MapReduce的常见输入格式之KeyValueTextInputFormat
有一文件,如图所示
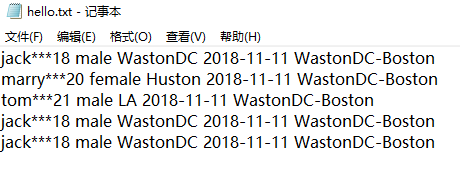
每行第一个字段为名字,后面的则为该人的一些信息,所以此时的输入格式应该是以每一行的名字为Key,每一行的其他信息为Value。
KeyValueTextInputFormat
-
作用: 针对文本文件!使用分割字符,分隔符前的为Key,分隔符后的为value,所以这种输入格式就是将每一行分割为key和value
-
如果没有找到分隔符,当前行的内容作为key,value为空串
-
默认分隔符为
\t,可以通过参数mapreduce.input.keyvaluelinerecordreader.key.value.separator指定分隔符切片:默认的切片策略,即一行切为一片
RecordReader:KeyValueLineRecordReader
它们的数据类型
Text key
Text value
在Driver.java中,提供了两种设置输入格式的方法:
①
job.setInputFormatClass(XXXInputFormat.class);
②
Configuration conf = new Configuration();
conf .set("mapreduce.job.inputformat.class", "org.apache.hadoop.mapreduce.lib.input.XXXTextInputFormat");
WCMapper.java
public class WCMapper extends Mapper<Text, Text, Text, IntWritable>{
private IntWritable out_value=new IntWritable(1);
@Override
protected void map(Text key, Text value, Mapper<Text, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
System.out.println("keyin:"+key+"----keyout:"+value);
context.write(key, out_value);
}
}
WCReducer.java
public class WCReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
private IntWritable out_value=new IntWritable();
// reduce一次处理一组数据,key相同的视为一组
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum=0;
for (IntWritable intWritable : values) {
sum+=intWritable.get();
}
out_value.set(sum);
//将累加的值写出
context.write(key, out_value);
}
}
WCDriver.java
public class WCDriver {
public static void main(String[] args) throws Exception {
Path inputPath=new Path("e:/mrinput/keyvalue");
Path outputPath=new Path("e:/mroutput/keyvalue");
//作为整个Job的配置
Configuration conf = new Configuration();
// 分隔符只是一个byte类型的数据,即便传入的是个字符串,只会取字符串的第一个字符
conf.set("mapreduce.input.keyvaluelinerecordreader.key.value.separator", "***");
//设置输入格式方法一
conf.set("mapreduce.job.inputformat.class", "org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat");
//保证输出目录不存在
FileSystem fs=FileSystem.get(conf);
if (fs.exists(outputPath)) {
fs.delete(outputPath, true);
}
// ①创建Job
Job job = Job.getInstance(conf);
job.setJarByClass(WCDriver.class);
// ②设置Job
// 设置Job运行的Mapper,Reducer类型,Mapper,Reducer输出的key-value类型
job.setMapperClass(WCMapper.class);
job.setReducerClass(WCReducer.class);
// Job需要根据Mapper和Reducer输出的Key-value类型准备序列化器,通过序列化器对输出的key-value进行序列化和反序列化
// 如果Mapper和Reducer输出的Key-value类型一致,直接设置Job最终的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 设置输入格式方法二
//job.setInputFormatClass(NLineInputFormat.class);
// 设置输入目录和输出目录
FileInputFormat.setInputPaths(job, inputPath);
FileOutputFormat.setOutputPath(job, outputPath);
// ③运行Job
job.waitForCompletion(true);
}
}
切片结果:

keyOut应该是value,此处写错了!
如果真的不知道做什么 那就做好眼前的事情吧 你所希望的事情都会慢慢实现...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号