MapReduce之自定义OutputFormat
@
OutputFormat接口实现类
OutputFormat是MapReduce输出的基类,所有实现MapReduce输出都实现了OutputFormat接口。下面介绍几种常见的OutputFormat实现类。
-
文本输出
TextoutputFormat
默认的输出格式是TextOutputFormat,它把每条记录写为文本行。它的键和值可以是任意类型,因为TextOutputFormat调用toString()方法把它们转换为字符串。 -
SequenceFileOutputFormat
将SecquenceFileOutputFormat输出作为后续MapReduce任务的输入,这便是一种好的输出格式,因为它的格式紧凑,很容易被压缩。 -
自定义OutputFormat
根据用户需求,自定义实现输出。
自定义OutputFormat使用场景及步骤
使用场景
- 为了实现控制最终文件的输出路径和输出格式,可以自定义OutputFormat。
例如:要在一个MapReduce程序中根据数据的不同输出两类结果到不同目录,这类灵活的输出需求可以通过自定义OutputFormat来实现。 - 自定义OutputFormat步骤
(1)自定义一个类继承FileOutputFormat。
(2)改写RecordWriter,具体改写输出数据的方法write()。
自定义OutputFormat 案例实操
需求
过滤输入的log日志,包含atguigu的网站输出到e:/atguigu.log,不包含atguigu的网站输出到e:/other.log。
输入数据

什么时候需要Reduce
①合并
②需要对数据排序
所以本案例不需要Reduce阶段,key-value不需要实现序列化
CustomOFMapper.java
public class CustomOFMapper extends Mapper<LongWritable, Text, String, NullWritable>{
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, String, NullWritable>.Context context) throws IOException, InterruptedException {
String content = value.toString();
//value不需要,但是不能用Null这个关键字,要使用NullWritable对象
context.write(content+"\r\n", NullWritable.get());
}
}
MyOutPutFormat.java
public class MyOutPutFormat extends FileOutputFormat<String, NullWritable>{
@Override
public RecordWriter<String, NullWritable> getRecordWriter(TaskAttemptContext job)
throws IOException, InterruptedException {
return new MyRecordWriter(job);//传递job对象,才能在RecordWriter中获取配置
}
}
MyRecordWriter.java
public class MyRecordWriter extends RecordWriter<String, NullWritable> {
private Path atguiguPath=new Path("e:/atguigu.log");
private Path otherPath=new Path("e:/other.log");
private FSDataOutputStream atguguOS ;
private FSDataOutputStream otherOS ;
private FileSystem fs;
private TaskAttemptContext context;
public MyRecordWriter(TaskAttemptContext job) throws IOException {
context=job;
Configuration conf = job.getConfiguration();
fs=FileSystem.get(conf);
atguiguOS = fs.create(atguiguPath);
otherOS = fs.create(otherPath);
}
// 将key-value写出到文件
@Override
public void write(String key, NullWritable value) throws IOException, InterruptedException {
if (key.contains("atguigu")) {
atguguOS.write(key.getBytes());//写到atguigu.log
//统计输出的含有atguigu字符串的key-value个数
context.getCounter("MyCounter", "atguiguCounter").increment(1);
}else {
otherOS.write(key.getBytes());//写到other.log
context.getCounter("MyCounter", "otherCounter").increment(1);
}
}
// 关闭流
@Override
public void close(TaskAttemptContext context) throws IOException, InterruptedException {
if (atguguOS != null) {
IOUtils.closeStream(atguguOS);
}
if (otherOS != null) {
IOUtils.closeStream(otherOS);
}
if (fs != null) {
fs.close();
}
}
}
CustomOFDriver.java
public class CustomOFDriver {
public static void main(String[] args) throws Exception {
Path inputPath=new Path("e:/mrinput/outputformat");
Path outputPath=new Path("e:/mroutput/outputformat");
//作为整个Job的配置
Configuration conf = new Configuration();
//保证输出目录不存在
FileSystem fs=FileSystem.get(conf);
if (fs.exists(outputPath)) {
fs.delete(outputPath, true);
}
// ①创建Job
Job job = Job.getInstance(conf);
//重点,设置为自定义的输出格式
job.setJarByClass(CustomOFDriver.class);
// ②设置Job
// 设置Job运行的Mapper,Reducer类型,Mapper,Reducer输出的key-value类型
job.setMapperClass(CustomOFMapper.class);
// 设置输入目录和输出目录
FileInputFormat.setInputPaths(job, inputPath);
FileOutputFormat.setOutputPath(job, outputPath);
// 设置输入和输出格式
job.setOutputFormatClass(MyOutPutFormat.class);
// 取消reduce阶段。设置为0,默认为1
job.setNumReduceTasks(0);
// ③运行Job
job.waitForCompletion(true);
}
}
输出文件:
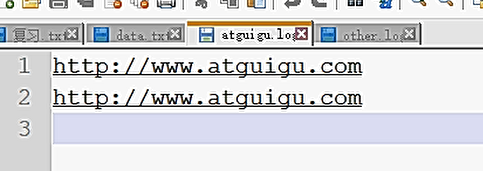
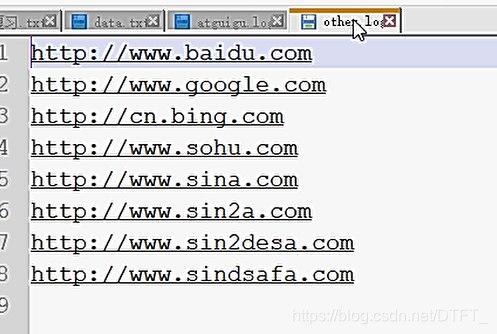
如果真的不知道做什么 那就做好眼前的事情吧 你所希望的事情都会慢慢实现...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号