【shell编程】awk语法
awk语法简介
是一个文本处理工具,用于逐行处理文本文件,任何awk语句都是由模式和动作组成,一个awk脚本可以有多个语句,模式决定动作语句的触发条件和触发时间。
1. 模式包含:正则表达式,/[正则表达式]/;关系运算符,<、<=、>、>=、!=、==;正则运算符,~(匹配)、!~(不匹配);赋值运算符,=、+=、-=、*=、/=、%=、**=;逻辑运算符||、&&;算术运算符+、-、*、/、++、--;其他运算符,$(用来对字段进行引用),空格(字符串连接符)。
2. 动作包含:变量、命令、内置函数、流程控制语句。
3. 语法:awk [选项] 'BEGIN{开始语句} 模式{动作} END{结束语句}' [文件]
其中BEGIN和END是awk的关键字,必须大写。不过开始模块和结束模块是可选部分,可以省略。并且开始语句和结束语句也是动作语句。另外,工作模块中的模式和动作可以都存在,也可以二者选其一。
- 如果省略模式,那么文件的所有行都执行动作;
- 如果省略动作,表示对符合条件的行执行默认的print动作。正因为可以二者选其一,所以一般用{}包裹动作,用于区分模式和动作。
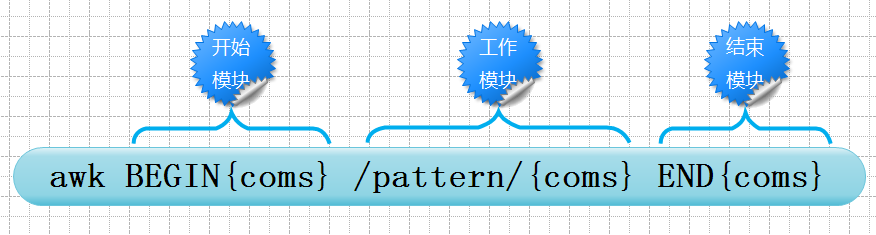
1. 特殊模块BEGIN和END
在awk中BEGIN和END都只能执行一次。BEGIN语句在动作语句之前执行,一般用于设置变量计数的起始值,打印头部信息和改变字段的分隔符。END语句在完成动作语句之后执行,一般用于输出统计结果,打印结尾信息。
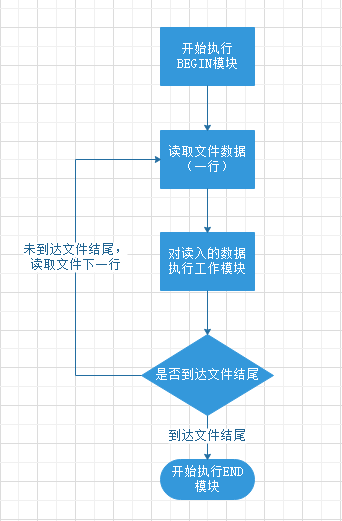
2. awk的执行过程(工作步骤)分为五个步骤:
- 第一步,执行BRGIN模块;
- 第二步,从文件、管道或标准输入中读取一行保存到内存中;
- 第三步,对读取的行数据执行工作模块;
- 第四步,判断是否到达文件、管道或标准输入的结尾,如果未到达结尾则重复第二步和第三步;
- 第五步,到达文件、管道或标准输入的结尾后,执行END模块。
图示执行过程如下:
[root@creditease awk]# awk '{a[$1]=a[$1]+$2}END{for(i in a)print i,a[i]}' jia.txt
a 4
b 8
c 2
d 7
f 6
g 2命令 awk '{b[$1]=b[$1]+$2}END{for(i in b)print i,b[i]}' jia.txt 使用了 AWK 工具来处理 jia.txt 文件的内容。让我们逐步解释这个命令:
-
{b[$1]=b[$1]+$2}:- 这部分命令使用了 AWK 的数组和循环功能。在 AWK 中,
b是一个关联数组,$1和$2分别代表当前处理行的第一个和第二个字段。 b[$1]表示以第一个字段$1的值作为索引,存储在数组b中。b[$1]=b[$1]+$2的意思是,如果数组b中已经有$1这个索引,就将当前行的第二个字段$2的值加到b[$1]中去;如果b[$1]还未定义,则会被初始化为0,然后加上$2的值。- 因此,对于每一行,这个命令都会根据第一个字段的值
$1来累加第二个字段$2的值到数组b的相应元素中。
- 这部分命令使用了 AWK 的数组和循环功能。在 AWK 中,
-
END{for(i in b)print i,b[i]}:END{}部分是 AWK 中的特殊块,在处理完所有行之后执行。for(i in b)循环遍历数组b的所有索引i。print i, b[i]打印每个索引i及其对应的值b[i],即每个字母和其累加后的数字总和。
解释 $1=a 时的情况:
当执行到 awk '{b[$1]=b[$1]+$2}END{for(i in b)print i,b[i]}' jia.txt 并且当前处理的行中 $1=a 时:
- 初始时
b[$1]是未定义的,即b[a]未初始化。 b[$1]=b[$1]+$2中的b[a]在第一次碰到a时会被初始化为0,然后加上当前行的$2的值。
举例来说,假设当前行是 a 1:
- 初始时
b[a]未定义,所以b[a]被初始化为0。 - 执行
b[a]=b[a]+$2,即b[a]=0+1,所以现在b[a]=1。
