Spring源码分析-BeanFactoryPostProcessor
Spring源码分析-BeanFactoryPostProcessor
博主技术有限,本文难免有错误的地方,如果您发现了欢迎评论私信指出,谢谢
JAVA技术交流群:737698533
BeanFactoryPostProcessor接口是Spring提供的对Bean的扩展点,它的子接口是BeanDefinitionRegistryPostProcessor
@FunctionalInterface
public interface BeanFactoryPostProcessor {
void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException;
}
public interface BeanDefinitionRegistryPostProcessor extends BeanFactoryPostProcessor {
void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) throws BeansException;
}
BeanFactoryPostProcessor简单使用
BeanFactoryPostProcessor的执行时机是在Spring扫描完成后,Bean初始化前,当我们实现BeanFactoryPostProcessor接口,可以在Bean的初始化之前对Bean进行属性的修改
@Component
public class A {
}
@Component
public class MyBeanFactoryPostProcessor implements BeanFactoryPostProcessor {
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
BeanDefinition beanDefinition = beanFactory.getBeanDefinition("a");
beanDefinition.setScope("prototype");
}
}
@Configuration
@ComponentScan("com.jame")
public class Myconfig {
}
public class MyTest {
public static void main(String[] args) {
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(Myconfig.class);
A a = context.getBean(A.class);
A a1 = context.getBean(A.class);
System.out.println(a==a1);
}
}
输出结果为:false
上面的例子我们将A的BeanDefinition的scope设置为原型,默认没有设置scope的情况下bean的scope都是单例,也就是说我们成功的修改了A对象的beanDefinition,能修改的属性不止这一个,还有是否懒加载,初始化方法名称,设置属性等等
而它的子类BeanDefinitionRegistryPostProcessor可以对spring容器中的BeanDefinition进行操作
不了解BeanDefinition的可以先简单理解为包装Java类的一个类,例如我们给类设置的是否单例,是否懒加载这些信息都需要存储,而spring就创建一个BeanDefinition,用来存储除了java类以外的其他信息
BeanDefinitionRegistryPostProcessor简单使用
@Component
public class A {
}
public class B {
}
@Component
public class MyBeanDefinitionRegistryPostProcessor implements BeanDefinitionRegistryPostProcessor {
@Override
public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) throws BeansException {
RootBeanDefinition beanDefinition = new RootBeanDefinition(B.class);
registry.registerBeanDefinition("b",beanDefinition);
registry.removeBeanDefinition("a");
}
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
}
}
@Configuration
@ComponentScan("com.jame")
public class Myconfig {
}
public class MyTest {
public static void main(String[] args) {
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(Myconfig.class);
B b = context.getBean(B.class);
System.out.println(b);
A a = context.getBean(A.class);
}
}
输出结果:
com.jame.pojo.B@2ac1fdc4
Exception in thread "main" org.springframework.beans.factory.NoSuchBeanDefinitionException: No qualifying bean of type 'com.jame.pojo.A' available......
上面的代码中我们对A类加上了@Component,B类什么都没有加,结果应该是A获取到正常输出,然后获取B时报错找不到,但是结果恰恰相反,因为我们在MyBeanDefinitionRegistryPostProcessor类中对Spring管理的Bean进行了修改,新增了一个B的BeanDefinition,删除了A的BeanDefinition,所以结果就如上面呈现的那样
完成了上面的简单使用案例接下来就开始看Spring的执行原理是什么
源码分析
首先第一步要知道什么时候执行的上面的代码,为了方便就不将查找过程粘贴出来了,可以在实现类中输出句话,Debug看看是在那个方法中输出的
public AnnotationConfigApplicationContext(Class<?>... componentClasses) {
this();
register(componentClasses);
refresh();
}
进入refresh方法
@Override
public void refresh() throws BeansException, IllegalStateException {
......
try {
// Allows post-processing of the bean factory in context subclasses.
postProcessBeanFactory(beanFactory);
// Invoke factory processors registered as beans in the context.
invokeBeanFactoryPostProcessors(beanFactory);
// Register bean processors that intercept bean creation.
registerBeanPostProcessors(beanFactory);
........
