C++基础3
C++ 基础3
typedef
为现有类型创建一个新名字
主要有以下几种形式:
- 为基本数据类型定义别名
- 为指针定义别名
- 为自定义数据类型定义别名
- 为数组定义别名
- 声明函数
定义新名称为了简化一些复杂的数据类型,以方便使用
为基本数据类型定义名称
语法typedef 旧类型 新名字
例如:
typedef int I;
int main()
{
I i = 10; //等同于 int i=10;
}
为指针定义名称
typedef int* I_P;
int main()
{
int a = 10;
I_P a_p= &a; //等同于int *a_p = &a;
}
还有一个在刚开始学c++容易犯的错误,如下代码其实是定义了一个int指针类型的a 一个int类型的b
int main()
{
int* a, b;
}
可以用typedef来解决这种问题,如下,这样就是定义两个int指针类型的变量了
typedef int* I_P;
int main()
{
I_P a,b;
}
为自定义数据类型定义名称
在一些旧的c代码中,使用结构体必须带上struct关键字,如下
struct User {
int age;
string name;
};
int main()
{
struct User user = { 1,"" };
}
可以使用typedef来定义为User,这样就不用再写struct关键字了
typedef struct User {
int age;
string name;
};
int main()
{
User user = { 1,"" };
}
还有另一种方式来定义-把结构体名称放到后面,这两者是一样的
typedef struct {
int age;
string name;
} User;
int main()
{
User user = { 1,"" };
}
结构体和typedef组合容易搞错的地方
例1:
typedef struct {
int age;
string name;
} u;
struct People {
int age;
string name;
} p;
int main() {
u u1;
u1.age;
p.age;
}
请注意,以上代码u是别名,而p是变量! 当结构体前面存在typedef的时候,结尾}后面的是别名
例2:
以下代码声明了一个Node结构体,现在我们使用Node或np都可以来创建对象
typedef struct Node{
Node* prev;
} np;
int main()
{
Node n;
n.prev;
np n2;
n2.prev;
}
但是当我们修改代码如下后
typedef struct Node {
Node* prev;
} *np;
是不是有点蒙,其实分为两步
第一步创建一个Node结构体
struct Node {
Node* prev;
}
第二步给这个Node指针声明别名
typedef Node* np;
也就是说如下两个代码效果是一样的
struct Node {
Node* prev;
} ;
typedef Node* np;
typedef struct Node {
Node* prev;
} *np;
那我们能不能使用np来代替Node结构体中的Node*呢?类似这样
typedef struct Node {
np prev;
} *np;
结果不可以,原因其实刚刚说过,因为它是先定义的Node结构体,再去声明的np别名,
在定义Node结构体的时候np别名并不存在,所以编译不通过
为数组定义名称
typedef int INT_ARRAY_10[10];
int main()
{
INT_ARRAY_10 a; //等同于 int a[10]
a[0] = 1;
}
声明函数
typedef int F(); 定义了一个返回值为int 无参的函数
typedef char* T(double* d); 定义了一个返回为char* ,形参为double* d的函数
typedef int F();
typedef char* T(double* d);
class User {
public:
F(add);
T(update);
};
char* User::update(double* d) {
return new char('2');
}
int User::add() {
cout << "add!";
return 100;
}
int main(){
User u;
u.add();
double a = 3.45;
u.update(&a);
}
typedef模板
typedef没有办法直接使用模板,只能在外层套一个struct
template <typename T>
struct Vec {
typedef vector<T> v;
};
int main() {
Vec<int>::v v1;
v1.push_back(10);
}
typedef是为类型添加一个新的名称,并没有创建一个类型
typedef和#define的区别
#define是预处理指令,在编译预处理时进行字符替换,并不会做任何额外的处理
而typedef是在编译时处理的,在自己的作用域内给一个已经存在的类型一个别名
using
命名空间声明
例如最常见的输出cout
#include <iostream>
using namespace std;
int main()
{
cout;
}
如果没有引入的话就需要单独指定
#include <iostream>
int main()
{
std::cout;
}
修改父类访问权限
class Animal {
protected:
int a;
int b;
void e() {
}
void f() {
}
};
class Cat : public Animal{
};
int main()
{
Cat c;
c.a; //报错,没有权限访问-以下都是这个错误
c.b;
c.e();
c.f();
}
如上的代码因为Animal使用的是protected权限,只能子类内部访问,这时我们可以使用using来修改权限
class Animal {
protected:
int a;
int b;
