第五次学习
一、论文阅读
1、《Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising》
论文链接:https://arxiv.org/pdf/1608.03981.pdf
这篇论文主要是介绍了用于图像去噪的DnCNN模型。
重要特点:
①DnCNN模型使用residual learning(残差学习)和batch normalization(批量标准化)的结合,加快训练速度,提升去噪性能;
②DnCNN模型可以用于处理未知level的高斯噪声,实现盲去噪;
③DnCNN模型致力于使用一个单模型去处理未知高斯噪声、多尺度超分辨和未知QF的JPEG图像去块问题。
网络结构:
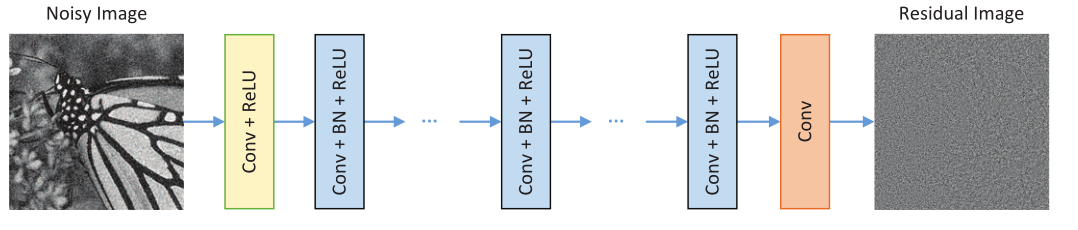
作者修改了VGG网络,将卷积滤波器的大小设置为3×3,删除了所有池化层;设置感受野大小为35×35,特定高斯去噪深度为17,其余去噪深度为20。
i)Conv(64×3×3×c)+ReLU,c表示图像通道的数量,1是灰度图像,3是彩色图像
ii)Conv(64×3×3×64)+BN+RELU
iii)Conv(3×3×64)
每一层卷积都产生64个通道,最后输出单通道的灰度图像(残差图片),最后作者每一层都在卷积前zero padding,以确保中间层的每个feature map与输入图像的大小相同。
残差学习和批量标准化:

作者通过实验发现,SGD和Adam梯度优化算法对实验结果的影响不大,主要影响还是残差学习和批量标准化的结合。
内部协变量移位(internal covariate shift):深层神经网络在做非线性变换前的激活输入值,随着网络深度加深或者在训练过程中,其分布逐渐发生偏移或者变动,之所以训练收敛慢,一般是整体分布逐渐往非线性函数的取值区间的上下限两端靠近,导致反向传播时低层神经网络的梯度消失,这是训练深层神经网络收敛越来越慢的本质原因。
批量标准化(batch normalization):就是通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正态分布,即把越来越偏的分布强制拉回比较标准的分布。
实验结果:
(1)DnCNN模型的去噪性能非常优越,不仅能恢复锐边和精细细节,而且在平滑区域内也能获得良好的视觉效果。
(2)DnCNN模型CPU运行速度上处于中上水准。
(3)DnCNN模型使用单模型完成三个任务是可行的,且去噪性能很不错。
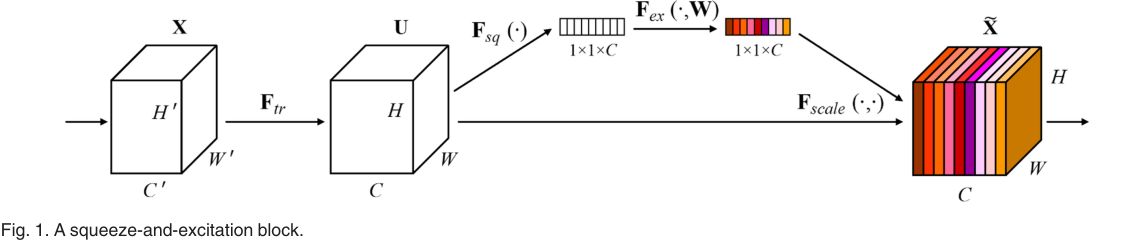
Ftr是标准卷积操作,U是该卷积的输出(C个大小为H*W的feature map),Uc表示U中的第c个feature map,公式如下:

SENet增加的是后面的部分,首先是Fsq的squeeze过程,也就是global average pooling,将H*W*C的输入转换为1*1*C的输出,这么做的原因是将空间信息压缩成一个值,从而更方便计算通道间的相关性:

接下来是Fex的excitation操作,也就是两个全连接层(公式中的W1将C个通道压缩成C/r个通道,W2再回到C个通道)用于融合各个通道的信息,后面跟着个sigmoid函数:
![]()
最后是Fscale的channel-wise multiplication,将所获得的权重值乘回输出U:
![]()
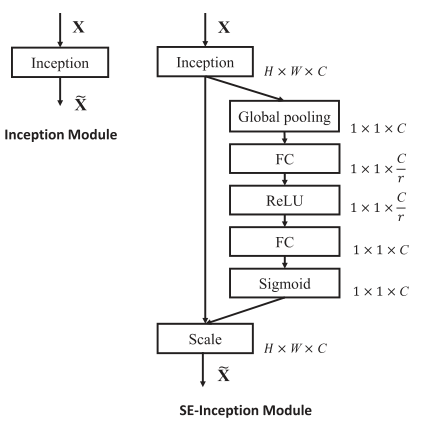
SE block可以被直接添加到别的网络架构上,如下所示:

实验结果:
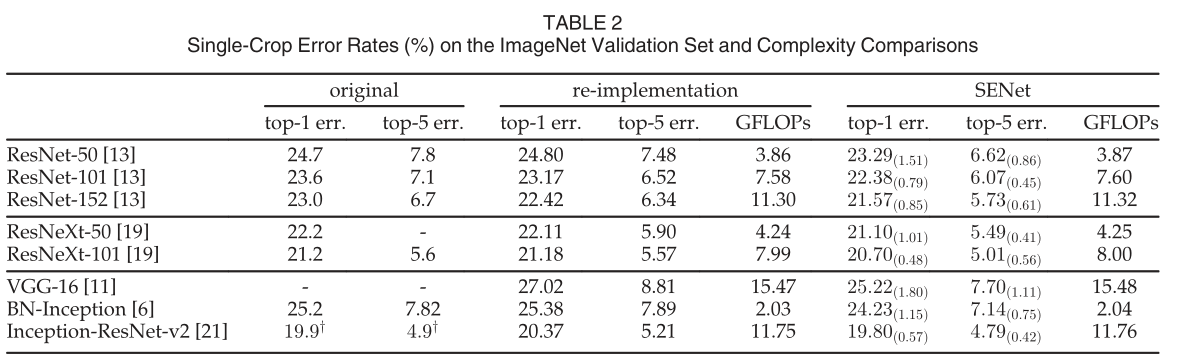
图像分类:基于ImageNet 2012的数据集,可以看出SENet的错误率更低,复杂性有轻微的提高。
场景分类:验证错误相较于ResNet-152有较低的错误率,说明也可以改进场景分类。
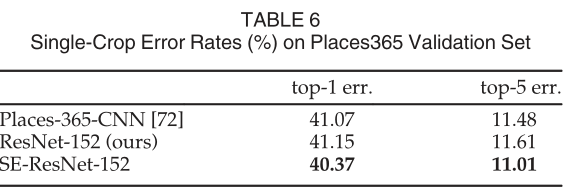
目标检测:基于COCO数据集,分别提高了2.4%和2%,证明了SE 模块的通用性。
3、《Convolutional Block Attention Module》
论文链接:https:/arxiv.org/pdf/1807.06521.pdf
这篇文章提出了attention机制,使用channel attention和spatial attention来增强特征表达。
网络架构:
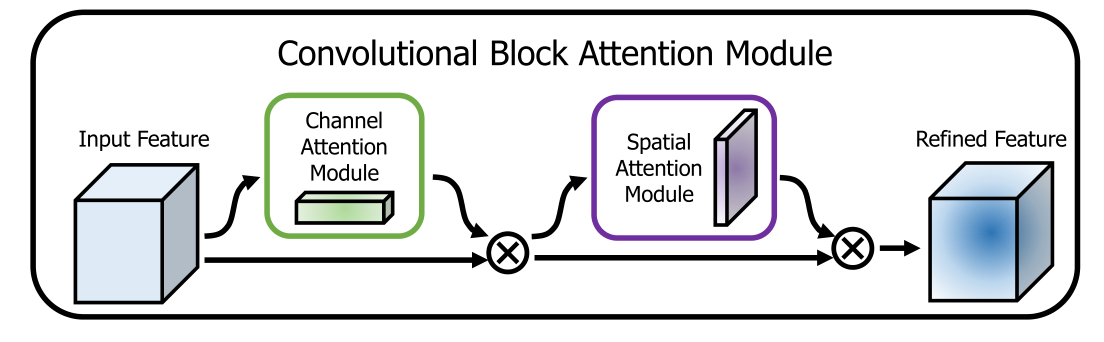