}
}
进入invokeBeanFactoryPostProcessors方法
public static void invokeBeanFactoryPostProcessors(
ConfigurableListableBeanFactory beanFactory, List<BeanFactoryPostProcessor> beanFactoryPostProcessors) {
Set<String> processedBeans = new HashSet<>();
if (beanFactory instanceof BeanDefinitionRegistry) {
BeanDefinitionRegistry registry = (BeanDefinitionRegistry) beanFactory;
List<BeanFactoryPostProcessor> regularPostProcessors = new ArrayList<>();
List<BeanDefinitionRegistryPostProcessor> registryProcessors = new ArrayList<>();
for (BeanFactoryPostProcessor postProcessor : beanFactoryPostProcessors) {
if (postProcessor instanceof BeanDefinitionRegistryPostProcessor) {
BeanDefinitionRegistryPostProcessor registryProcessor =
(BeanDefinitionRegistryPostProcessor) postProcessor;
registryProcessor.postProcessBeanDefinitionRegistry(registry);
registryProcessors.add(registryProcessor);
} else {
regularPostProcessors.add(postProcessor);
}
}
List<BeanDefinitionRegistryPostProcessor> currentRegistryProcessors = new ArrayList<>();
String[] postProcessorNames =
beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) {
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
processedBeans.add(ppName);
}
}
sortPostProcessors(currentRegistryProcessors, beanFactory);
registryProcessors.addAll(currentRegistryProcessors);
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);
currentRegistryProcessors.clear();
postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
if (!processedBeans.contains(ppName) && beanFactory.isTypeMatch(ppName, Ordered.class)) {
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
processedBeans.add(ppName);
}
}
sortPostProcessors(currentRegistryProcessors, beanFactory);
registryProcessors.addAll(currentRegistryProcessors);
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);
currentRegistryProcessors.clear();
boolean reiterate = true;
while (reiterate) {
reiterate = false;
postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
if (!processedBeans.contains(ppName)) {
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
processedBeans.add(ppName);
reiterate = true;
}
}
sortPostProcessors(currentRegistryProcessors, beanFactory);
registryProcessors.addAll(currentRegistryProcessors);
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);
currentRegistryProcessors.clear();
}
invokeBeanFactoryPostProcessors(registryProcessors, beanFactory);
invokeBeanFactoryPostProcessors(regularPostProcessors, beanFactory);
} else {
invokeBeanFactoryPostProcessors(beanFactoryPostProcessors, beanFactory);
}
String[] postProcessorNames =
beanFactory.getBeanNamesForType(BeanFactoryPostProcessor.class, true, false);
List<BeanFactoryPostProcessor> priorityOrderedPostProcessors = new ArrayList<>();
List<String> orderedPostProcessorNames = new ArrayList<>();
List<String> nonOrderedPostProcessorNames = new ArrayList<>();
for (String ppName : postProcessorNames) {
if (processedBeans.contains(ppName)) {
} else if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) {
priorityOrderedPostProcessors.add(beanFactory.getBean(ppName, BeanFactoryPostProcessor.class));
} else if (beanFactory.isTypeMatch(ppName, Ordered.class)) {
orderedPostProcessorNames.add(ppName);
} else {
nonOrderedPostProcessorNames.add(ppName);
}
}
sortPostProcessors(priorityOrderedPostProcessors, beanFactory);
invokeBeanFactoryPostProcessors(priorityOrderedPostProcessors, beanFactory);
List<BeanFactoryPostProcessor> orderedPostProcessors = new ArrayList<>();
