
20230210组会论文学习心得
1、【AAAI2023】Ultra-High-Definition Low-Light Image Enhancement: A Benchmark and Transformer-Based Method
论文:https://arxiv.org/abs/2212.11548
代码:https://github.com/TaoWangzj/LLFormer
本文主要贡献:(1)基于low-light image enhancement任务,提出了4K和8K分辨率的Ultra-High-Definition数据集
(2)提出了基于transformer的low-light enhancement方法LLFormer
LLFormer的整体框架
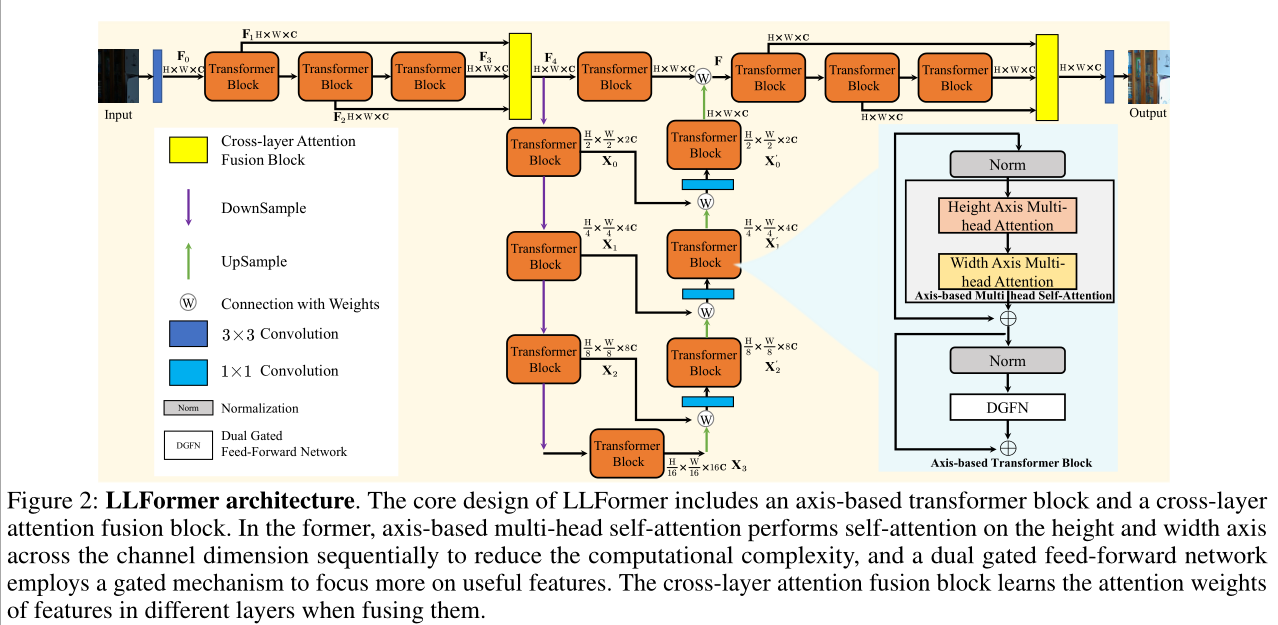
LLFormer主要包括axis-based的transformer块和cross-layer注意力融合块。前者通过channel维度上的高度和宽度多头自注意力降低计算复杂性,采取门控机制的FFN更加关注有效特征;后者通过学习注意力权重融合不同层中的特征。
(1)axis-based transformer block
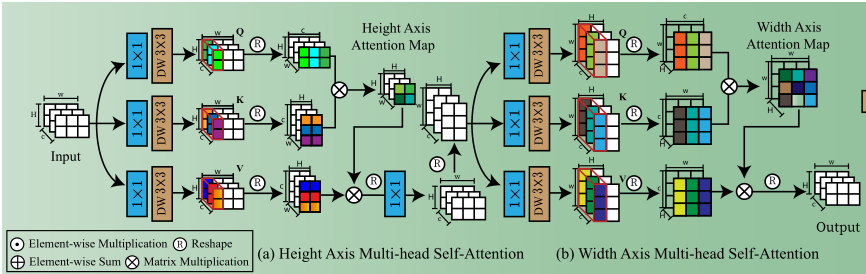
高分辨率图像的计算成本很高,因此作者提出在channel维度上分别计算HxH和WxW,也就是Height Axis Multi-head Attention和Width Axis Multi-head Attention。对于每种注意力,先应用1×1卷积来增强输入特征,再使用3×3深度卷积获得丰富的局部特征,reshape后点积得到Attention Map。
(2)dual gated feed-forward network(DGFN)
作者在FFN中引入了双门控机制和局部信息增强,在两条并行路径中应用1×1卷积和3×3深度卷积来丰富局部信息,然后采用一条路径GELU另一条路径门控的方法使得两条路径互相进行权重加权,可以过滤信息量较少的特征,最后融合两个有效信息和初始信息。

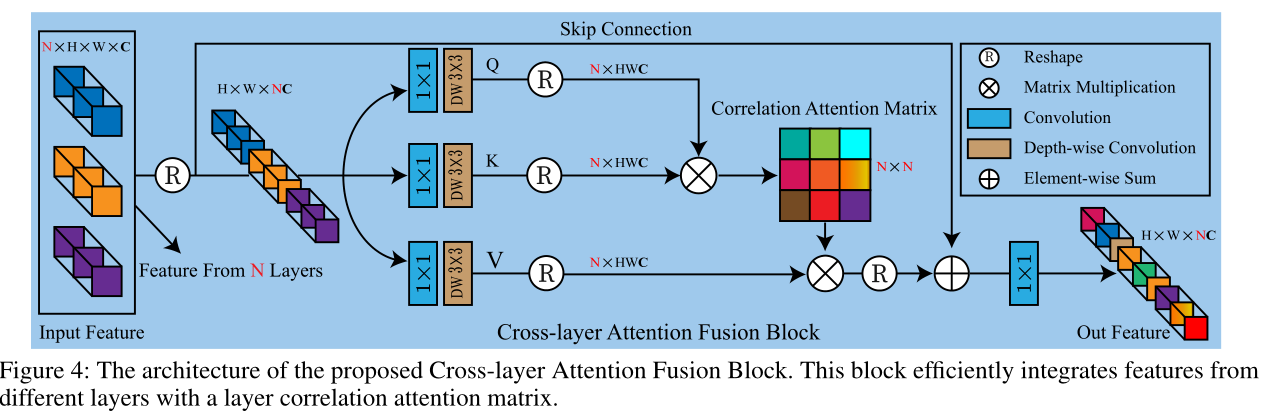