如果后续又碰到了 a 3:
- 现在
b[a]已经是1。 - 执行
b[a]=b[a]+$2,即b[a]=1+3,所以现在b[a]=4。
文件内容:
[node]
id = 1003
[numa]
mgmtd_main = []
storage_main = ["1:0", "2:1", "3:2", "4:03"]
meta_main = []代码示例:
read_numa_value() {
local file="$1"
local numa_key="$2"
awk -v key="${numa_key}" '
function trim(s) {
gsub(/^[[:space:]]+|[[:space:]]+$/, "", s)
return s
}
/^[[:space:]]*#/ || /^[[:space:]]*$/ { next }
/^[[:space:]]*\[/ {
section = $0
sub(/^[[:space:]]*\[/, "", section)
sub(/\][[:space:]]*$/, "", section)
section = trim(section)
next
}
section == "numa" {
line = $0
sub(/[[:space:]]*#.*/, "", line)
pattern = "^[[:space:]]*" key "[[:space:]]*="
if (line ~ pattern) {
sub(/^[^=]*=/, "", line)
print line
}
}
' "${file}" | tail -n 1
}
read_numa_value "node.toml" "storage_main"
解析:
判断是不是注释或空行 → 否
判断是不是 [xxx] 段标题 → 否
判断当前 section 是否等于 numa → 否
当前行处理结束
读取下一行
# 关键点是:每一行都会重新从第一条规则开始判断。
# 只有某条规则执行了: next
# 才会立即停止当前行后续规则的判断。
对一个文件名为qc.txt的文件进行去重处理,内容如下:
2018/10/20 xiaoli 13373305025
2018/10/25 xiaowang 17712215986
2018/11/01 xiaoliu 18615517895
2018/11/12 xiaoli 13373305025
2018/11/19 xiaozhao 15512013263
2018/11/26 xiaoliu 18615517895
2018/12/01 xiaoma 16965564525
2018/12/09 xiaowang 17712215986
2018/11/24 xiaozhao 15512013263实行命令:
# awk '!a[$2]++' qc.txt 说明:执行命令 awk '!a[$2]++' qc.txt 的作用是去除文件 qc.txt 中每个记录中第二列重复的行,只保留第一次出现的行。让我们来详细解释这个命令的执行过程和结果。
-
!a[$2]++解释:a[$2]表示以第二列$2的值作为索引,将其存储在数组a中。!a[$2]的逻辑是:如果a[$2]为假(即未定义或者为零),则取反后为真。a[$2]++表示对a[$2]的值进行自增操作,但是在自增之前使用了后缀自增运算符++,所以实际上!a[$2]++是在判断a[$2]的值,并在判断后自增。
-
操作过程:
- 对于每一行,在判断
!a[$2]++时,如果a[$2]尚未被设置(即第一次出现),!a[$2]将为真,条件成立。 - 所以,条件成立时,当前行会被输出(默认操作是打印整行)。
- 同时,
a[$2]会被设置为非零值,因为后缀自增操作符++会使a[$2]的值自增。
- 对于每一行,在判断
-
输出结果:
- 命令的输出是处理后的文件内容,只保留了第二列(即联系人姓名)第一次出现的行。
- 因此,输出结果是去除了重复联系人姓名的行,保留了每个联系人姓名第一次出现的行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号