for (String postProcessorName : orderedPostProcessorNames) {
orderedPostProcessors.add(beanFactory.getBean(postProcessorName, BeanFactoryPostProcessor.class));
}
sortPostProcessors(orderedPostProcessors, beanFactory);
invokeBeanFactoryPostProcessors(orderedPostProcessors, beanFactory);
List<BeanFactoryPostProcessor> nonOrderedPostProcessors = new ArrayList<>();
for (String postProcessorName : nonOrderedPostProcessorNames) {
nonOrderedPostProcessors.add(beanFactory.getBean(postProcessorName, BeanFactoryPostProcessor.class));
}
invokeBeanFactoryPostProcessors(nonOrderedPostProcessors, beanFactory);
beanFactory.clearMetadataCache();
}
来看最上面定义
Set<String> processedBeans = new HashSet<>();
这个也很好理解,存放已经执行完的BeanFactoryPostProcessor名字,防止重复执行
if (beanFactory instanceof BeanDefinitionRegistry) {
BeanDefinitionRegistry registry = (BeanDefinitionRegistry) beanFactory;
//存放直接实现BeanFactoryPostProcessor,处理过/找到的实现类
List<BeanFactoryPostProcessor> regularPostProcessors = new ArrayList<>();
//存放直接实现BeanDefinitionRegistryPostProcessor,处理过/找到的实现类
List<BeanDefinitionRegistryPostProcessor> registryProcessors = new ArrayList<>();
for (BeanFactoryPostProcessor postProcessor : beanFactoryPostProcessors) {
if (postProcessor instanceof BeanDefinitionRegistryPostProcessor) {
BeanDefinitionRegistryPostProcessor registryProcessor =
(BeanDefinitionRegistryPostProcessor) postProcessor;
registryProcessor.postProcessBeanDefinitionRegistry(registry);
registryProcessors.add(registryProcessor);
} else {
regularPostProcessors.add(postProcessor);
}
}
来看第一个if判断,判断传入的BeanFactory是否是BeanDefinitionRegistry类型,大部分情况都是,我们先默认它一直为true
那么上面定义两个集合用来存放已经处理过的实现类
下面这个for循环只有通过api来设置的BeanFactoryPostProcessor才会有值,什么意思呢?看下面
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(Myconfig.class);
context.addBeanFactoryPostProcessor(new MyBeanFactoryPostProcessor());
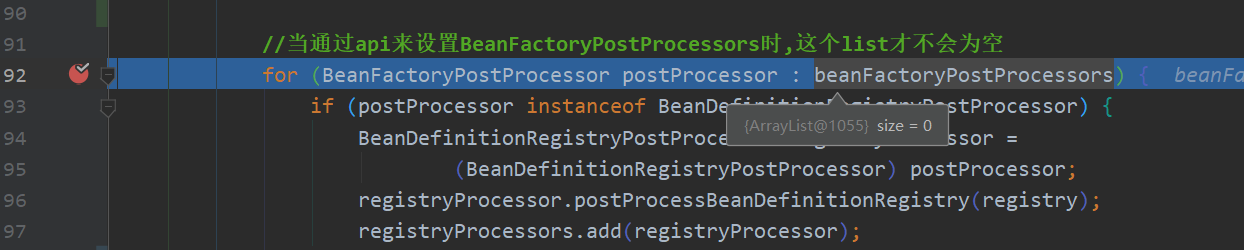
为什么没有呢?因为我们的代码运行顺序的问题,来看上面的使用代码,是先new AnnotationConfigApplicationContext(MyConfig.class)
而在它的构造中就已经调用refresh->invokeBeanFactoryPostProcessors->invokeBeanFactoryPostProcessors方法了
而我们debug时候还没有走到context.addBeanFactoryPostProcessor(new MyBeanFactoryPostProcessor());方法,所以为空
那怎么使用?我们仔细来看AnnotationConfigApplicationContext的构造
public AnnotationConfigApplicationContext(Class<?>... componentClasses) {
this();
register(componentClasses);
refresh();
}
里面就3个方法,调自己无参,register,refresh,而执行invokeBeanFactoryPostProcessors在refresh方法中,也就是说我们可以在refresh方法前进行注册即可
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext();
context.register(Myconfig.class);
context.addBeanFactoryPostProcessor(new MyBeanFactoryPostProcessor());
context.refresh();
这样,我们就能在refresh方法前进行手动调用api的方式添加

继续往下
if (postProcessor instanceof BeanDefinitionRegistryPostProcessor) {
BeanDefinitionRegistryPostProcessor registryProcessor =
(BeanDefinitionRegistryPostProcessor) postProcessor;
registryProcessor.postProcessBeanDefinitionRegistry(registry);
registryProcessors.add(registryProcessor);
} else {
regularPostProcessors.add(postProcessor);
}
判断是BeanDefinitionRegistryPostProcessor类型,如果是,则直接执行.否则添加到集合,还记得这个集合吗在最外层的if中
if (beanFactory instanceof BeanDefinitionRegistry) {
BeanDefinitionRegistry registry = (BeanDefinitionRegistry) beanFactory;
//存放直接实现BeanFactoryPostProcessor,处理过/找到的实现类
List<BeanFactoryPostProcessor> regularPostProcessors = new ArrayList<>();
//存放直接实现BeanDefinitionRegistryPostProcessor,处理过/找到的实现类
List<BeanDefinitionRegistryPostProcessor> registryProcessors = new ArrayList<>();
......
