


数学基础+卷积神经网络学习
一、视频学习反思
1、神经网络基础(续)
(1)自编码器变种:正则自编码器(乘法大权重的L2正则化)、稀疏自编码器(限制神经元平均激活度在很小的值、KL散度)、去燥自编码器(提取鲁棒特征表达)、变分自编码器(隐含空间Z)
(2)局部极小值主要是多个隐层复合函数导致的(凸函数指的是二阶导数的符号大于0)、逐层预训练是为了增加扰动能够跳出鞍点
2、数学基础学习
(1)矩阵线性变换:秩度量矩阵行的相关性,若各行各列线性无关,矩阵是满秩的。数据分布模式越容易被捕捉,基越少,秩越小;数据冗余度越大,基越少,秩越小;结构化信息中相关性越强,秩越小。
低秩近似:保留决定数据分布的最主要的模式。矩阵分解为低秩矩阵(结构信息)和稀疏矩阵(噪声)
启发式优化:随着变量个数增加,复杂度提高很快,效率比梯度下降低,但是擅于处理局部极值的问题
模型:条件概率、决策函数建模
策略:极大似然估计、经验风险最小化
(2)策略设计:追求泛化性能
泛化误差:在符合真实数据分布下,对损失函数求期望(分类01损失函数、回归平方损失函数)
训练误差:模型在训练样本上的平均损失
泛化错误=泛化误差-训练误差
当泛化错误和训练误差都小时,泛化误差小
重要定理:
①无免费午餐定理:没有任何一个模型在所有的学习任务里表现最好
②奥卡姆剃刀原理:简单有效原理。最小结构风险包括经验风险和模型复杂度;最大后验概率包括模型的似然和模型的先验(简单模型是大概率事件)。
欠拟合:训练集的一般性质尚未被学习器学号。(训练误差大)
过拟合:学习器把训练集特点当做样本的一般特点(训练误差小,测试误差大)
(3)损失函数:①sigmoid函激活函数;②特征和输出的差别(BP反向传播梯度下降优化算法)③平方损失(输入层用了ReLU函数,输出层是softmax回归,仍然是sigmoid函数),可用交叉熵(对数损失函数)替代平方损失
(4)对随机事件发生的可能性的不同解读促成了频率学派和贝叶斯学派
频率学派:关注可独立重复的随机试验中单个事件发生的频率,通过唯一的参数模型估计频率,对应极大似然估计
贝叶斯学派:关注无法重复的随机事件的可信程度,模型参数本身是随机变量,需要估计参数的整个概率分布,对应最大后验估计
(5)因果推断:Yule-Simpson悖论(相关性不可靠),因果性=相关性+忽略的因素
群体智能:目前群智能研究主要包括智能蚁群算法和粒子群算法
3、卷积神经网络
(1)神经网络的应用:分类、检索(选择与给定图片相关的图片)、检测(检测物体的位置)、分割(检测+像素上分割)、人脸识别、图像识别(基于对抗网络)、图像风格转化。
深度学习的步骤:搭建神经网络结构、找到合适损失函数(交叉熵损失、均方误差)、找到一个合适的优化函数
由于全连接网络的参数太多,卷积神经网络的局部管理、参数共享可以解决这一问题。
(2)基本组成结构
卷积:卷积是对两个实变函数的一种数学操作。
y=WX+b(W是卷积核或滤波器、X是每次卷积核对应感受野、b是偏置项)
featrue map计算公式:(N+padding*2-F)/stride+1,N为图长,F是过滤器长,padding拓展长,stride是步长。参数量=(F*F+1)*卷积核的个数
池化:缩放过程,保留主要特征同时减少参数和计算量,防止过拟合,提高模型泛化能力。
最大值池化:在感受野上找最大值
平均值池化:在感受野上求平均值
全连接:两层神经元都有权重连接,通常在卷积神经网络尾部
(3)典型结构
①AlexNet:RELU函数加快收敛速度,计算量小,在正轴无梯度消失;DropOut随机失活是指在训练时随即关闭部分神经元;数据增强指的是随机crop或者平移翻转对称、改变RGB通道。
②ZFNet:网络结构与AlexNet相同,只改变了感受野大小、步长和滤波器个数
③VGG:加深网络结构,把层数分为两部分分别训练
④GoogleNet:层数进一步加深,除了最后的分类全连接层之外没有其他的全连接层,参数量大大减少。在inception模块多卷积核增加特征多样性,会使得每一次卷积的channel的个数不断增大,增加了计算量;Inception V2插入1*1卷积核进行降维,Inception V3用小的卷积核替代大的卷积核,降低参数。
⑤ResNet:残差学习网络(deep residual learning network),深度加深到152层,通过去掉相同的主体部分,突出微小的变化,也可以解决梯度消失问题。
4、遇到问题
(1)如下图所示,不能理解为什么左边的数据冗余度低,右边的数据冗余度高:现在仍不理解

