DropItem() # 下一个pipeline的process_item方法中断不执行 def close_spider(self, spider): # 爬虫结束时执行 print('爬虫结束了') self.f.close()
3. 配置pipeline
# 可以配置多个pipeline, 值越小, 优先级越高
ITEM_PIPELINES = { 'scrapy_env.pipelines.TxtPipeline': 300, }
4. 爬虫中
# yield每执行一次,process_item就调用一次。
yield TxtItem(content=content, href=href) # 会自动执行pipeline里的process_item方法
四. url去重规则
原理: 把爬取请求放到调度器的爬取队列前先去配置文件里指定的【去重规则类】里检验
1. 系统默认的url去重规则
# dont_filter=False (遵从去重规则, 默认配置) # dont_filter=True (不遵从去重规则) yield Request(url=page, callback=self.parse, dont_filter=False)
2. 自定义去重规则
1. 编写类DupeFilter
from scrapy.dupefilter import BaseDupeFilter from scrapy.utils.request import request_fingerprint class CustomizeDupeFilter(BaseDupeFilter): """ 自定义的url去重规则 :return: True表示已经访问过;False表示未访问过 """ def __init__(self): self.visited_fd = set() def request_seen(self, request): print('去重中') fd = request_fingerprint(request) # url的唯一标示 if fd in self.visited_fd: return True self.visited_fd.add(fd) def open(self): print('引擎开始///') def close(self, reason): print('引擎结束///')
2. 配置
DUPEFILTER_CLASS = 'scrapy_env.dupefilter.CustomizeDupeFilter'
3. 爬虫中
yield Request(url=page, callback=self.parse) # 默认是使用去重规则的
五. 控制爬虫爬取的url深度
1 配置文件中
DEPTH_LIMIT = 4 # 爬取深度为4的url
# 爬虫中看一下深度
print(response.meta.get('depth', 0))
六. cookie
方式一:手动携带cookie
import scrapy from scrapy.http.request import Request from scrapy.http.cookies import CookieJar class ChoutiSpider(scrapy.Spider): name = 'chouti' allowed_domains = ['chouti.com'] start_urls = ['http://chouti.com/'] cookie_dict = {} def parse(self, response): # 6.1 去响应头中获取cookie, 保存在cookie_jar对象中 cookie_jar = CookieJar() cookie_jar.extract_cookies(response, response.request) # 6.2 去cookie_jar对象中将cookie解析到字典中 for k, v in cookie_jar._cookies.items(): for i, j in v.items(): for m, n in j.items(): self.cookie_dict[m] = n.value print(self.cookie_dict) # 6.3 携带cookie去登录 yield Request(url='https://dig.chouti.com/login', method='post', headers={ 'content-type': 'application/x-www-form-urlencoded; charset=UTF-8' }, body='phone=8618648957737&password=/***/&oneMonth=1', cookies=self.cookie_dict, callback=self.check_result ) def check_result(self, response): print(response.text)
方式二:通过设置meta自动携带cookie
import scrapy from scrapy.http.request import Request class ChoutiSpider(scrapy.Spider): name = 'chouti' allowed_domains = ['chouti.com'] start_urls = ['http://chouti.com/'] def start_requests(self): url = 'http://dig.chouti.com/' # 1 设置了meta的cookiejar=True yield Request(url=url, callback=self.login, meta={'cookiejar': True}) def login(self, response): # print(response.headers.getlist('Set-Cookie')) yield Request( url='http://dig.chouti.com/login', method='POST', headers={'content-type': 'application/x-www-form-urlencoded; charset=UTF-8'}, body='phone=8618648957737&password=woshiniba&oneMonth=1', callback=self.check_result, meta={'cookiejar': True} # 2 会自动携带cookie过去 ) def check_result(self, response): print('检查结果') print(response.text)
七. scrapy设置代理
内置实现
1 环境变量设置
# 在爬虫启动时,提前在os.envrion中设置代理即可。 def start_requests(self): import os os.environ['HTTPS_PROXY'] = "http://root:woshiniba@192.168.11.11:9999/" os.environ['HTTP_PROXY'] = '19.11.2.32'
2 通过meta传参
# 粒度更细 yield Request(url=url,callback=self.parse,meta={'proxy':'"http://root:woshiniba@192.168.11.11:9999/"'})
自定义
3 通过自定义下载中间件