}
如果不是则添加到regularPostProcessors集合,为什么这个类型不执行因为和Spring的执行顺序有关,等到最后在说
从List
List<BeanDefinitionRegistryPostProcessor> currentRegistryProcessors = new ArrayList<>();
String[] postProcessorNames =
beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) {
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
processedBeans.add(ppName);
}
}
sortPostProcessors(currentRegistryProcessors, beanFactory);
registryProcessors.addAll(currentRegistryProcessors);
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);
currentRegistryProcessors.clear();
首先这个集合干啥的:用来存放当前需要执行的BeanDefinitionRegistryPostProcessor
存放需要执行的BeanDefinitionRegistryPostProcessor的好理解,那什么叫做当前的?? 提前说一下,这个集合是在下面复用的,当前的就是当前正在执行的BeanDefinitionRegistryPostProcessor类型是一类的,先往下看,一会再解释
首先它创建一个字符串数组来接收beanFactory.getBeanNamesForType的返回参数,简单说下这个方法的作用
从BeanDefinitionNames中寻找类型为传入类型的BeanDefinition的名称
调用链为:DefaultListableBeanFactory.getBeanNamesForType->DefaultListableBeanFactory.doGetBeanNamesForType,有兴趣可以自己去看看
那我们debug来看看获取到类型是BeanDefinitionRegistryPostProcessor的beanName都有谁

那么继续向下
if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) 检查传入的PostProcessorName的BenaDefinition是否符合PriorityOrdered.class,当然该方法的作用不止于此,我们现在只分析有关的
PriorityOrdered是一个排序的接口,它的父类是Ordered,谁的值越小越先调用,先简单了解下即可,不是本章重点
public interface PriorityOrdered extends Ordered {
}
public interface Ordered {
int HIGHEST_PRECEDENCE = Integer.MIN_VALUE;
int LOWEST_PRECEDENCE = Integer.MAX_VALUE;
int getOrder();
}

留个疑问,这个BeanDefinition什么时候进来的?先继续看代码整体返回true进入判断
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
主要重点在getBean方法,以后有机会在单独写篇getBean的,简单理解为从Spring的容器中获取类,如果不存在则从BeanDefinitionMap中找到对应BeanDefinition,然后实例化返回
那么假设我们已经获取到了实例化后的java对象,它是谁呢?debug
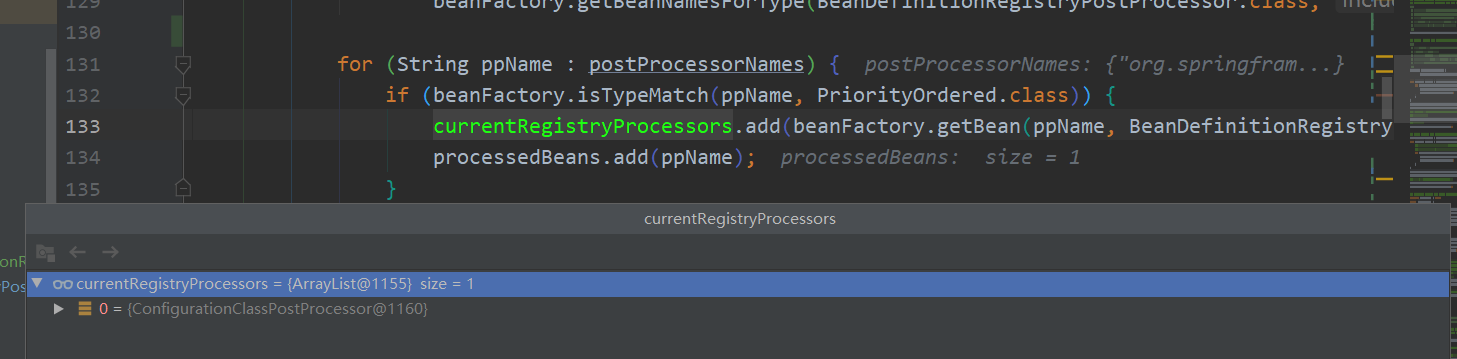
请记住这个类 ConfigurationClassPostProcessor
之后将当前类的名称存放到已经处理过的set中,在该方法的最上面
//储存已经完成处理的BeanFactoryPostProcessor名字
Set<String> processedBeans = new HashSet<>();
之后调用排序方法,然后把已经处理过的BeanFactoryPostProcessor存放到List
//存放直接实现BeanDefinitionRegistryPostProcessor,处理过的实现类
List<BeanDefinitionRegistryPostProcessor> registryProcessors = new ArrayList<>();
我们重点来看invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);方法
private static void invokeBeanDefinitionRegistryPostProcessors(