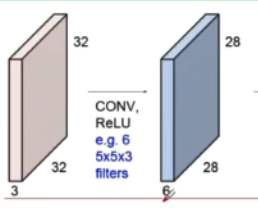
(2)在此处转换时对蓝方块的6不理解:容易知道,(32-5)+1=28,5*5*3的3对应的是紫方块的深度3,蓝方块的深度对应的应该是卷积核的个数6
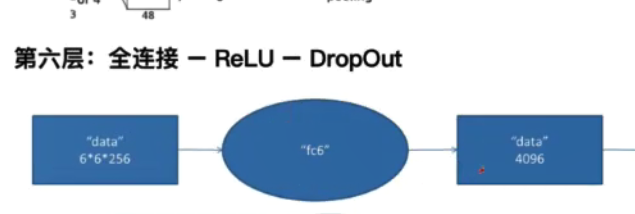
(3)在全连接此处,不能理解为什么6*6*256的数据结果是4096:此处应理解为先将6*6*256先展平为一维向量,再跟4096位的数据进行全连接
二、代码学习
1、卷积神经网络
首先将数据下载到./data下,组合了ToTensor()和Normalize()函数进行变换,随机打乱数据后设置不同的batch_size赋值给测试数据集合训练数据集
#1、加载数据(通过torchivision.datasets可以将MNIST数据集下载到本地) input_size=28*28#MNIST图像尺寸是28x28 output_size=10#分类为0-9,即10类 #transforms.ToTensor()将numpy的ndarray或PIL.Image读的图片转换成形状为(C,H,W)的Tensor格式,且/255归一化到[0,1.0]之间 #transforms.Normalize((0.1307,), (0.3081,))是MNIST的标准化系数 #shuffle是否随机打乱顺序 train_loader=torch.utils.data.DataLoader(datasets.MNIST('./data', train=True, download=True,transform=transforms.Compose( [transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))])),batch_size=64, shuffle=True) test_loader=torch.utils.data.DataLoader(datasets.MNIST('./data', train=False, transform=transforms.Compose([ transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))])),batch_size=1000, shuffle=True)
分别创建全连接网络和卷积神经网络,全连接网络是全连接、ReLU、全连接、ReLU、全连接、softmax,卷积神经网络是卷积、ReLU、最大池化、卷积、ReLU、最大池化、全连接、ReLU、全连接、softmax,之后再定义训练函数和测试函数。
#2、创建网络(继承nn.Module,实现forward方法) class FC2Layer(nn.Module): def __init__(self,input_size,n_hidden,output_size):#这是执行父类构造函数 #下式等价于nn.Module.__init__(self) super(FC2Layer,self).__init__() self.input_size=input_size #直接用Sequential定义网络,要和下面CNN的代码区分开 self.network=nn.Sequential( nn.Linear(input_size,n_hidden), nn.ReLU(), nn.Linear(n_hidden,n_hidden), nn.ReLU(), nn.Linear(n_hidden,output_size), nn.LogSoftmax(dim=1)#维度为1的对softmax求log ) def forward(self,x): # view一般出现在model类的forward函数中,用于改变输入或输出的形状 # x.view(-1,self.input_size)的意思是多维的数据展成二维 # 代码指定二维数据的列数为input_size=784,行数-1表示我们不想算,电脑会自己计算对应的数字 # 在DataLoader部分,我们可以看到batch_size是64,所以得到x的行数是64 x=x.view(-1,self.input_size) return self.network(x) class CNN(nn.Module): def __init__(self,input_size,n_feature,output_size):# 执行父类的构造函数 super(CNN,self).__init__() #一般定义卷积和全连接,池化、ReLU一类的不用在这里定义 self.n_feature=n_feature #输入1通道,输出为10类别,kernel为5*5 self.conv1=nn.Conv2d(in_channels=1,out_channels=n_feature,kernel_size=5) self.conv2=nn.Conv2d(n_feature,n_feature,kernel_size=5) self.fc1=nn.Linear(n_feature*4*4,50) self.fc2=nn.Linear(50,10) #forward函数,定义了网络的结构,按照一定顺序,把上面构建的一些结构组织起来,即conv1,conv2可以多次重用 def forward(self,x,verbose=False):#运行时不显示详细信息 x=self.conv1(x) x=F.relu(x) x=F.max_pool2d(x,kernel_size=2) x=self.conv2(x) x=F.relu(x) x=F.max_pool2d(x,kernel_size=2) x=x.view(-1,self.n_feature*4*4) x=self.fc1(x) x=F.relu(x) x=self.fc2(x) x=F.log_softmax(x,dim=1) return x
在全连接网络上训练
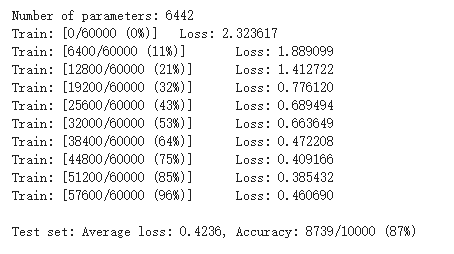
#在小型全连接网络上训练 n_hidden=8 model_fnn=FC2Layer(input_size,n_hidden,output_size) model_fnn.to(device) #使用随机梯度下降优化函数 optimizer=optim.SGD(model_fnn.parameters(),lr=0.01,momentum=0.5) print('Number of parameters: {}'.format(get_n_params(model_fnn))) train(model_fnn) test(model_fnn)
在卷积神经网络上测试
#在卷积神经网络上训练 n_features=6 # number of feature maps model_cnn=CNN(input_size,n_features,output_size) model_cnn.to(device) optimizer=optim.SGD(model_cnn.parameters(), lr=0.01, momentum=0.5) print('Number of parameters: {}'.format(get_n_params(model_cnn))) train(model_cnn) test(model_cnn)