import base64 import random from six.moves.urllib.parse import unquote try: from urllib2 import _parse_proxy except ImportError: from urllib.request import _parse_proxy from six.moves.urllib.parse import urlunparse from scrapy.utils.python import to_bytes class XdbProxyMiddleware(object): def _basic_auth_header(self, username, password): user_pass = to_bytes( '%s:%s' % (unquote(username), unquote(password)), encoding='latin-1') return base64.b64encode(user_pass).strip() def process_request(self, request, spider): PROXIES = [ "http://root:woshiniba@192.168.11.11:9999/", "http://root:woshiniba@192.168.11.12:9999/", "http://root:woshiniba@192.168.11.13:9999/", "http://root:woshiniba@192.168.11.14:9999/", "http://root:woshiniba@192.168.11.15:9999/", "http://root:woshiniba@192.168.11.16:9999/", ] url = random.choice(PROXIES) orig_type = "" proxy_type, user, password, hostport = _parse_proxy(url) proxy_url = urlunparse((proxy_type or orig_type, hostport, '', '', '', '')) if user: creds = self._basic_auth_header(user, password) else: creds = None request.meta['proxy'] = proxy_url if creds: request.headers['Proxy-Authorization'] = b'Basic ' + creds
八. 中间件
爬虫中间件
# 应用: 深度,优先级
1. 写中间件
class SpiderMiddleware(object): def process_spider_input(self,response, spider): """ 下载完成,执行,然后交给parse处理 :param response: :param spider: :return: """ pass def process_spider_output(self,response, result, spider): """ spider处理完成,返回时调用 :param response: :param result: :param spider: :return: 必须返回包含 Request 或 Item 对象的可迭代对象(iterable) """ return result def process_spider_exception(self,response, exception, spider): """ 异常调用 :param response: :param exception: :param spider: :return: None,继续交给后续中间件处理异常;含 Response 或 Item 的可迭代对象(iterable),交给调度器或pipeline """ return None def process_start_requests(self,start_requests, spider): """ 爬虫启动时调用 :param start_requests: :param spider: :return: 包含 Request 对象的可迭代对象 """ return start_requests
2. 配置
SPIDER_MIDDLEWARES = { # 'xdb.middlewares.XdbSpiderMiddleware': 543, 'xdb.sd.Sd1': 666, 'xdb.sd.Sd2': 667, }
下载中间件
# 应用: 更换代理IP,更换Cookies,更换User-Agent,自动重试。
1. 写中间件
class DownMiddleware1(object): def process_request(self, request, spider): """ 请求需要被下载时,经过所有下载器中间件的process_request调用 :param request: :param spider: :return: None,继续后续中间件去下载; Response对象,停止process_request的执行,开始执行process_response Request对象,停止中间件的执行,将Request重新调度器 raise IgnoreRequest异常,停止process_request的执行,开始执行process_exception """ pass def process_response(self, request, response, spider): """ spider处理完成,返回时调用 :param response: :param result: :param spider: :return: Response 对象:转交给其他中间件process_response Request 对象:停止中间件,request会被重新调度下载 raise IgnoreRequest 异常:调用Request.errback """ print('response1') return response def process_exception(self, request, exception, spider): """ 当下载处理器(download handler)或 process_request() (下载中间件)抛出异常 :param response: :param exception: :param spider: :return: None:继续交给后续中间件处理异常; Response对象:停止后续process_exception方法 Request对象:停止中间件,request将会被重新调用下载 """ return None
2. 配置
DOWNLOADER_MIDDLEWARES = { #'xdb.middlewares.XdbDownloaderMiddleware': 543, # 'xdb.proxy.XdbProxyMiddleware':751, 'xdb.md.Md1':666, 'xdb.md.Md2':667, }
九. 执行脚本
1. 单爬虫运行
import sys from scrapy.cmdline import execute if __name__ == '__main__': execute(["scrapy","crawl","chouti","--nolog"])
2. 所有爬虫
a,在spiders同级创建任意目录,如:commands
b,在其中创建 crawlall.py 文件 (此处文件名就是自定义的命令)
from scrapy.commands import ScrapyCommand from scrapy.utils.project import get_project_settings class Command(ScrapyCommand): requires_project = True def syntax(self): return '[options]' def short_desc(self): return 'Runs all of the spiders' def run(self, args, opts): spider_list = self.crawler_process.spiders.list() for name in spider_list: self.crawler_process.crawl(name, **opts.__dict__) self.crawler_process.start()
c,在settings.py 中添加配置 COMMANDS_MODULE = '项目名称.目录名称'
d,在项目目录执行命令
scrapy crawlall
十. 自定义扩展
自定义扩展时,利用信号在指定位置注册制定操作
1. 自定义类
from scrapy import signals class MyExtension(object): def __init__(self, value): self.value = value @classmethod def from_crawler(cls, crawler): val = crawler.settings.getint('MMMM') ext = cls(val) crawler.signals.connect(ext.spider_opened, signal=signals.spider_opened) crawler.signals.connect(ext.spider_closed, signal=signals.spider_closed) return ext def spider_opened(self, spider): print('open') def spider_closed(self, spider): print('close')
