


猫狗大战挑战赛
VGG实现猫狗分类
1、导入数据和解压数据
! wget http://fenggao-image.stor.sinaapp.com/dogscats.zip! unzip dogscats.zip ! wget https://static.leiphone.com/cat_dog.rar! unrar x cat_dog.rar
分别导入AI研习社的数据和老师给的数据,本来想本地导入,由于太卡,上传了一个小时没上传到google网盘,网盘还一直掉线,因此放弃,下载了两组数据。dogscats数据中的train和val分别有cat和dog的文件夹,因此选用dogscats的数据做实验。
2、设置transform函数,将AI研习社的test文件夹提取到同一个文件夹下,用ImageFolder提取相应路径下的数据并设置bitch_size,考虑到VGG的输入为224*224,所以要将图片裁剪为224*224;提取数据长度dest_sizes,存储类别信息train_classes。
#组合多个函数 transform=transforms.Compose([ transforms.CenterCrop(224),#考虑到VGG的输入为224*224,对原始图片进行裁剪 #transforms.RandomHorizontalFlip(),#随机左右翻转 transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225])])
#!ls "/content/cat_dog/train" #print(os.listdir()) #训练时可以打乱顺序增加多样性,测试时没有必要,所以shuffle=False
3、下载ImageNet的json文件,使用训练好的VGG16模型进行预测,最后用softmax进行处理。使用json.load()来读取imagenet文件,将输入数据model后再softmax,展示识别结果,由于我的batch_size设置为64,图片也就小了点,结果也就多了点。
!wget https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json model_vgg=models.vgg16(pretrained=True) #找到这个结果预测的是哪个类别,最简单的可以找向量中最大的那个值,然后找出所对应的类别: with open('./imagenet_class_index.json') as f: #print(json.load(f)) class_dict = json.load(f) print(class_dict) dic_imagenet = [class_dict[str(i)][1] for i in range(len(class_dict))] inputs_try,labels_try = inputs_try.to(device),labels_try.to(device) model_vgg = model_vgg.to(device) outputs_try = model_vgg(inputs_try) print(outputs_try) print(outputs_try.shape)

4、在这里使用 nn.Linear 层将结果的1000类替换为2类,model_vgg_new.parameters()是返回一个每次生成的是Tensor类型的数据的迭代器,设置 required_grad=False冻结前面层的参数。定义优化模型和损失函数。vgg.features是取出vgg16网络中的features大层。其中vgg网络可以分为3大层,一层是(features),一层是(avgpool),最后一层是(classifier),vgg.classifiwe._modules是将取出来的网络转为字典显示。
5、训练模型
def train_model(model,dataloader,size,epochs,optimizer): model.train() for epoch in range(epochs): running_loss = 0.0 running_corrects = 0 count = 0 for inputs,classes in dataloader: inputs = inputs.to(device) classes = classes.to(device) outputs = model(inputs) loss = criterion(outputs,classes) optimizer = optimizer optimizer.zero_grad() loss.backward() optimizer.step() _,preds = torch.max(outputs.data,1) # statistics running_loss += loss.data.item() running_corrects += torch.sum(preds == classes.data) count += len(inputs) print('Training: No. ', count, ' process ... total: ', size) epoch_loss = running_loss / size epoch_acc = running_corrects.data.item() / size print('Loss: {:.4f} Acc: {:.4f}'.format(epoch_loss, epoch_acc)) # 模型训练 train_model(model_vgg_new,trainloader,size=dset_sizes['train'], epochs=1, optimizer=optimizer_vgg)
训练结果:
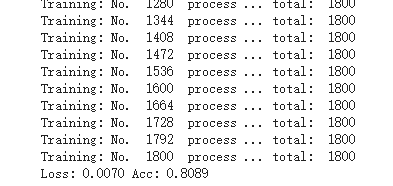
6、测试val
def test_model(model,dataloader,size): model.eval() predictions = np.zeros(size) all_classes = np.zeros(size) all_proba = np.zeros((size,2)) i = 0 running_loss = 0.0 running_corrects = 0 for inputs,classes in dataloader: inputs = inputs.to(device) classes = classes.to(device) outputs = model(inputs) loss = criterion(outputs,classes) _,preds = torch.max(outputs.data,1) # statistics running_loss += loss.data.item() running_corrects += torch.sum(preds == classes.data) predictions[i:i+len(classes)] = preds.to('cpu').numpy() all_classes[i:i+len(classes)] = classes.to('cpu').numpy() all_proba[i:i+len(classes),:] = outputs.data.to('cpu').numpy() i += len(classes) print('Testing: No. ', i, ' process ... total: ', size) epoch_loss = running_loss / size epoch_acc = running_corrects.data.item() / size print('Loss: {:.4f} Acc: {:.4f}'.format(epoch_loss, epoch_acc)) return predictions, all_proba, all_classes predictions, all_proba, all_classes = test_model(model_vgg_new,valloader,size=dset_sizes['val'])
测试结果:
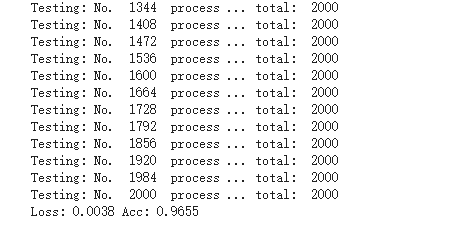
7、测试test
predictions2,all_proba2,all_classes2=test_model(model_vgg_new,testloader,size=dset_sizes['test'])
测试结果:此处的0.4870不能看做是test的准确率,因为test里面没有cat和dog的标签,所以这个数值是不准确的。
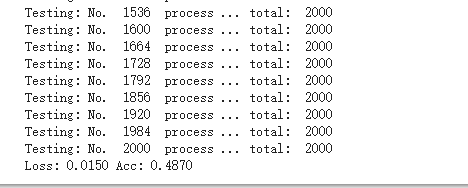
将图片序号和预测结果导入为csv文件后再进行排序,在AI研习社的结果为:

8、遇到问题:
(1)导入AI研习社下载链接后,使用unzip解压失败,针对.rar压缩文件应该使用unrar
(2)读取文件时出现找不到子文件的错误,但是路径格式我确定自己没有填写错误,后来发现ImageFolder的root针对的格式是这样的:如果路径是cat_dog/train/1.jpg,填写的路径要是cat_dog才是正确答案。我导入的大赛的数据有三个文件夹train、test、val,每个文件夹下面没有更多的文件夹,直接是图片,这就导致按照正确格式读取只能将三个文件夹的数据一起读取。通过纠结考虑只有两个办法:①在每个文件夹下面分别建cat和dog文件夹,才能分别读取train、test、val;②换个下载路径。更换下载路径后代码正确。
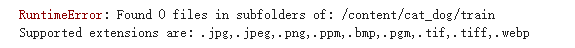
(3)源代码中训练函数的参数是固定的,不利于后期的修改,尤其是optimizer没有使用设置好的梯度下降优化函数

(4)下载csv提交时,出现正确率为50%的情况。原因是我没有意识到图片序号的重要性,直接按照图片在test下的顺序设置了range序列,这样的结果是不正确的。

那为什么结果是50%左右呢?由于test里面没有cat和dog的分类,所以分类的标签为0,也就是说测试集中猫是正确,狗是错误,50%的意思是统计了猫在数据集中的数量占比
9、优化
(1)提高训练次数

(2)使用Adam函数,提高学习率