void e() {
}
void f() {
}
};
class Cat : public Animal{
public:
//在当前域引入父类的保护成员,使在类外依然可以访问到
using Animal::a;
//引入函数
using Animal::e;
};
int main()
{
Cat c;
c.a; //正常
c.b; //报错-没有权限
c.e(); //正常
c.f(); //报错-没有权限
}
类型重定义
语法using 别名=原类型
using ui = unsigned int;
int main()
{
ui i = 100;
}
和typedef类似,以下代码中两者是等价的
using a = int;
typedef int b;
int main() {
a i1 = 100;
b i2 = 100;
}
但是在使用模板上,using会更方便一些
using模板
template<typename T>
using Vec = vector<T>;
int main() {
Vec<int> v;
v.push_back(100);
}
对比typedef使用模板
template <typename T>
struct Vec {
typedef vector<T> v;
};
int main() {
Vec<int>::v v1;
v1.push_back(10);
}
异常
一种处理错误的方式,捕捉一些可能出现的错误不至于让程序崩溃
例如下面的这个例子,a方法用于返回两个数相除的结果,但是当入参为1,0的时候,就会出现1/0的经典错误
int a(int a, int b) {
return a / b;
}
int main()
{
a(1, 0);
}
如果使用if判断该如何告诉调用者main函数这个错误呢?返回-1?返回0?这些都有可能是正常的计算结果,这时就可以使用到异常了
语法:
throw xxx; 抛出一个异常
try
{
// 保护的标识代码
}catch( ExceptionName e1 ){
//e1的错误处理方式
}
catch( ExceptionName e2 ){
//e2的错误处理方式
}
修改上面的代码为:
int a(int a, int b) {
if (b == 0) {
throw "除数不能为0!";
}
return a / b;
}
int main()
{
try{
a(1, 0);
}
//指明是一个string类型的异常
catch (const char* errorInfo) {
cout << errorInfo << endl;
}
}
当异常除数为0的时候将给用户提示,而不是程序直接崩溃
多个catch
还可以存在多个catch,如下
int a(int b) {
if (b == 0) {
throw "字符串类型异常!";
}
if (b == 1) {
//double类型异常
throw 1.1;
}
if (b == 2) {
//int类型异常
throw 1;
}
if (b == 3) {
//指针类异常
throw & b;
}
return 0;
}
int main()
{
try{
a(1);
}
catch (const char* errorInfo) {
cout << "string";
cout << errorInfo << endl;
}
catch (int errorInfo) {
cout << "int";
cout << errorInfo << endl;
}
catch (double errorInfo) {
cout << "double";
cout << errorInfo << endl;
}
catch (int* errorInfo) {
cout << "指针-地址";
cout << errorInfo << endl;
}
}
异常的类型会依次寻找catch的入参类型,如果匹配则进入对应的catch
兜底catch
当程序出现了我们可能想不到的异常,但是我们并不想让程序直接崩溃而是给个友好的提示,这时就可以用到兜底的catch
下面的代码当a函数的入参为1时,a函数将抛出一个1.1 double类型的异常,但是在main函数中并没有存在catch(double)类型的异常处理,最后就会进入catch (...)中
int a(int b) {
if (b == 0) {
throw "字符串类型异常!";
}
if (b == 1) {
//double类型异常
throw 1.1;
}
return 0;
}
int main()
{
try{
a(0);
}
catch (const char* errorInfo) {
cout << "string";
cout << errorInfo << endl;
}
catch (...) {
cout << "程序出错啦!";
}
}
当兜底异常处理和对应类型的异常处理同时存在时,异常只会进入对应类型的异常处理中
上面的代码中当a函数的入参为0时,只会走catch (const char* errorMessage)的异常处理,然后程序结束
异常类型捕获
下面的代码中a函数入参为0时将抛出一个int类型的异常,而在main函数中异常处理并没有int类型的catch
但是我们在代码中int是可以直接转换为double类型的
那么下面的代码是进入double的异常处理还是兜底的异常处理呢?
int a(int b) {
if (b == 0) {
//int类型异常
throw 1;
}
return 0;
}
int main()
{
try{
a(0);
}
catch (double errorInfo) {
cout << "double";
cout << errorInfo << endl;
}
catch (...) {
cout << "程序出错啦!";
}
}
结果是进入兜底的异常处理,catch并不对异常类型会进行转换
代码中也可以将异常继续抛出,如下代码
void b() {
throw 1;
}
void a() {
try {
b();
}
catch (int err) {
cout << "捕获了一个异常";
//do something...