(3)cross-layer attention fusion block(CAFB)
作者认为目前的特征连接没有充分利用层与层间的依赖关系,提出了跨层注意力融合块。对于给定的N个特征,reshape后经过卷积提取上下文信息,QK生成NxN的关联注意力矩阵A,通过比例因子α与V相乘进行加权,该方法有助于捕获各层之间的长距离依赖关系。
2、【NeurIPS2022】ShuffleMixer: An Efficient ConvNet for Image Super-Resolution
论文:http://arxiv.org/pdf/2205.15175
代码:https://github.com/sunny2109/MobileSR-NTIRE2022
本文贡献:(1)基于大内核ConvNet的创新SR设计;(2)引入了通道split和shuffle操作进行特征混合;(3)提出Fused-MBconv实现跨组特征的局部连通性
ShuffleMixer总体框架
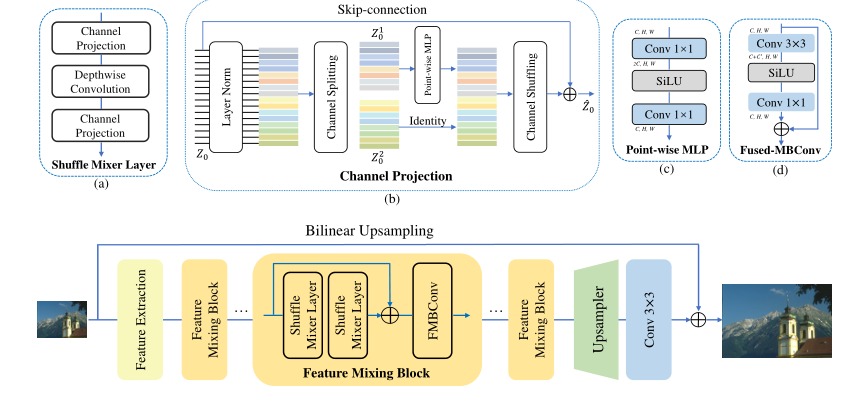
ShuffleMixer主要包括特征混合模块、FMBConv模块和上采样模块。Feature Mixing Block (FMB)包含2个(a)shuffle mixer layers和1个(d)Fused-MBConv (FMBConv),其中每个(a)shuffle mixer layers由2个(b)channel projection模块和一个大核深度卷积组成,其中(b)channel projection模块又含有通道split和shuffle操作、(c) point-wise MLP layers和skip connections。
本文核心部分是Feature Mixing Block:
(1)shuffle mixer layer采用大卷积核Depthwise-Conv在空间位置上混合特征,用更少的参数获取更多的信息;采用Channel projection来混合不同通道间的特征,将channel分为两部分,一部分用逐点MLP进行通道特征的混合,另一部分不变,两组进行shuffle,最后使用skip connections进行信息融合。
(2)Fused-MBConv包含一个3x3的扩展卷积、一个SiLU层(作为门控机制)和一个1x1卷积,能充分利用局部信息,起到FFN的作用。