Collection<? extends BeanDefinitionRegistryPostProcessor> postProcessors, BeanDefinitionRegistry registry) {
for (BeanDefinitionRegistryPostProcessor postProcessor : postProcessors) {
postProcessor.postProcessBeanDefinitionRegistry(registry);
}
}
上面找到的ConfigurationClassPostProcessor是重中之重,Spring的扫描就是这个类中完成的,何以证明?Debug
我们来看beanFactory中的BeanDefinitionMap数量即可
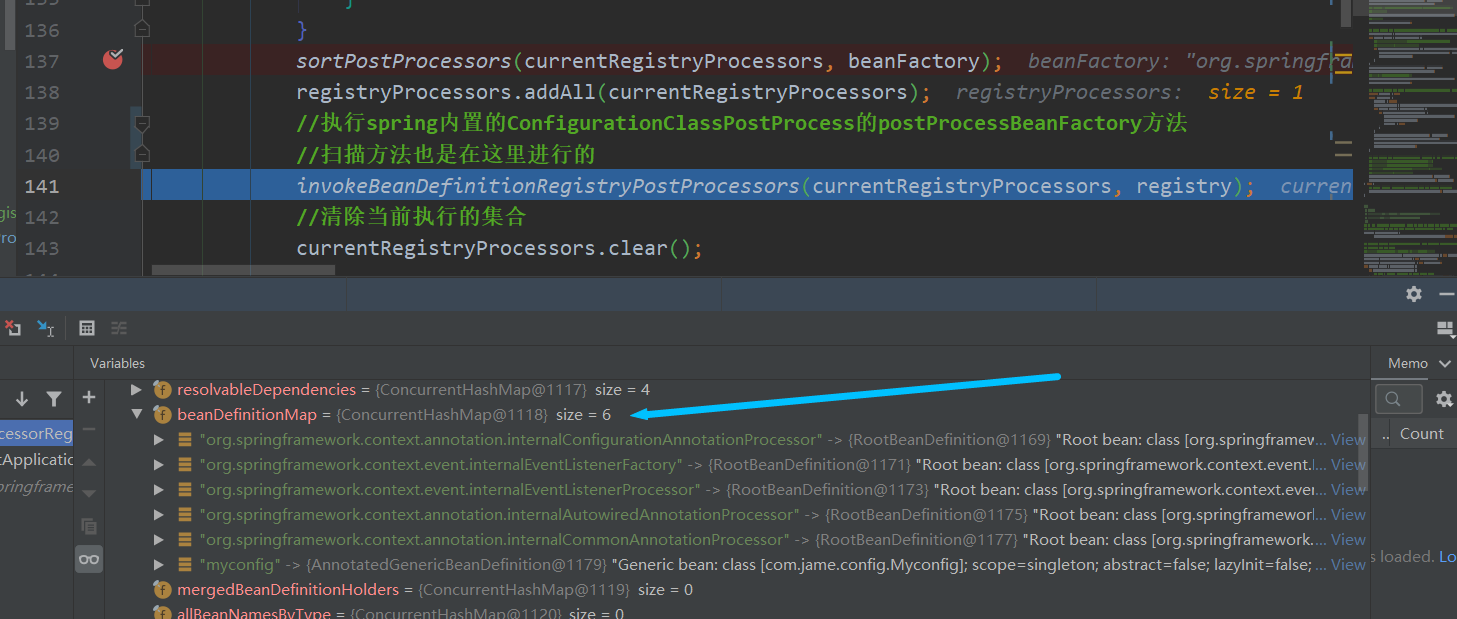

关于Spring的扫描以后有机会写一篇
然后清空当前正在执行的List集合,继续向下
postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
//这里判断如果在存储已经完成的集合中没有找到当前的BeanDefinitionRegistryPostProcessor
//也就是说明这个还没有被执行过,那么放入当前执行的集合中进行下一步操作
if (!processedBeans.contains(ppName) && beanFactory.isTypeMatch(ppName, Ordered.class)) {
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
processedBeans.add(ppName);
}
}
sortPostProcessors(currentRegistryProcessors, beanFactory);
registryProcessors.addAll(currentRegistryProcessors);
//一样的代码,执行postProcessBeanFactory方法
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);
currentRegistryProcessors.clear();
发现了什么,代码和上面的很像,那么我们不在赘述,直接简单说一下重点
if (!processedBeans.contains(ppName) && beanFactory.isTypeMatch(ppName, Ordered.class))
判断除了已经处理过的,防止重复执行,然后就是判断类型,上面的类型是PriorityOrdered 现在是Ordered
那么再来看
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
而这个集合就是刚才定义的存放"当前处理"的集合
List<BeanDefinitionRegistryPostProcessor> currentRegistryProcessors = new ArrayList<>();
什么叫当前处理,在最开始执行的时候,这个集合存放的都是实现PriorityOrdered接口的类,对于上面来说,"当前处理的"就是实现PriotyOrdered类,然后代码执行到currentRegistryProcessors.clear();那么对于实现PriorityOrdered接口的类来说,"当前处理"的这个集合,已经不是存放PriorityOrdered接口的实现类了
而到了这里,这个list中只存放Ordered类型的,那么"当前处理的"就指的是实现Ordered接口的类,因为它这个集合是好多地方复用的,所以叫做"当前处理"集合
那么下面的代码应该能看明白吧,上面处理了实现PriorityOrdered,Ordered的BeanDefinitionRegistryPostProcessor,都执行完了最后执行没有实现两者的BeanDefinitionRegistryPostProcessor
boolean reiterate = true;
while (reiterate) {
reiterate = false;
postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
if (!processedBeans.contains(ppName)) {
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
processedBeans.add(ppName);
reiterate = true;
}
}
sortPostProcessors(currentRegistryProcessors, beanFactory);
registryProcessors.addAll(currentRegistryProcessors);
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);
currentRegistryProcessors.clear();