对于输入的特征先进行channel attention,再进行spatial attention。
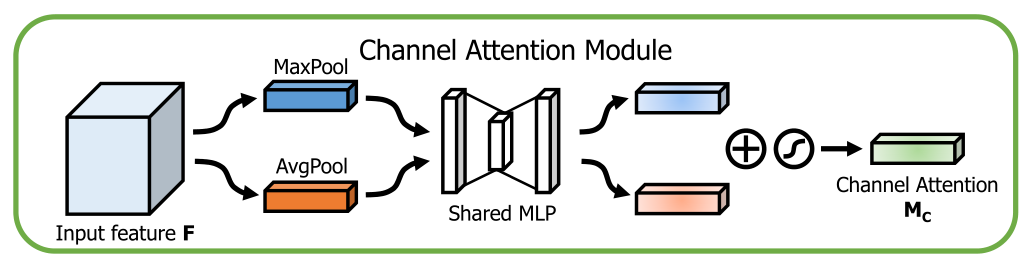
对于channel attention模块,将原始的feature map分别进行global max pooling和global avg pooling聚合信息,送到共享的MLP(多层感知器)按照r进行压缩空间维数,最后进行element-wise summation求和和sigmoid函数处理。公式如下:

![]()

对于spatial attention模块,使用1×1的global max pooling和1×1的global avg pooling进行压缩操作,连接起来后进行7*7的卷积操作,最后使用sigmoid函数。公式如下:
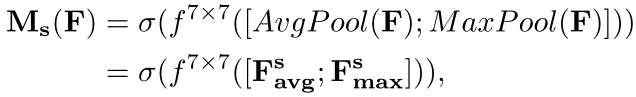
架构设置依据:
(1)通过实验对比,发现max pooling+avg pooling的实验结果比单独使用效果好

(2)在空间注意力模块使用avg pooling&max pooling+7*7的卷积得到的性能最好
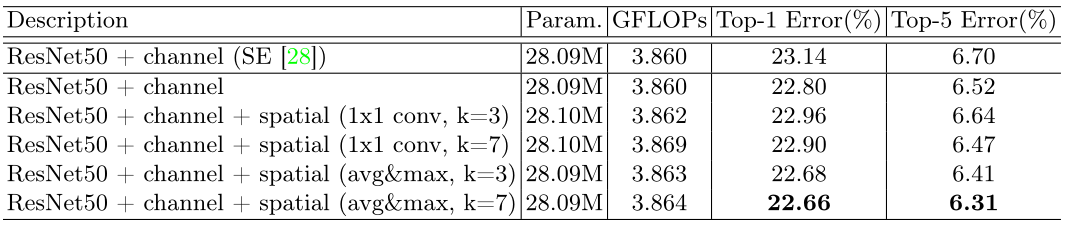
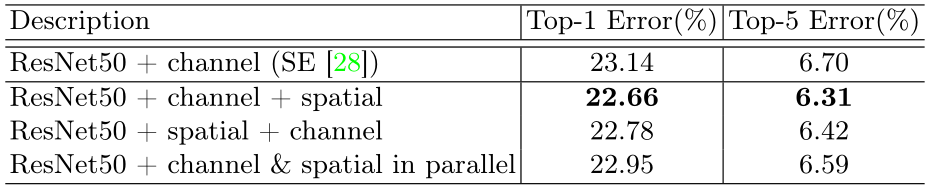
(3)通过实验发现串联两个attention模块的效果要优于并联,channel attention放在前面要优于spatial attention放在前面。
