
java基础知识--List、Set集合
1.1 概述
=》特点总结:
-
-
它是一个带有索引的集合,通过索引就可以精确的操作集合中的元素。
-
-
1.2 常用方法
List作为Collection集合的子接口,不但继承了Collection接口中的全部方法,而且还增加了一些根据元素索引来操作集合的特有方法,如下:
-
-
public E get(int index):返回集合中指定位置的元素。 -
public E remove(int index):移除列表中指定位置的元素, 返回的是被移除的元素。 -
public E set(int index, E element):
LinkedList提供了大量首尾操作的方法,如:
-
-
-
-
public void addLast(E e):将指定元素添加到此列表的结尾。 -
public E getFirst():返回此列表的第一个元素。 -
public E getLast():返回此列表的最后一个元素。 -
public E removeFirst():移除并返回此列表的第一个元素。 -
public E removeLast移除并返回此列表的最后一个元素。():
-
-
以上方法在获取元素时,若集合中元素为空,则会返回 NoSuchElementException 异常。
所以在 java1.6 中,以上方法分别被
offerFirst(E e)、offerLast(E e)、peekFirst()、peekLast()、pollFirst()、pollLast()替代,它们在获取元素时,若集合中元素为空,则会返回 null。
-
-
-
public E pop():从此列表所表示的堆栈处弹出一个元素。 -
public void push(E e):将元素推入此列表所表示的堆栈。 -
public boolean isEmpty()
-
-
1.3.3 Vector集合
java.util.Vector
boolean |
hasMoreElements() 测试此枚举是否包含更多的元素。 |
E |
nextElement()
如果此枚举对象至少还有一个可提供的元素,则返回此枚举的下一个元素。 |
ArrayList 和 Vector 数据结构均为数组结构,因为 Vector 是同步的,所以效率低,实际应用中被 ArrayList 取代。
ArrayList 构造一个初始容量为 10 的空列表,当存储长度大于10 时,列表长度增加原有列长的50%。
Vector 构造一个初始容量为 10 的空列表,当存储长度大于10 时,列表长度增加原有列长的100%。比较浪费空间。
扩展自定义排序
// list自定义排序 /*List<String> data = new ArrayList<>(); Collections.addAll(data, "柒","一","十一","叁"); List<String> list = new ArrayList<>(); Collections.addAll(list, "一","叁","柒","十一"); Collections.sort(data, new Comparator<String>() { @Override public int compare(String o1, String o2) { return list.indexOf(o1) - list.indexOf(o2); } }); System.out.println(data);*/
Set集合
1.1 概述
-
-
它是一个没有索引的集合。
-
-
1.2 Set的子类
1.2.1 HashSet集合
1.2.1.1 概述与介绍
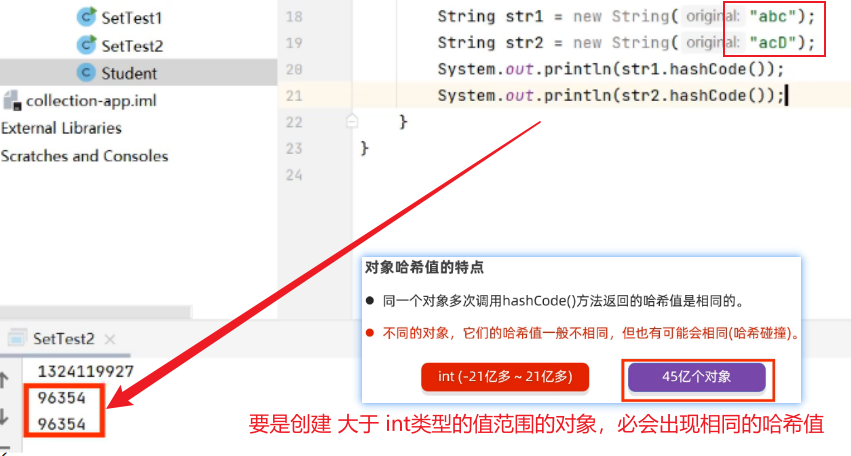
1.2.1.2
什么是哈希表呢?
哈希表是一种增删改查数据,性能都较好的数据结构。
在JDK1.8
简单的来说,哈希表是由数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的,如下图所示:

存储流程:
① 创建一个默认长度为16的数组,默认加载因子为0.75,数组名table;
- 当数据占满数组的16*0.75=12个元素位置时,数组便会选择扩容。
② 使用元素的哈希值对数组的长度求余,计算出应存入的位置;
③ 判断当前位置是否为null,如果为null,直接存入,如果不为null,表示有元素,则调用equals方法比较。相等,则不存;不相等,则存入。
- JDK8 之前,新元素存入数组,占老元素位置,老元素挂下面;
- JDK8 开始,新元素直接挂老元素下面。链表长度大于8,且数组长度>=64,自动将链表转红黑树。

1.2.3

1.2.2 TreeSet集合
java.util.TreeSet是Set接口的一个实现类,红黑树数据结构。具有可排序(默认升序)、唯一、无索引的特点。
注意:
- 对于数值类型:Integer,Double等,默认按照数值本身的大小进行升序排序;
- 对于字符串类型:默认按照首字符的编号升序排序。
- 对于自定义类型(如Students对象),TreeSet默认是无法直接排序的,需要自定义排序规则。
- 方式一:自定义类型实现Comparable接口,重写compareTo方法;
方式二:通过调用TreeSet集合有参构造器,可以设置Comparator对象(比较器对象)。
- public TreeSet(Comparator<? super E> comparator)
主要用来对set集合中的数据进行排序,具体的排序方法和方式在collections中有简述到Comparable和Comparator的相关内容,具体可查看https://www.cnblogs.com/sun9/p/13475427.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号