}
那么这里可能有个疑问
registryProcessors.addAll(currentRegistryProcessors);
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);
这不是执行过了吗,为啥还要放集合,请注意,当前找的接口是BeanDefinitionRegistryPostProcessor的实现类,而不是BeanFactoryPostProcessor,那么一个简单的java基础问题,一个类实现了A接口,而A接口又继承B接口,请问这个类需要实现B接口定义的方法吗,答案是肯定的,那么上面的只是执行BeanDefinitionRegistryPostProcessor接口中定义的方法,所以来看后两行就一目了然了
//为什么要传入已经执行过的BeanDefinitionRegisterPostProcess的集合?
//因为我们自定义的类实现了BeanDefinitionRegisterPostProcess这个接口
//而这个接口又继承了BeanFactoryPostProcess,那么我们不仅要实现子类的方法,还要实现父类的方法
//而在上面的处理仅仅调用了子类的方法,所以又在这里调用一次父类的方法
invokeBeanFactoryPostProcessors(registryProcessors, beanFactory);
invokeBeanFactoryPostProcessors(regularPostProcessors, beanFactory);
好的,到此为止,使用Api添加的PostProcessor完成,但是有个小问题,发现了吗,每次postProcessorNames都是重新获取一次,为什么不获取一次然后一直使用呢?
回过头我们来看开始使用BeanDefinitionRegistryPostProcessor的简单使用案例,假设实现PriorityOrdered接口的类在调用完postProcessBeanDefinitionRegistry方法对bean的数量进行了修改,那么下面的操作获取的数据都不是最新的,为了解决这个问题所以每次操作都重新获取一遍
继续向下走,下面的代码就是我们通过扫描或xml找到的BeanFactoryPostProcessor实现类
String[] postProcessorNames =
beanFactory.getBeanNamesForType(BeanFactoryPostProcessor.class, true, false);
// Separate between BeanFactoryPostProcessors that implement PriorityOrdered,
// Ordered, and the rest.
//分别是存放实现了priorityOrdered接口,Ordered接口,和没有实现Ordered接口的名称集合
List<BeanFactoryPostProcessor> priorityOrderedPostProcessors = new ArrayList<>();
List<String> orderedPostProcessorNames = new ArrayList<>();
List<String> nonOrderedPostProcessorNames = new ArrayList<>();
for (String ppName : postProcessorNames) {
if (processedBeans.contains(ppName)) {
// skip - already processed in first phase above
} else if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) {
priorityOrderedPostProcessors.add(beanFactory.getBean(ppName, BeanFactoryPostProcessor.class));
} else if (beanFactory.isTypeMatch(ppName, Ordered.class)) {
orderedPostProcessorNames.add(ppName);
} else {
nonOrderedPostProcessorNames.add(ppName);
}
}
// First, invoke the BeanFactoryPostProcessors that implement PriorityOrdered.
sortPostProcessors(priorityOrderedPostProcessors, beanFactory);
invokeBeanFactoryPostProcessors(priorityOrderedPostProcessors, beanFactory);
// Next, invoke the BeanFactoryPostProcessors that implement Ordered.