实验结果:
(1)嵌入CBAM的图像分类结果比嵌入SE模块的性能要好
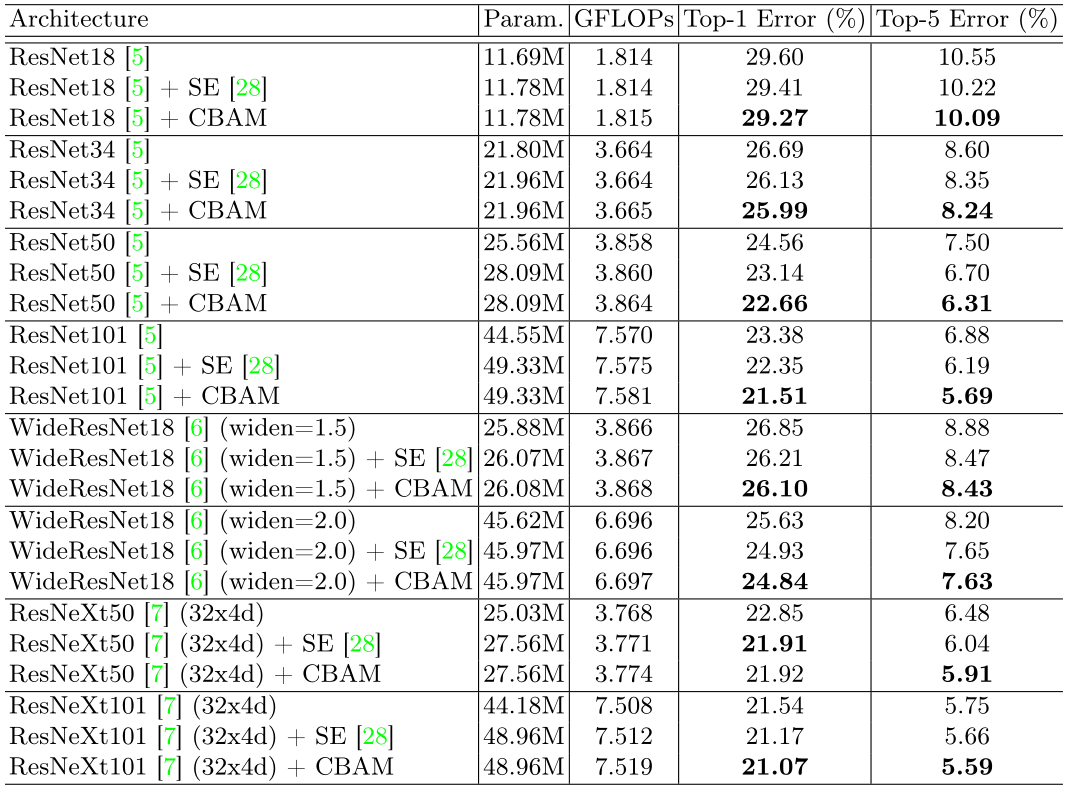
(2)图像可视化任务中,CBAM可以精准地推断出给定图像
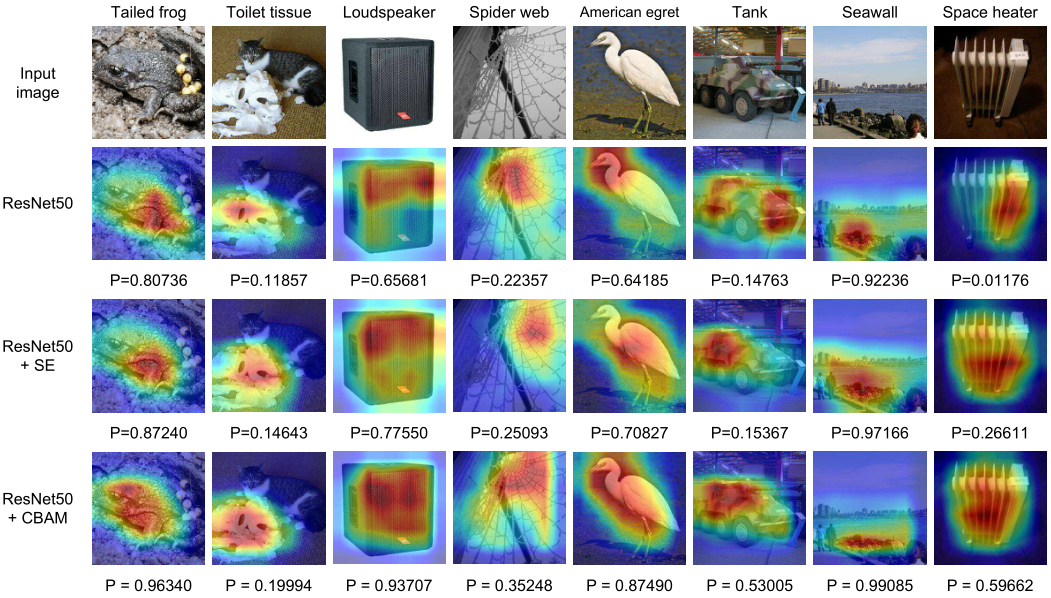
4、遇到问题
(1)网络层数是d的时候,网络的感受野为什么是(2d+1) * (2d+1)?

感受野计算时注意的三点:①第一层卷积层的输出特征图像素的感受野的大小等于滤波器的大小;②深层卷积层的感受野大小和它之前所有层的滤波器大小和步长有关系;③计算感受野大小时,忽略了图像边缘的影响,即不考虑padding的大小
对于单层卷积网络,其feature map上每个特征点对应原图上的感受野大小等于卷积层滤波器的大小;对于多层卷积网络,可由此逐层往回反馈,通过反复迭代获得原始输入图像中感受野大小,即后面深层的卷积层感受野大小和之前所有网络层的滤波器大小和步长有关,在计算的时候,忽略图像Padding的大小。使用的公式可以表示如下:r(i) = (r(i+1) - 1) * stride(i) + c(i),其中,r(i)表示第i层感受野大小,stride(i)表示第i层步长,c(i)表示第i层卷积核大小。同时,激活函数层感受野迭代公式:r(i)=r(i+1)
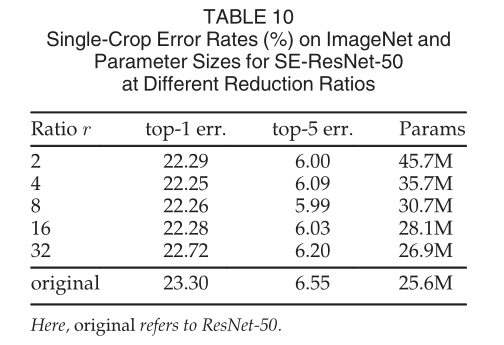
(3)为什么两层FC之间加入ReLU?