throw err;
}
}
int main()
{
try {
a();
}catch (int err) {
cout << "调用a函数异常";
throw err;
}
}
声明可能存在的异常
当我们一个函数中可能会抛出一个异常的时候,我们一般在函数上标识可能抛出的异常类型
声明a函数可能会抛出一个int类型的异常
void a(int b) throw (int) {
if (b == 1) {
throw 1;
}
}
如果可能抛出多个异常,代码如下
则声明了a函数可能会抛出int或double类型的异常
void a(int b) throw (int,double) {
if (b == 1) {
throw 1;
}
else if (b == 2) {
throw 1.1;
}
}
如果函数不会抛出异常,则可以声明为throw()
void a(int b) throw () {
}
自定义异常类型
为什么需要自定义异常类型呢?例如如下代码.因为两个异常都是字符串类型的,我们无法根据异常类型匹配业务的错误
void a(int b) throw (int, double) {
if (b == 1) {
throw "参数错误";
}
else if (b == 2) {
throw "账号错误";
}
}
自定义一个异常类型和定义一个普通的类区别不是大,代码如下
先定义一个自定义的异常
class MyException {
public:
MyException(int _errCode, string _errInfo) :errCode(_errCode), errInfo(_errInfo) {};
int errCode;
string errInfo;
};
void a(int i) throw (MyException) {
if (i == 1) {
throw MyException(1, "业务错误");
}
else if (i == 2) {
throw MyException(2, "账号错误");
}
}
int main()
{
try {
a(1);
}
catch (MyException& e) {
if (e.errCode == 1) {
//do something...
}
else if (e.errCode == 2) {
//do something...
}
cout << e.errInfo << endl;
}
catch (...) {
cout << "程序出错啦!";
}
}
我们也可以继续定义子类,更加细分业务异常
class MyException {
public:
MyException() {};
MyException(int _errCode, string _errInfo) :errCode(_errCode), errInfo(_errInfo) {};
int errCode;
string errInfo;
};
class SqlException : public MyException {
public:
SqlException(int _errCode, string _errInfo) {
errCode = _errCode;
errInfo = _errInfo;
};
};
class UserException : public MyException {
public:
UserException(int _errCode, string _errInfo) {
errCode = _errCode;
errInfo = _errInfo;
};
};
void a(int i) throw (MyException) {
if (i == 1) {
throw SqlException(1, "业务错误");
}
else if (i == 2) {
throw UserException(2, "账号错误");
}
else if (i == 3) {
throw MyException(3, "非法参数");
}
}
int main()
{
try {
a(1);
}
catch (SqlException& e) {
//do something...
}
catch (UserException& e) {
//do something...
}
catch (MyException& e) {
cout << e.errInfo << endl;
cout << e.errCode << endl;
//do something...
}
catch (...) {
cout << "程序出错啦!";
}
}
如果抛出的是子类异常,是会进入父类的异常处理, 如果子类异常处理和父类异常处理同时存在,则走子类的异常处理
如果抛出的是父类异常,却不会进入子类的异常处理
注意:尽量不要在构造和析构中抛出异常
Lambda
作用就是一个语法糖,简化代码,例如sort()函数中我们自定义一个排序
class my_sort {
public:
bool operator()(int& a,int& b) {
return a > b;
}
};
void print(int a) {
cout << a << endl;
}
int main()
{
vector<int> v;
v.push_back(3);
v.push_back(1);
v.push_back(2);
v.push_back(4);
sort(v.begin(), v.end(), my_sort());
for_each(v.begin(), v.end(), print);
}
当然基础数据类型的排序在STL中都有现成的函数,这里只是为了介绍lambda做演示
