【osd】ceph中PGLog处理流程
struct pg_log_entry_t { ObjectModDesc mod_desc; //用于保存本地回滚的一些信息,用于EC模式下的回滚操作 bufferlist snaps; //克隆操作,用于记录当前对象的snap列表 hobject_t soid; //操作的对象 osd_reqid_t reqid; //请求唯一标识(caller + tid) vector<pair<osd_reqid_t, version_t> > extra_reqids; eversion_t version; //本次操作的版本 eversion_t prior_version; //前一个操作的版本 eversion_t reverting_to; //本次操作回退的版本(仅用于回滚操作) version_t user_version; //用户的版本号 utime_t mtime; //用户的本地时间 __s32 op; //操作的类型 bool invalid_hash; // only when decoding sobject_t based entries bool invalid_pool; // only when decoding pool-less hobject based entries ... };
/** * pg_info_t - summary of PG statistics. * * some notes: * - last_complete implies we have all objects that existed as of that * stamp, OR a newer object, OR have already applied a later delete. * - if last_complete >= log.bottom, then we know pg contents thru log.head. * otherwise, we have no idea what the pg is supposed to contain. */ struct pg_info_t { spg_t pgid; //对应的PG ID //PG内最近一次更新的对象的版本,还没有在所有OSD上完成更新。在last_update和last_complete之间的操作表示 //该操作已在部分OSD上完成,但是还没有全部完成。 eversion_t last_update; eversion_t last_complete; //该指针之前的版本都已经在所有的OSD上完成更新(只表示内存更新完成) epoch_t last_epoch_started; //本PG在启动时候的epoch值 version_t last_user_version; //最后更新的user object的版本号 eversion_t log_tail; //用于记录日志的尾部版本 //上一次backfill操作的对象指针。如果该OSD的Backfill操作没有完成,那么[last_bakfill, last_complete)之间的对象可能 //处于missing状态 hobject_t last_backfill; bool last_backfill_bitwise; //true if last_backfill reflects a bitwise (vs nibblewise) sort interval_set<snapid_t> purged_snaps; //PG要删除的snap集合 pg_stat_t stats; //PG的统计信息 pg_history_t history; //用于保存最近一次PG peering获取到的epoch等相关信息 pg_hit_set_history_t hit_set; //这是Cache Tier用的hit_set };
下面简单画出三者之间的关系示意图:

其中:
-
last_complete: 在该指针
之前的版本都已经在所有的OSD上完成更新(只表示内存更新完成); -
last_update: PG内最近一次更新的对象的版本,还没有在所有OSD上完成更新。在last_update与last_complete之间的操作表示该操作已在部分OSD上完成,但是还没有全部完成。
-
log_tail: 指向pg log最老的那条记录;
-
head: 最新的pg log记录
-
tail: 指向最老的pg log记录的前一个;
-
log: 存放实际的pglog记录的list
从上面结构可以得知,PGLog里只有对象更新操作相关的内容,没有具体的数据以及偏移大小等,所以后续以PGLog来进行恢复时都是按照整个对象来进行恢复的(默认对象大小是4MB)。
另外,这里再介绍两个概念:
- epoch是一个单调递增序列,其序列由monitor负责维护,当集群中的配置及OSD状态(up、down、in、out)发生变更时,其数值加1。这一机制等同于时间轴,每次序列变化是时间轴上的点。这里说的epoch是针对OSD的,具体到PG时,即对于每个PG的版本eversion中的epoch的变化并不是跟随集群epoch变化的,而是当前PG所在OSD的状态变化,当前PG的epoch才会发生变化。
如下图所示:
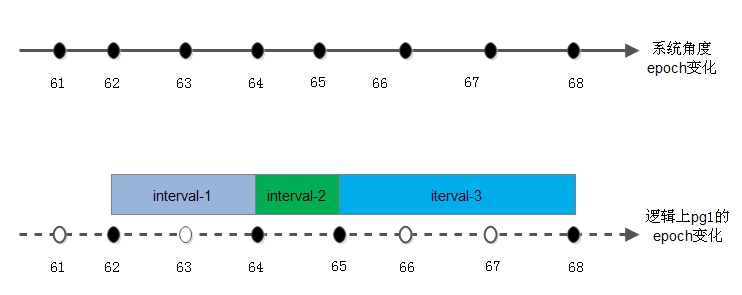
- 根据epoch增长的概念,即引入第二个重要概念interval
因为pg的epoch在其变化的时间轴上并非是完全连续的,所以在每两个变化的pg epoch所经历的时间段我们称之为intervals。
3.1.3 Trim Log
void PrimaryLogPG::execute_ctx(OpContext *ctx) { ...... // trim log? if (hard_limit_pglog()) calc_trim_to_aggressive(); else calc_trim_to(); ...... }
前面说到PGLog的记录数是有限制的,正常情况下默认是3000条(由参数osd_min_pg_log_entries控制),PG降级情况下默认增加到10000条(由参数osd_max_pg_log_entries)。当达到限制时,就会trim log进行截断。
在ReplicatedPG::execute_ctx()里调用ReplicatedPG::calc_trim_to()来进行计算。计算的时候从log的tail(tail指向最老的记录的前一个)开始,需要trim的条数为log.head - log.tail - max_entries。但是trim的时候需要考虑到min_last_complete_ondisk(这个表示各个副本上last_complete的最小版本,是主OSD在收到3个副本都完成时再进行计算的,也就是计算last_complete_ondisk和其他副本OSD上的last_complete_ondisk,即peer_last_complete_ondisk的最小值得到min_last_complete_ondisk),也就是说trim的时候不能超过min_last_complete_ondisk,因为超过了也trim掉的话就会导致没有更新到磁盘上的pg log丢失。所以说可能存在某个时刻,pglog的记录数超过max_entries。例如:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号