3、 【ARXIV2212】A Close Look at Spatial Modeling: From Attention to Convolution
论文:https://arxiv.org/abs/2212.12552
代码: https://github.com/ma-xu/FCViT
本文贡献:(1)指出Attention Maps是查询无关的,Attention Weights本质上是稀疏的(2)提出Fully Convolutional Vision Transformer(FCViT),将全局上下文集成到卷积中,具有良好的效率和性能。
FCViT的整体架构:
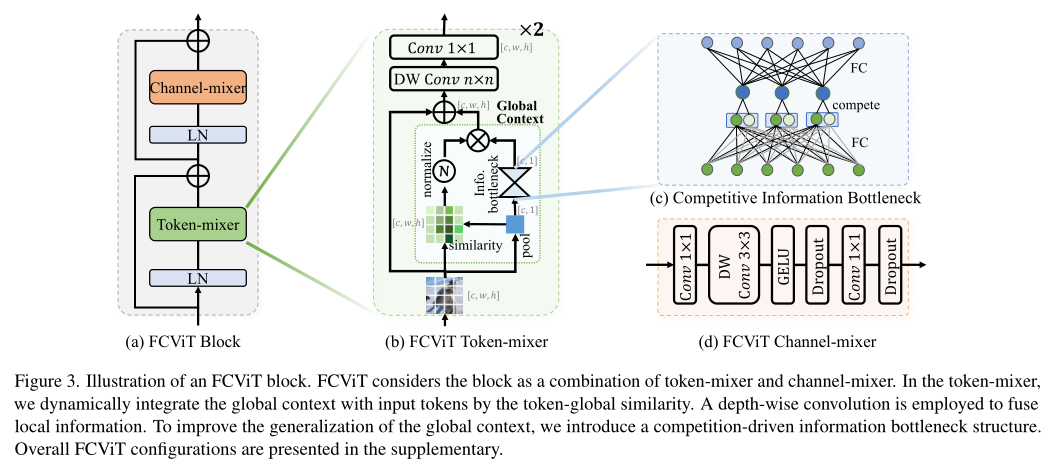
FCViT由token-mixer和channel-mixer组成。关键核心在于能获取增强全局上下文信息的token-mixer,它包含内核为k的深度卷积和1x1卷积,用平均池化进行normalize。总的来说,通过计算原始图像和池化后图像得到动态继承全局信息的全局相似性矩阵,利用分组操作减少计算开销,引入“竞争”的bottleneck架构提高泛化能力。
(1)dynamic global context
为了进行动态提取特征,作者记相似度分数S=XX',X是输入,X'取均值,通过S的均值和方差再对gc进行缩放可得gc'
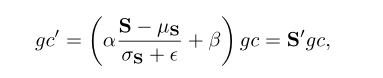
(2)Multi-Group Similarity
作者采用了多组的方法降低开销,将gc、X、X’沿着通道方向分成g组,每组内进行计算,公式如下:
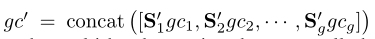
(3)Competitive Information Bottleneck
作者引入了bottleneck——竞争机制,选择连接后较大的节点,能显著降低参数:
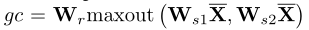
4、 【ARXIV2301】DEA-Net: Single image dehazing based on detail-enhanced convolution and content-guided attention