当我们需要自定义一个排序规则时就需要实现一个例如上面的一个伪函数,或者一个普通的函数,如下
bool my_sort(int& a, int& b) {
return a > b;
}
void print(int a) {
cout << a << endl;
}
int main()
{
vector<int> v;
v.push_back(3);
v.push_back(1);
v.push_back(2);
v.push_back(4);
sort(v.begin(), v.end(), my_sort);
for_each(v.begin(), v.end(), print);
}
而使用lambda就可以直接去编写排序的规则,不用再去封装一个伪函数或普通函数,如``下
int main()
{
vector<int> v;
v.push_back(3);
v.push_back(1);
v.push_back(2);
v.push_back(4);
sort(v.begin(), v.end(), [](int& a, int& b) {return a > b; });
for_each(v.begin(), v.end(), print);
}
而这里[](int& a, int& b) {return a > b; });就是lambda表达式
语法:[] () mutable throw() -> return type {}
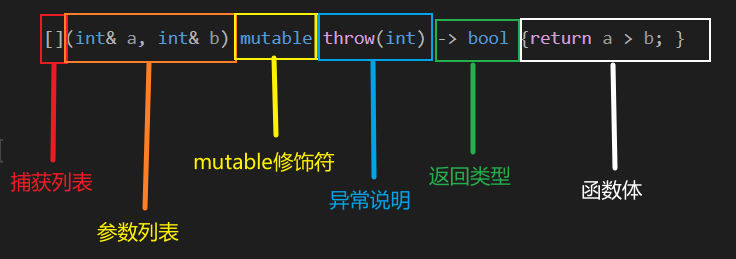
整体介绍
- 捕获列表 用于在函数体中使用当前lambda所在上下文的其他变量
- 列表参数可省略 lambda函数的形参
- mutable修饰符可省略 注意!如果添加了mutable,那么参数列表必须加上,即使没有参数 默认lambda函数总是const 函数,mutable可以取消lambda的常量性
- 异常说明可省略 lambda可能会抛出的异常
- 返回类型可省略 标识lambda返回的数据类型
- 函数体 lambda具体执行的代码
一个最基础的lambda函数长这样
这表示一个没有任何捕获列表,无参无返的一个空函数,下面来具体介绍
[]{}
捕获列表
[] 不获取任何变量,也就是说能在lambda函数体中使用的变量只有在函数体中定义的和形参的变量
下面的void (*a)()是一个名为a函数指针,如果您不懂的话没关系,先当成类似于int* a的指针变量即可
之后就可以通过a();来调用这个lambda
因为在lambda中存在函数指针的使用情况,而在函数指针中又存在使用lambda的情况
两者互相依赖,无论先学那个都有一个不懂,这篇文章下一节就是介绍函数指针,可以等看完函数指针后,在回头研究这个void (*a)()
int main()
{
void (*a)() = []() {
cout << "芜湖!";
};
a();
}
[var] 表示以值传递的方式捕获变量var
这里有个疑惑,当我捕捉age后就无法继续赋值给void(*a),如果您知道的原因的话希望不吝赐教
这里先使用auto指针吧,这里有篇文章,将捕获变量的lambda赋值给函数指针,可以参考一下
int main()
{
int age = 100;
//注意这里并不是方法传参
auto f= [age]() {
cout << "芜湖!年龄为:"<<age;
};
f();
}
[=] 值传递获取父作用域下的所有变量,包括this
int main()
{
int age = 100;
string name = "hh";
auto f = [=] {
cout << name<<"age:"<<age << endl;;
};
f();
}
[&var] 使用引用的方式捕获变量var
当去掉&后就会走拷贝构造,说明是值传递
class User {
public:
User() {
cout << "created";
}
User(const User& u) {
age = u.age;
cout << "拷贝";
}
int age;
};
void a(User u) {
u.age = 200;
}
int main()
{
User u;
u.age = 100;
auto f = [u] {
cout << "u.age:" + u.age;
};
f();
}
[&] 以引用的方式捕获父作用域的变量,包括this
代码和上面基本一致,修改main函数为如下
int main()
{
User u;
u.age = 100;
int a = 100;
auto f = [&] {
cout << "u.age:" + u.age;
cout << a << endl;
};
f();
}
[this] 获取当前位置的this指针
而this指针只能存在于非静态成员函数内部,也就变相限制了lambda使用[this]的位置
需要注意的是this指针比较特殊,通过[=]或[&]获取的this指针并没有区别,都是指向当前对象
class User {
public:
void t() {
auto fun = [this] {
this->sayHello();
};
fun();
}
void sayHello() {
cout << "hello!" << endl;
}
};
int main(){
User u ;
u.t();
}
[=,&]混合使用
例如[=,&v1,&v2] 表示以引用的方式捕获v1,v2变量,其他变量以值传递方式,例如下面
您可能注意到了,这里的lambda使用了mutable关键字,并且在mutable前面还有一个() 后面会详细介绍mutable