List<BeanFactoryPostProcessor> orderedPostProcessors = new ArrayList<>();
for (String postProcessorName : orderedPostProcessorNames) {
orderedPostProcessors.add(beanFactory.getBean(postProcessorName, BeanFactoryPostProcessor.class));
}
sortPostProcessors(orderedPostProcessors, beanFactory);
invokeBeanFactoryPostProcessors(orderedPostProcessors, beanFactory);
// Finally, invoke all other BeanFactoryPostProcessors.
List<BeanFactoryPostProcessor> nonOrderedPostProcessors = new ArrayList<>();
for (String postProcessorName : nonOrderedPostProcessorNames) {
nonOrderedPostProcessors.add(beanFactory.getBean(postProcessorName, BeanFactoryPostProcessor.class));
}
invokeBeanFactoryPostProcessors(nonOrderedPostProcessors, beanFactory);
下面的代码就比较简单了,就简单写下
首先还是通过 beanFactory.getBeanNamesForType(BeanFactoryPostProcessor.class, true, false);获取类型为BeanFactoryPostProcessor的实现类名称,然后依次判断实现了PriorityOrdered接口了吗,实现Ordered接口了吗,还是两个都没实现
分别放到对应的集合中,随后顺序执行
我们来捋一下执行的顺序
- 通过Api添加实现BeanDefinitionRegistryPostProcessor接口的postProcessBeanDefinitionRegistry方法
- Spring内置实现BeanDefinitionRegistryPostProcessor接口的postProcessBeanDefinitionRegistry方法
- 扫描出的实现BeanDefinitionRegistryPostProcessor接口的postProcessBeanDefinitionRegistry方法
- 通过Api添加实现BeanDefinitionRegistryPostProcessor接口的postProcessBeanFactory方法
- 执行通过扫描/xml配置实现BeanDefinitionRegistryPostProcessor接口的postProcessBeanFactory方法
- 执行通过扫描/xml配置实现BeanFactoryPostProcessor接口的postProcessBeanFactory方法
如果有相同的类型,例如都是通过api添加实现BeanDefinitionRegistryPostProcessor接口的
那么执行顺序为先执行实现PriorityOrdered接口,然后在执行实现Ordered接口,最后在执行两个接口都没实现的类
如果同一类型实现排序接口有多个,那么谁的实现方法返回值越小越先执行
我们来写代码实际演示下
整体结构如下
public class BDRPP_API implements BeanDefinitionRegistryPostProcessor {
@Override
public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) throws BeansException {
System.out.println("API-BDRPP_API的postProcessBeanDefinitionRegistry方法");
}
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
System.out.println("API-BDRPP_API的postProcessBeanFactory方法");
}
}
@Component
public class BDRPP_Scan implements BeanDefinitionRegistryPostProcessor {
@Override
public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) throws BeansException {
System.out.println("扫描-BDRPP_Scan的postProcessBeanDefinitionRegistry方法");
}
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
System.out.println("扫描-BDRPP_Scan的postProcessBeanFactory方法");
}
}
@Component
public class BFPP_Scan implements BeanFactoryPostProcessor {
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