论文:http://arxiv.org/abs/2301.04805v1
代码:https://github.com/cecret3350/DEA-Net
本文贡献:(1)提出了包含并行的vanilla和difference卷积的detail-enhanced convolution (DEConv),第一次引入差分卷积解决图像去噪问题;(2)提出了创新的注意力机制content-guided attention (CGA),生成channel相关的SIMs;(3)基于DEConv和CGA,提出了用于重建高质量无霾图像的细节增强注意力网络detail-enhanced attention network(DEA-Net)
DEA-Net的整体框架:
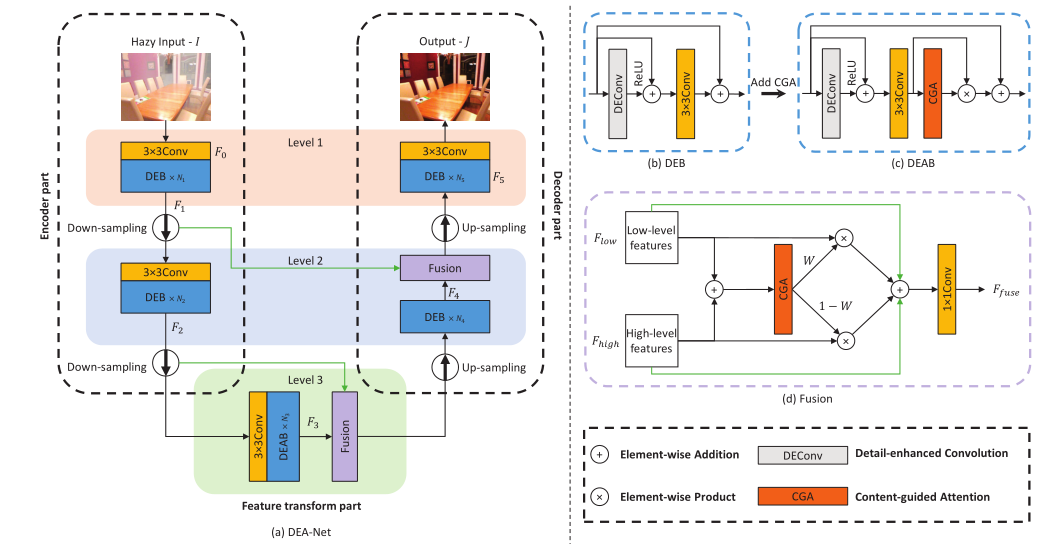
DEA-Net是一个类似三层的编码器-解码器架构,包含编码器部分、特征变换部分和解码器部分,其中特征变换部分包含了由细节增强卷积(DEConv)和内容引导注意力(CGA)组成的细节增强注意力块(DEAB)。
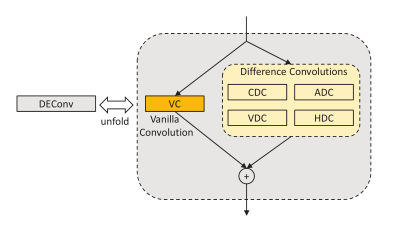
(1)细节增强卷积DEConv使用了5个卷积层(4个difference卷积和1个vanilla卷积),vanilla卷积用于获得强度级别信息,而difference卷积用于增强梯度级别信息,二者并行部署用于特征提取,将先验信息整合到CNN中,提高表示能力。
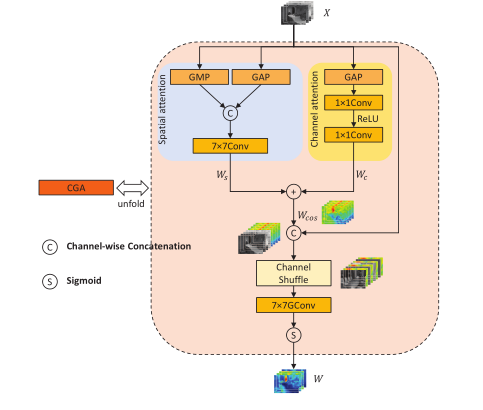
(2)内容引导注意力 (CGA)为每个channel分配独特的空间重要性图(SIM),先生成SIM的粗版本,再通过输入特征的引导来细化每个信道,充分混合通道注意力权重和空间注意力权重保证信息交互。
(3)CGA-based Mixup Fusion Scheme(基于CGA的混合融合方案)通过学习空间权重将编码器部分中的低级特征与相应的高级特征自适应地融合,能有效融合特征并帮助梯度流动。
5、 【ARXIV2212】DAE-Former: Dual Attention-guided Efficient Transformer for Medical Image Segmentation