因为lambda捕获的任何变量都默认const修饰的,无法进行修改,所以添加了一个mutable
int main(){
int a = 10;
int b = 10;
int c = 10;
auto f = [=, &a, &b]() mutable {
a = 20;
b = 20;
c = 20;
};
f();
cout << "a:" << a << endl;
cout << "b:" << b << endl;
cout << "c:" << c << endl;
}
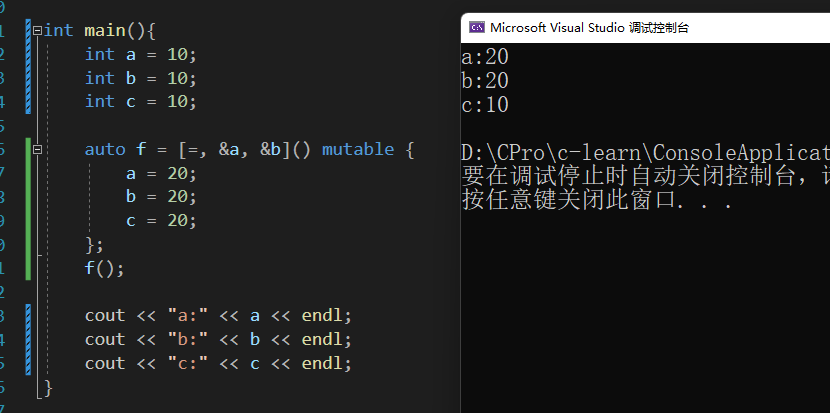
因为使用的= 以值传递的方式捕获的c变量 所以在lambda中修改c的值并不会影响main函数中的c
[&,v1] 以值传递方式捕获v1,以引用方式捕获其他变量
int main() {
int a = 10;
int b = 10;
auto f = [&, b]() mutable {
a = 20;
b = 20;
};
f();
cout << "a:" << a << endl;
cout << "b:" << b << endl;
}
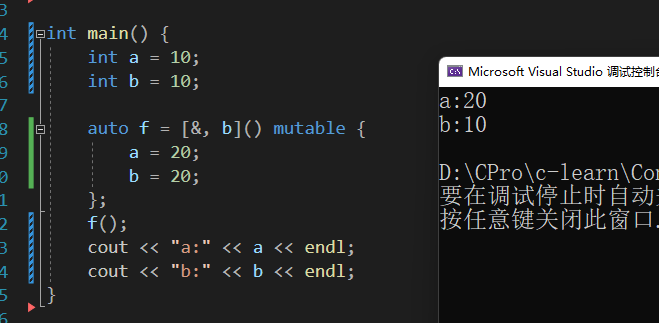
需要注意的时lambda不允许重复捕获
例如下面的例子,第一个[&]已经捕获到b变量了,不需要再次捕获,或者[=,b] 这种也是错误的重复捕获
int main() {
int a = 10;
int b = 10;
auto f = [&,&b]() mutable {
a = 20;
b = 20;
};
}
参数列表
和普通的函数形参一样,如果声明存在形参,则在调用函数时需要传入参数
int main() {
auto f = [](int a,int b) {
a = 20;
b = 20;
};
f(1, 2);
}
mutable
默认情况下lambda是一个const函数,当使用mutable修饰lambda时,参数列表不允许省略
例如如下代码将会编译错误,因为lambda值传递方式捕获变量默认为const
int main() {
int a = 10;
auto f = [a] {
a = 20;
};
f();
cout << a << endl;
}
这时我们就可以用给函数添加一个mutable修饰,去除变量a的const
当使用mutable修饰lambda时,参数列表不能为空,即使没有入参
int main() {
int a = 10;
auto f = [a]()mutable {
a = 20;
};
f();
cout << a << endl;
}
但是这么做是没有意义的,因为是值传递的a,修改并不会改变原有的数据
异常说明
和普通函数一样,声明这个lambda函数可能抛出的异常,如果不会抛出异常,可以使用throw()来标明
当使用throw()声明后,即使该lambda没有参数也不能省略参数列表
int main() {
int a = 10;
auto f = [&a]() throw() {
a = 20;
};
f();
cout << a << endl;
}
可能抛出int类型的异常
int main() {
int a = 10;
auto f = [&a]() throw(int) {
if (a == 1) {
throw 1;
}
};
f();
cout << a << endl;
}
返回类型
lambda表达式会自动推导返回类型,根据return的返回类型来推断lambda的返回类型
当指定返回类型后参数列表不能省略,即使入参为空
int main() {
int a = 10;
auto f=[]() -> int {
return 1;
};
//和上面f一样
auto f2=[]{
return 1;
};
}
函数体
类似于普通函数的函数体,在函数体内能使用的变量如下
- 捕获的变量
- 形参变量
- 局部声明的变量
- 类成员函数/变量,当在类内声明
this并被捕获时 - 全局变量,全局静态变量和局部静态变量
捕获的变量
int main() {
int a = 10;
auto f=[&a]{
a++;
};
f();
}
形参变量
int main() {
int a = 10;
auto f=[](int& a) {
a++;
};
f(a);
}
局部声明的变量
int main() {
auto f=[] {
int b = 10;
b++;
};
b++; //报错,因为超出了b的作用范围,只存在于lambda中
f();
}
类成员函数/变量,当在类内声明this并被捕获时
以下代码中age的作用是相等的
class A {
public:
int age;
void test() {
[this]() {
age += 5;
this->age += 5;
auto t = this;
t->age += 5;
}(); //声明同时调用
}
};
int main() {
A a = { 0 };
a.test();
cout << a.age;
}
全局变量,全局静态变量和局部静态变量
static int a = 10;
int c = 10;
int main() {
static int b = 10;
[] {
a = 20;
b = 20;
c = 20;
}();
cout << a << endl;
cout << b << endl;
cout << c << endl;
}
函数指针
使用指针来指向函数,可以通过函数指针来调用函数,本质是指向函数中代码的首地址
声明语法: 函数返回值类型 (*函数指针变量名称)(函数入参...)