两层FC:①降低一层FC的参数量;②降低过拟合的可能性;
加入ReLU:①具有更多的非线性,可以更好地拟合通道间复杂的相关性;②通道间相关性不独立,所以经过压缩可以提取更精确的通道间的关联;③减少了参数量和计算量;
import torch import torch.nn as nn import torch.nn.functional as F class PreActBlock(nn.Module): def __init__(self, in_planes, planes, stride=1): super(PreActBlock, self).__init__() self.bn1 = nn.BatchNorm2d(in_planes) self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=3, stride=stride, padding=1, bias=False) self.bn2 = nn.BatchNorm2d(planes) self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=1, bias=False) if stride != 1 or in_planes != planes: self.shortcut = nn.Sequential( nn.Conv2d(in_planes, planes, kernel_size=1, stride=stride, bias=False) ) # SE layers,此处的16是redution rote的r self.fc1 = nn.Conv2d(planes, planes//16, kernel_size=1) self.fc2 = nn.Conv2d(planes//16, planes, kernel_size=1) def forward(self, x): out = F.relu(self.bn1(x)) shortcut = self.shortcut(out) if hasattr(self, 'shortcut') else x out = self.conv1(out) out = self.conv2(F.relu(self.bn2(out))) # Squeeze w = F.avg_pool2d(out, out.size(2)) w = F.relu(self.fc1(w)) w = F.sigmoid(self.fc2(w)) # Excitation out = out * w out += shortcut return out class SENet(nn.Module): def __init__(self, block, num_blocks, num_classes=10): super(SENet, self).__init__() self.in_planes = 64 self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False) self.bn1 = nn.BatchNorm2d(64) self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1) self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2) self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2) self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2) self.linear = nn.Linear(512, num_classes) def _make_layer(self, block, planes, num_blocks, stride): strides = [stride] + [1]*(num_blocks-1) layers = [] for stride in strides: layers.append(block(self.in_planes, planes, stride)) self.in_planes = planes return nn.Sequential(*layers) def forward(self, x): out = F.relu(self.bn1(self.conv1(x))) out = self.layer1(out) out = self.layer2(out) out = self.layer3(out) out = self.layer4(out) out = F.avg_pool2d(out, 4) out = out.view(out.size(0), -1) out = self.linear(out) return out def SENet18(): return SENet(PreActBlock, [2,2,2,2]) net = SENet18() y = net(torch.randn(1,3,32,32)) print(y.size()) print(net)
2、CBAM代码
channel attention
class ChannelAttention(nn.Module): def __init__(self, in_planes, ratio=16): super(ChannelAttention, self).__init__() self.avg_pool = nn.AdaptiveAvgPool2d(1) self.max_pool = nn.AdaptiveMaxPool2d(1) self.fc1 = nn.Conv2d(in_planes, in_planes // 16, 1, bias=False) self.relu1 = nn.ReLU() self.fc2 = nn.Conv2d(in_planes // 16, in_planes, 1, bias=False) self.sigmoid = nn.Sigmoid() def forward(self, x): avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x)))) max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x)))) out = avg_out + max_out return self.sigmoid(out)
spatial attention
class SpatialAttention(nn.Module): def __init__(self, kernel_size=7): super(SpatialAttention, self).__init__() assert kernel_size in (3, 7), 'kernel size must be 3 or 7' padding = 3 if kernel_size == 7 else 1 self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False) self.sigmoid = nn.Sigmoid() def forward(self, x): avg_out = torch.mean(x, dim=1, keepdim=True) max_out, _ = torch.max(x, dim=1, keepdim=True) x = torch.cat([avg_out, max_out], dim=1)#cat是将两个张量(tensor)拼接在一起,cat是concatnate的意思,即拼接,联系在一起。 x = self.conv1(x) return self.sigmoid(x)
https://blog.csdn.net/u014380165/article/details/78006626

 浙公网安备 33010602011771号
浙公网安备 33010602011771号