论文:https://arxiv.org/abs/2212.13504
代码:https://github.com/mindflow-institue/daeformer
本文贡献:(1)用于捕获空间和通道信息的双注意力机制;(2)用于自适应融合编码器和解码器特征的 skip connection cross attention (SCCA);(3)提出了用于医学图像分割的U-Net形的分层transformer结构DAE-Former。
DAE-Former的整体框架
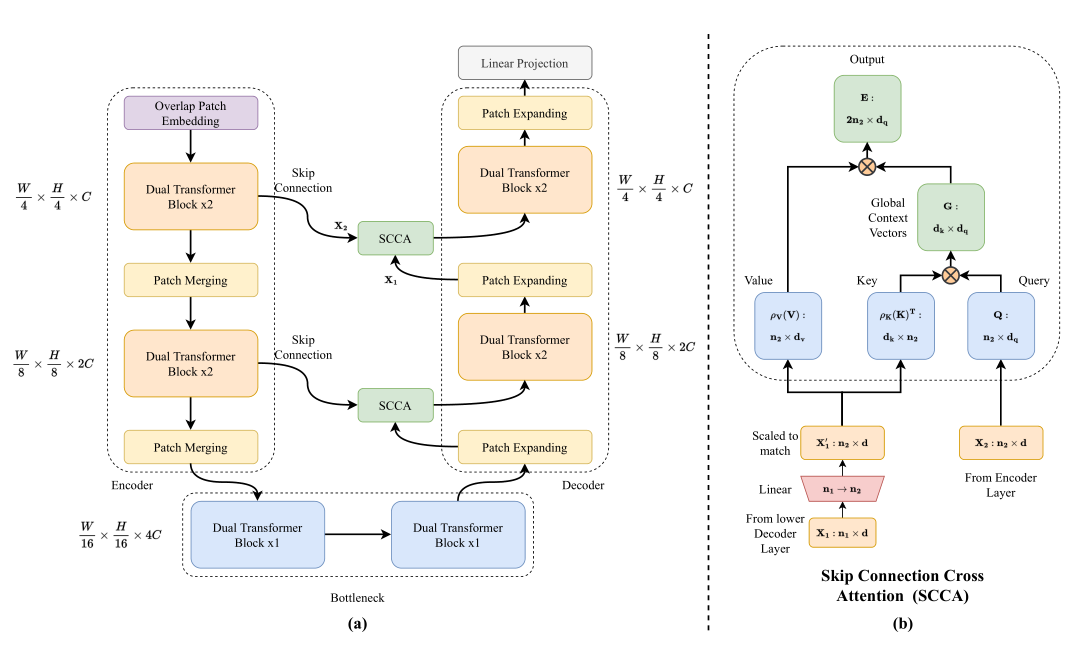
DAE-Former的编码器和解码器都是由3个块组成的U-Net形式。
(1)Dual Attention Block
双重注意力部分由Efficient attention 和Channel attention两部分组成。
Efficient attention的公式如下,其中 ρq 和 ρk 是查询和键的规范化函数,极大地降低了注意力机制的计算复杂性。
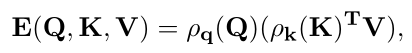 Channel attention也就是transpose attention,能有效捕获完整的通道维度:
Channel attention也就是transpose attention,能有效捕获完整的通道维度:
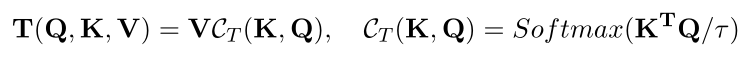 Efficient Dual Attention由一个有效的注意块+Norm&FFN和一个通道注意块+Norm&FFN组成来实现空间和通道注意力
Efficient Dual Attention由一个有效的注意块+Norm&FFN和一个通道注意块+Norm&FFN组成来实现空间和通道注意力
(2)Skip Connection Cross Attention
SCCA交叉关注编码器和解码器的特征,有效地为每个解码器提供空间信息,以便在生成输出掩码时恢复细粒度的细节,确保特征的可重用性并提高定位能力。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 按钮权限的设计及实现