例如:
#include <iostream>
using namespace std;
//定义一个函数a
int a() {
cout << "aughhh";
return 1;
}
//声明一个函数指针
int (*a_function_p)();
int main()
{
//将函数指针指向函数a
a_function_p = &a;
//通过函数指针调用函数a
a_function_p();
}
还有一种写法,不加&,这种写法好像是为了兼容性
a_function_p = a;
当然也可以在声明时直接赋值函数
int (*a_function_p)() = a;
在c中调用函数指针指向的函数和c++中不同
int main()
{
a_function_p(); // c++
(*a_function_p)(); // c/c++
}
需要注意的是声明函数指针不能省略函数名的括号
如果省略括号编译器就认为是声明一个 返回类型为int* 无参的函数了,例如
int main()
{
//定义一个函数指针
int (*a_function_p)();
//使用函数指针调用函数
a_function_p();
//声明一个函数,返回类型为int*
int* b_function_p();
//普通函数调用
b_function_p();
}
而且在ide中也会有提示,明显两者颜色不一样
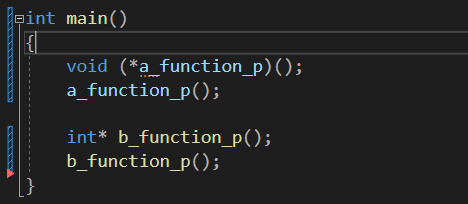
小插曲: 当时我想如果在函数内定义函数,该如何编写函数实现呢? 在函数外任意位置即可
如果是想要提前使用函数,那么需要调用的函数肯定在当前函数之后,在之前就没必要再声明了
函数指针作为函数入参
int a(int (*b_fp)()) {
return b_fp() + 100;
}
int b() {
return 100;
}
int main()
{
//声明同时初始化函数指针
int (*b_fp)() = b;
//将函数指针作为参数传递给a函数
int result = a(b_fp);
cout << result;
}
使用函数指针调用函数a
int a(int (*b_fp)()) {
return b_fp() + 100;
}
int b() {
return 100;
}
int main()
{
//创建一个函数指针,指向b
int (*b_fp)() = b;
//创建一个函数指针,指向a
int(*a_fp)(int (*b_fp)()) = a;
//通过函数指针调用a
int result = a(b_fp);
cout << result;
}
emm可能有点绕int(*a_fp)(int (*b_fp)()) 首先int后第一个括号是声明这个a函数指针的名称,第二个是函数的入参,只不过入参也是一个函数指针
函数指针作为返回值
一个普通的函数长这个样子
void a(){
}
按道理来说如果返回的是一个函数指针,那应该是这样的
(*b_fp)() a(){
}
但并不是这样的,而是这样的
void b() {
}
void (* a())() {
void (*b_fp)() = b;
return b_fp;
}
语法:函数指针的返回值 (* 当前函数名称(当前函数的入参...))(函数指针的入参...)
