【osd】peering基本概念
peering
1.1 acting set和up set
acting set是一个PG对应副本所在的OSD列表,该列表是有序的,列表中第一个OSD为主OSD。与up的区别在于,acting不是基于CRUSH计算出来的,而是基于一定的规则选出来;在通常情况下,up set和acting set列表完全相同。要理解他们的不同之处,需要理解下面介绍的“临时PG”概念。
1.2 临时PG
假设一个PG的acting set为[0,1,2]列表。此时如果osd0出现故障,导致CRUSH算法重新分配该PG的acting set为[3,1,2]。此时osd3为该PG的主OSD,但是osd3为新加入的OSD,并不能负担该PG上的读操作。所以PG向Monitor申请一个临时的PG,osd1为临时的主OSD,这时up set变为[1,3,2],acting set依然为[3,1,2],导致acting set和up set不同。当osd3完成Backfill过程之后,临时PG被取消,该PG的up set修复为acting set,此时acting set和up set都为[3,1,2]列表。
1.3 权威日志
权威日志(在代码里一般简写为olog)是一个PG的完整顺序且连续操作的日志记录。该日志将作为数据修复的依据。
1.4 up_thru
引入up_thru的概念是为了解决特殊情况: 当两个以上的OSD处于down状态,但是Monitor在两次epoch中检测到了这种状态,从而导致Monitor认为它们是先后宕掉。后宕的OSD有可能产生数据的更新,导致需要等待该OSD的修复,否则有可能产生数据丢失。
例10-1 up_thru处理过程
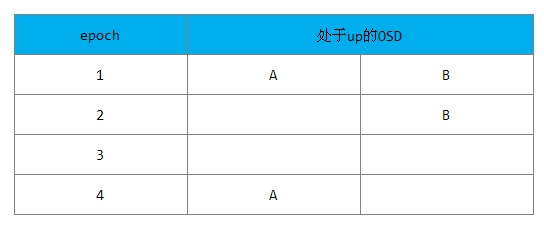
下图为初始情况:
过程如下所示:
1) 在epoch1时,一个PG中有A、B两个OSD(两个副本)都处于up状态。
2) 在epoch2时,Monitor检测到了A处于down状态,B仍然处于up状态。由于Monitor检测可能滞后,实际可能有两种情况:
-
情况1: 此时B其实也已经和A同时宕了,只是Monitor没有检测到。此时PG不可能完成Peering过程,PG没有新数据写入;
-
情况2: 此时B确实处于up状态,由于B上保持了完整的数据,PG可以完成Peering过程并处于active的状态,可以接受新的数据写操作;
上述两种不同的情况,Monitor无法区分。
3) 在epoch3时,Monitor检测到B也宕了。
4) 在epoch4时,A恢复了up的状态后,该PG发起Peering过程,该PG是否允许完成Peering过程处于active状态,可以接受读写操作?