2. 配置自定义扩展
EXTENSIONS = { # 'scrapy.extensions.telnet.TelnetConsole': None, 'xdb.ext.MyExtend': 666, }
十一. scrapy-redis
scrapy-redis是一个基于redis的scrapy组件,通过它可以快速实现简单分布式爬虫程序,该组件本质上提供的功能:
1. dupefilter - URL去重规则(被调度器使用)
2. scheduler - 调度器
3. pipeline - 数据持久化
4. 定制起始URL
URL去重规则的三个方案: (推荐方案3)
1. 完全自定义
from scrapy.dupefilters import BaseDupeFilter class DdbDuperFiler(BaseDupeFilter): """ 基于redis的去重: 1 完全自定义 """ def __init__(self): # 第一步: 连接redis self.conn = Redis(host='127.0.0.1', port='6379') def request_seen(self, request): """ 第二步: 检测当前请求是否已经被访问过 :return: True表示已经访问过;False表示未访问过 """ # 方式一 直接将url添加进集合中作为判断 # result = self.conn.sadd('urls', request.url) # if result == 1: # return False # return True # 方式二 先fingerprint再将url添加进集合中作为判断 fd = request_fingerprint(Request(url=request.url)) result = self.conn.sadd('urls', fd) if result == 1: return False return True
DUPEFILTER_CLASS = 'ddb.dup.DdbDuperFiler'
2. 使用scrapy-redis
# 连接方式1 # REDIS_HOST = '127.0.0.1' # REDIS_PORT = '6379' # REDIS_PARAMS = {'password':'beta'} # redis连接参数 # 连接方式2(优先级高于1) REDIS_URL = 'redis://127.0.0.1:6379' # 'redis://user:pass@hostname:9001' REDIS_ENCODING = 'utf-8' DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter' DUPEFILTER_KEY = 'dupefilter:%(timestamp)s' # 这是默认配置
3. 继承scrapy-redis并实现自定义
from scrapy_redis.connection import get_redis_from_settings from scrapy_redis.dupefilter import RFPDupeFilter from scrapy_redis import defaults class RedisDuperFiler(RFPDupeFilter): """ 基于redis_redis的去重: 3 实现自定义redis中存储的键的名字 """ @classmethod def from_settings(cls, settings): """Returns an instance from given settings. """ server = get_redis_from_settings(settings) # XXX: This creates one-time key. needed to support to use this # class as standalone dupefilter with scrapy's default scheduler # if scrapy passes spider on open() method this wouldn't be needed # TODO: Use SCRAPY_JOB env as default and fallback to timestamp. key = defaults.DUPEFILTER_KEY % {'timestamp': 'xiaodongbei'} debug = settings.getbool('DUPEFILTER_DEBUG') return cls(server, key=key, debug=debug)
REDIS_HOST = '127.0.0.1' REDIS_PORT = '6379' # REDIS_PARAMS = {'password':'beta'} # redis连接参数 REDIS_ENCODING = 'utf-8' DUPEFILTER_CLASS = 'ddb.dup.RedisDuperFiler' DUPEFILTER_KEY = 'dupefilter:%(timestamp)s' # 这是默认配置
调度器
# scrapy_redis为我们实现了配合Queue、DupFilter使用的调度器Scheduler
源码地址: from scrapy_redis.scheduler import Scheduler
# enqueue_request: 向调度器中添加任务
# next_request: 去调度器中获取一个任务
优先级队列时:
DEPTH_PRIORITY = 1 # 广度优先 DEPTH_PRIORITY = -1 # 深度优先
使用
# 1 连接redis配置 REDIS_HOST = '127.0.0.1' REDIS_PORT = '6379' REDIS_ENCODING = 'utf-8' # 2 去重的配置 DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter' # 3 调度器的配置 SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 调度器的其他配置 SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue' # 默认使用优先级队列(默认),其他:PriorityQueue(有序集合),FifoQueue(列表)、LifoQueue(列表) SCHEDULER_QUEUE_KEY = '%(spider)s:requests' # 调度器中请求存放在redis中的key SCHEDULER_SERIALIZER = "scrapy_redis.picklecompat" # 对保存到redis中的数据进行序列化,默认使用pickle SCHEDULER_PERSIST = True # 是否在关闭时候保留原来的调度器队列和去重记录,True=保留,False=清空(默认) SCHEDULER_FLUSH_ON_START = True # 是否在开始之前清空 调度器队列和去重记录,True=清空,False=不清空(默认) SCHEDULER_IDLE_BEFORE_CLOSE = 2 # 去调度器队列中获取数据时,如果为空,最多等待时间(最后没数据,未获取到)。 SCHEDULER_DUPEFILTER_KEY = '%(spider)s:dupefilter' # 去重规则,在redis中保存时对应的key SCHEDULER_DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter' # 去重规则对应处理的类
起始URL
a. 获取起始URL时,去集合中获取还是去列表中获取?True,集合;False,列表 REDIS_START_URLS_AS_SET = False # 获取起始URL时,如果为True,则使用self.server.spop;如果为False,则使用self.server.lpop b. 编写爬虫时,起始URL从redis的Key中获取 REDIS_START_URLS_KEY = '%(name)s:start_urls'

 浙公网安备 33010602011771号
浙公网安备 33010602011771号