emm已经很绕了,调用这个函数如下
int main()
{
void (*(*a_function_p)())() = a;
void (*b_function_p)() = a_function_p();
b_function_p();
}
能看到如果是返回函数指针的函数,比定义函数指针多了一个(*)包裹住前面和最后一个多了个()
当然了估计这种用的很少,还有返回函数指针的函数还返回函数指针..那就更乱了
使用typedef简化函数指针
例如上面的返回函数指针的函数,我们就可以使用typedef来简化
typedef void (*f_p)(); f_p 就代替了一个无返无参的函数指针
typedef void (*f_p)();
//使用using也可以 两者相同
//using f_p = void (*)();
void b() {
cout << "芜湖!" << endl;
}
//那么这里意思就是a函数返回一个无参无返的函数指针
f_p a() {
void (*b_fp)() = b;
return b_fp;
}
int main()
{
void (*(*a_function_p)())() = a;
void (*b_function_p)() = a_function_p();
b_function_p();
}
a方法明显能看懂了,那么下面main中也可以简化一下
typedef void (*f_p)();
//using f_p = void (*)();
void b() {
cout << "芜湖!" << endl;
}
f_p a() {
void (*b_fp)() = b;
return b_fp;
}
int main()
{
//这是返回一个无参无返的函数指针的函数指针
//因为上面设置了typedef 也就是f_p就指代了void (*xxx)()
//但是语法并不支持写成 void (*b_fp)() (*a_fp)() = a;
f_p (*a_fp)() = a;
// void (*t_fp)() 这个是一个普通的函数指针,可以和上面对比一下
//b_fp就代表了b函数指针的名称,下面就可以通过b_fp来调用b函数
f_p(b_fp) = a_fp();
b_fp();
}
函数指针指向类中函数
如果是静态的函数则可以通过类来声明函数指针
class User {
public:
static void a() {
cout << "a" << endl;
}
static void b() {
cout << "b" << endl;
}
};
int main()
{
//类前加&和不加好像没有区别,如果您知道区别欢迎评论告诉我,谢谢
void (*a_fp)() = User::a;
a_fp();
void (*b_fp)() = &User::b;
b_fp();
}
而如果是非静态的函数,c++需要知道是那个对象来调用的,需要先存在对象才能调用
而且声明函数指针时需要指明函数所在类中
class User {
public:
void a() {
cout << "a" << endl;
}
};
int main()
{
//声明一个User类下的函数指针
void (User::*a_fp)() = &User::a;
}
对象使用.* 来调用,对象指针使用->*来调用
int main()
{
User u;
User* u_p = &u;
void (User::*a_fp)() = &User::a;
//通过对象调用
(u.*a_fp)();
//通过指针调用
(u_p->*a_fp)();
}
当我如上代码调用第九行
(u_p->*a_fp)();时ide提示使用未初始化内存*u_p 但是依然可以正常使用修改为
User* u_p = new User();就不存在这个问题,如果您知道为什么希望不吝赐教
函数指针指向虚函数
虚函数的作用就是为了实现多态,而指向虚函数的函数指针同样存在多态的功能
可以声明一个父类的函数指针,通过子类对象调用
class Animal {
public:
virtual void say() {
cout << "芜湖" << endl;
}
};
class Cat :public Animal{
public:
void say() {
cout << "喵喵喵" << endl;
}
};
class Dog :public Animal {
public:
void say() {
cout << "汪汪汪" << endl;
}
};
int main()
{
void (Animal:: * say_fp)() = &Animal::say;
Animal a;
(a.*say_fp)();
Cat c;
(c.*say_fp)();
Dog d;
(d.*say_fp)();
}
std::function
上面被函数指针疯狂拷打后,有没有简单点的还是以指针的形式调用函数呢,还真有
std::function可以调用任何可以调用的目标,包括函数,lambda表达式,执行成员函数和执行数据成员的指针......
如果function没有添加任何可以调用的元素,调用该对象将抛出一个std::bad_function_call异常
调用普通函数
无模板
#include <iostream>
#include <functional>
using namespace std;
void b() {
cout << "芜湖!" << endl;
}
int main()
{
//通过函数指针调用函数
void (*b_f)() = b;
b_f();
//通过function调用
function<void()> f = b;
f();
}
是不是简单很多呢
function<>尖括号内的参数方式为 方法返回值 (函数参数类型....)