-
如果在epoch2时,属于
情况1: PG并没有数据更新,B上不会新写入数据,A上的数据保存完整,此时PG可以完成Peering过程从而处于active状态,接受写操作; -
如果在epoch2时,属于
情况2: PG上有新数据更新到了osd B,此时osd A缺失一些数据,该PG不能完成Peering过程。
为了使Monitor能够区分上述两种情况,引入了up_thru的概念,up_thru记录了每个OSD完成Peering后的epoch值。其初始值设置为0。
在上述情况2,PG如何可以恢复为active状态,在Peering过程,须向Monitor发送消息,Monitor用数组up_thru[osd]来记录该OSD完成Peering后的epoch值。
注: OSD是通过OSD::send_alive()来向monitor报告up_thru信息的
当引入up_thru后,上述例子的处理过程如下:
情况1:
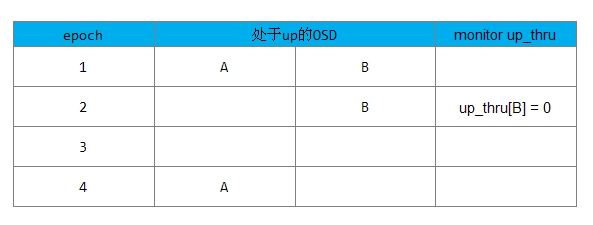
情况1的处理流程如下:
1) 在epoch1时,up_thru[B]为0,也就是说B在epoch为0时参与完成peering
2) 在epoch2时,Monitor检查到OSD A处于down状态,OSD B仍处于up状态(实际B已经处于down状态),PG没有完成Peering过程,不会向Monitor上报更新up_thru的值。
3) epoch3时,A和B两个OSD都宕了;
4) epoch4时,A恢复up状态,PG开始Peering过程,发现up_thru[B]为0,说明在epoch为2时没有更新操作,该PG可以完成Peering过程,PG处于active状态。
情况2:
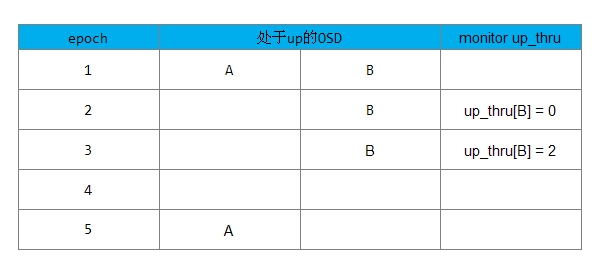
情况2的处理流程如下:
1) 在epoch1时,up_thru[B]为0,也就是说B在epoch为0时参与完成Peering过程;
2) 在epoch2时,Monitor检查到OSD A处于down状态,OSD B还处于up状态,该PG完成peering过程,向Monitor上报B的up_thru变为当前epoch的值为2,此时PG可接受写操作请求;
3)之后可能集群其他OSD宕了(图中没画出)导致epoch变为3,但此时up_thru[B]仍为2;
4) 在epoch4时,A和B都宕了,B的up_thru为2;
5) 在epoch5时,A处于up状态,开始Peering,发现up_thru[B]为2,说明在epoch为2时完成了Peering,有可能有更新操作,该PG需要等待B恢复。否则可能丢失B上更新的数据;
5.1 计算past_interval
past_interval是epoch的一个序列。在该序列内一个PG的acting set和up set不会变化。current_interval是一个特殊的past_interval,它是当前最新的一个没有变化的序列。示例如下:
说明如下:
1) Ceph系统当前的epoch值为20,PG1.0的acting set和up set都为列表[0,1,2];
2) osd3失效导致了osd map变化,epoch变为21;
3) osd5失效导致了osd map变化,epoch变为22;
4) osd6失效导致了osd map变化,epoch变为23;
上述3次epoch变化都不会改变PG1.0的acting set和up set。
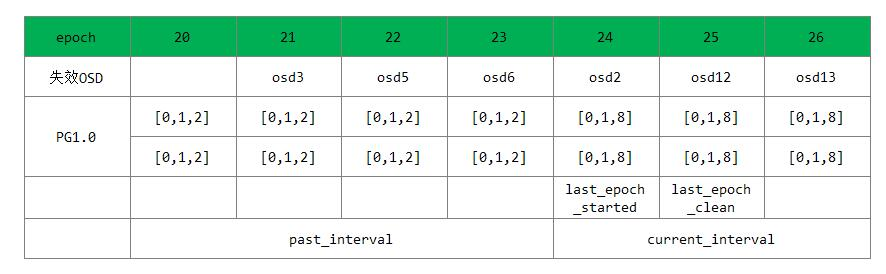
5) osd2失效导致了osd map变化,epoch变为24;此时导致PG1.0的acting set和up set变为[0,1,8],若此时Peering过程成功完成,则last_epoch_started为24。
6) osd12失效导致了osd map变化,epoch变为25,此时如果PG1.0完成了Recovery操作,处于clean状态,last_epoch_clean就为25;
7) osd13失效导致了osd map变化,epoch变为26。
epoch序列[20,21,22,23]就为PG1.0的一个past_interval,epoch序列[24,25,26]就为PG1.0的current_interval。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号