System.out.println("扫描-BFPP_Scan类的postProcessBeanFactory方法");
}
}
在Spring扫描的方法中添加一句话用于输出
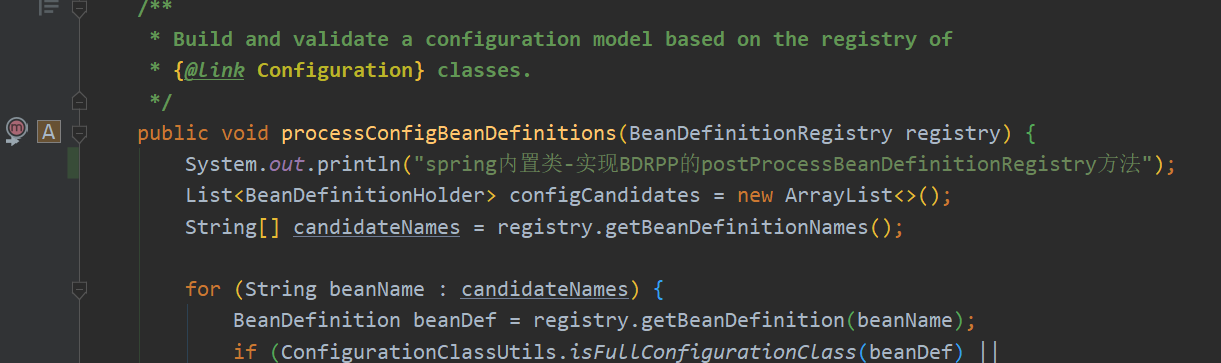
排序的接口就不实现了,我们来看结果
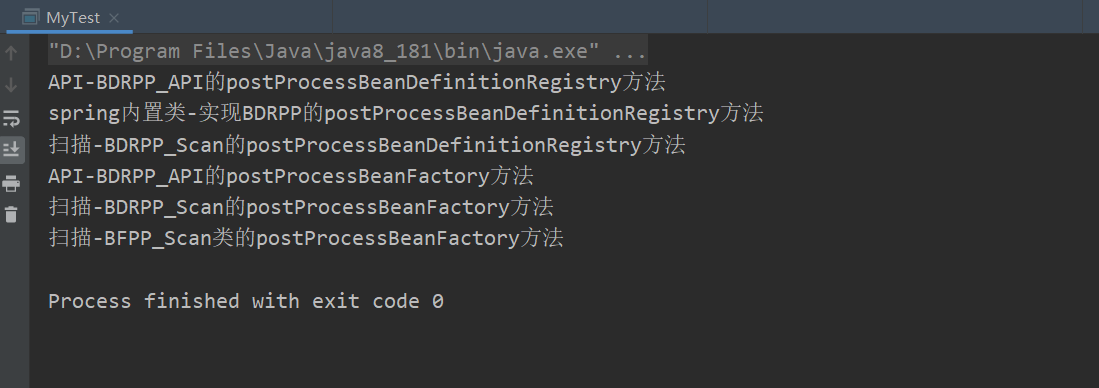
也就是说如果想在Spring完成扫描前对Bean进行一些操作可以实现BeanDefinitionRegistryPostProcessor接口并手动添加,而上面的输出也显示了,在同继承PriorityOrdered或Ordered的时候,值小的先执行
还有一个问题,我们在获取BeanFactoryPostProcessor时名称使用前每次都是重新获取一下,而在下面通过扫描或Xml配置的BeanFactoryPostProcessor时却只进行一次获取
String[] postProcessorNames = beanFactory.getBeanNamesForType(BeanFactoryPostProcessor.class, true, false);
因为BeanFactoryPostProcessor接口只是对bean进行增强处理,不会进行删除新增的操作
回答上面的疑问:这个ConfigurationClassPostProcessor的BeanDefinition什么时候进来的
来看new AnnotationConfigApplicationContext()的无参构造
public AnnotationConfigApplicationContext() {
//spring内置的bd将在这里进行注册
this.reader = new AnnotatedBeanDefinitionReader(this);
this.scanner = new ClassPathBeanDefinitionScanner(this);
}
public AnnotatedBeanDefinitionReader(BeanDefinitionRegistry registry, Environment environment) {
Assert.notNull(registry, "BeanDefinitionRegistry must not be null");
Assert.notNull(environment, "Environment must not be null");
this.registry = registry;
this.conditionEvaluator = new ConditionEvaluator(registry, environment, null);
//这里
AnnotationConfigUtils.registerAnnotationConfigProcessors(this.registry);
}
public static Set<BeanDefinitionHolder> registerAnnotationConfigProcessors(
BeanDefinitionRegistry registry, @Nullable Object source) {
.....
if (!registry.containsBeanDefinition(CONFIGURATION_ANNOTATION_PROCESSOR_BEAN_NAME)) {
RootBeanDefinition def = new RootBeanDefinition(ConfigurationClassPostProcessor.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, CONFIGURATION_ANNOTATION_PROCESSOR_BEAN_NAME));
}
.......
}
还记得上面第一次通过String[] postProcessorNames =
beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
来看CONFIGURATION_ANNOTATION_PROCESSOR_BEAN_NAME这个常量的值是啥
public static final String CONFIGURATION_ANNOTATION_PROCESSOR_BEAN_NAME =
"org.springframework.context.annotation.internalConfigurationAnnotationProcessor";
而它这个if判断是
@Override
public boolean containsBeanDefinition(String beanName) {
Assert.notNull(beanName, "Bean name must not be null");
return this.beanDefinitionMap.containsKey(beanName);
}
也就是说在初始化时,如果不存在则进行注册beanDefinition,具体注册的方法从
beanDefs.add(registerPostProcessor(registry, def, CONFIGURATION_ANNOTATION_PROCESSOR_BEAN_NAME));
registry.registerBeanDefinition(beanName, definition);
DefaultListableBeanFactory.registerBeanDefinition注册beanDefinition的方法,有兴趣可以点进去看看

 浙公网安备 33010602011771号
浙公网安备 33010602011771号