上面提到了如果function没有包含可以被调用的对象,则会抛出异常,例如下面的代码
int main(){
function<void()> f;
f();
}
因为根本就没有给f赋值一个对象,直接调用会异常
不过function中有一个用于判断是否包含可调用对象的一个操作符重载
explicit operator bool() const noexcept {
return !this->_Empty();
}
void b() {
cout << "芜湖!" << endl;
}
int main()
{
function<void()> f;
if (f) {
cout << "包含了可以被调用的对象";
f();
}
else {
cout << "没有包含可以被调用的对象";
}
}
| 成员函数声明 | 说明 |
|---|---|
| constructor | 构造函数:constructs a new std::function instance |
| destructor | 析构函数: destroys a std::function instance |
| operator= | 给定义的function对象赋值 |
| operator bool | 检查定义的function对象是否包含一个有效的对象 |
| operator() | 调用一个对象 |
含模板
template <typename T>
int a(T t) {
return 1;
}
int main()
{
function<int(int)> f = a<int>;
f(1);
}
调用类成员函数
无模板
传入参数时使用User和User&都可以,这里不理解,如果您知道原因还请不吝赐教
class User {
public:
double a(int a) {
return 1;
}
};
int main()
{
function<double(User&,int)> f=&User::a;
function<double(User,int)> f2=&User::a;
User u1;
cout<<f(u1,10)<<endl;
cout<<f2(u1,10) << endl;
}
含类模板
template <typename T>
class User {
public:
int num;
void add(T t) {
}
};
int main()
{
function<void(User<int>, int)> f = &User<int>::add;
User<int>* u = new User<int>();
f(*u,10);
}
含函数模板
class User {
public:
int num;
template <typename T>
void add(T t) {
cout << "芜湖";
}
};
int main()
{
function<void(User, int)> f = &User::add<int>;
User* u=new User();
f(*u,10);
}
调用类成员静态函数
无模板
和调用普通函数差不多
class User {
public:
static double a(int a) {
return 1;
}
};
int main()
{
function<double(int)> f=&User::a;
function<double(int)> f2=User::a;
cout<<f(10)<<endl;
cout<<f2(10) << endl;
}
含类模板
template <typename T>
class User {
public:
int num;
static char* add(T t) {
cout << "芜湖";
return NULL;
}
};
int main()
{
function<char*(int)> f = &User<int>::add;
f(100);
}
含函数模板
class User {
public:
int num;
template <typename T>
static char* add(T t) {
cout << "芜湖";
return NULL;
}
};
int main()
{
function<char*(int)> f = &User::add<int>;
f(100);
}
调用类公共成员变量
无模板
class User {
public:
int num;
};
int main()
{
function<int(User)> f = &User::num;
function<int(User&)> f2=&User::num;
User u;
u.num = 100;
cout<<f(u)<<endl;
cout<<f2(u) << endl;
}
含成员变量模板
template <typename T>
class User {
public:
T num;
};
int main()
{
function<int(User<int>)> f = &User<int>::num;
User<int> u{100};
int a=f(u);
cout << a << endl;
}
调用lambda
int main() {
auto f = [](int a, int b) {
return a + b;
};
std::function<int(int, int)>func = f;
cout << func(1, 2) << endl;
}
通过bind函数调用类成员函数
无模板
class User {
public:
int a(int b) {
cout << "芜湖";
return b;
}
};
int main()
{
User u;
//通过指针调用
function<int(int)> f = bind(&User::a, &u, placeholders::_1);
//通过对象调用
function<int(int)> f2 = bind(&User::a, u, placeholders::_1);
f(1);
f2(2);
}
placeholders::_1 是一个展位符,如果User::a存在两个形参,int a(int b,int c) 那么就需要在bind函数后面在添加一个placeholders::_2作为展位符
如果有更多参数的话以此类推就可以了
int a(int b,int c) {
cout << "芜湖";
return b;
}
function<int(int,int)> f = bind(&User::a, &u, placeholders::_1, placeholders::_2);
//如果需要更多形参,那么就往后面添加placeholders::_3 placeholders::_4......
存在模板
和不存在模板基本相同代码
template <typename T>
class User {
public:
int a(T b,T c) {
cout << "芜湖";
return b;
}
};
int main()
{
User<int> u;
function<int(int,int)> f = bind(&User<int>::a, &u, placeholders::_1, placeholders::_2);
function<int(int,int)> f2 = bind(&User<int>::a, u, placeholders::_1, placeholders::_2);
f(1,2);
f2(2,3);
}
查询资料引用的博客:
https://blog.csdn.net/mz474920631/article/details/125019151
https://blog.csdn.net/qq_37085158/article/details/124626913
https://zhuanlan.zhihu.com/p/168627944

 浙公网安备 33010602011771号
浙公网安备 33010602011771号