打乱像素顺序再重新定义训练函数和测试函数
#打乱像素顺序再重新训练与测试 perm=torch.randperm(784)#torch.randperm 函数,给定参数n,返回一个从0到n-1的随机整数排列 plt.figure(figsize=(8,4)) for i in range(10): image,_=train_loader.dataset.__getitem__(i) # permute pixels image_perm=image.view(-1,28*28).clone() image_perm=image_perm[:,perm] image_perm=image_perm.view(-1,1,28,28) plt.subplot(4,5,i+1) plt.imshow(image.squeeze().numpy(),'gray') plt.axis('off') plt.subplot(4,5,i+11) plt.imshow(image_perm.squeeze().numpy(),'gray') plt.axis('off') #对每个batch里的数据,打乱像素顺序的函数 def perm_pixel(data, perm): #转化为二维矩阵 data_new=data.view(-1,28*28) #打乱像素顺序 data_new=data_new[:,perm] #恢复为原来4维的tensor data_new=data_new.view(-1,1,28,28) return data_new
使用全连接网络测试:

使用卷积神经网络测试:

总结:通过以上实验,可以发现没打乱像素顺序之前,CNN的效果要优于全连接网络,可以看出卷积和池化的优越性;在打乱像素顺序之后,卷积和池化难以发挥作用,发现全连接的效果优于CNN。
想进一步观察SGD和Adam的效果,选用CNN卷积神经网络作比较,发现Adam着实优秀。
SGD: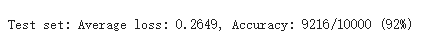
Adam: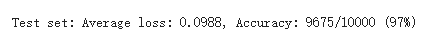
2、CNN处理CIFAR10分类问题
载入数据
#组合ToTensor()和Normalize()函数 transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))]) #训练时可以打乱顺序增加多样性,测试时没有必要,所以shuffle=False trainset=torchvision.datasets.CIFAR10(root='./data',train=True,download=True,transform=transform) trainloader=torch.utils.data.DataLoader(trainset,batch_size=64,shuffle=True,num_workers=2)#使用两个子进程 testset=torchvision.datasets.CIFAR10(root='./data',train=False,download=True,transform=transform) testloader=torch.utils.data.DataLoader(testset,batch_size=8,shuffle=False,num_workers=2)
定义卷积神经网络:卷积、ReLU、池化、卷积、ReLU、池化、全连接、ReLU、全连接、ReLU、全连接
#定义卷积神经网络 class Net(nn.Module): def __init__(self): #对继承自父类的属性进行初始化,用父类的初始化方法来初始化继承的属性 super(Net,self).__init__() self.conv1=nn.Conv2d(3,6,5) self.pool=nn.MaxPool2d(2,2) self.conv2=nn.Conv2d(6,16,5) self.fc1=nn.Linear(16*5*5,120) self.fc2=nn.Linear(120,84) self.fc3=nn.Linear(84,10) def forward(self,x): x=self.pool(F.relu(self.conv1(x))) x=self.pool(F.relu(self.conv2(x))) x=x.view(-1,16*5*5) x=F.relu(self.fc1(x)) x=F.relu(self.fc2(x)) x=self.fc3(x) return x
定义交叉熵损失函数和Adam优化函数,进行训练
#交叉熵损失函数 criterion=nn.CrossEntropyLoss() #Adam优化函数 optimizer=optim.Adam(net.parameters(),lr=0.0001) #训练网络 for epoch in range(10): #重复多轮训练 for i,(inputs,labels) in enumerate(trainloader): inputs=inputs.to(device) labels=labels.to(device) #优化器梯度归零 optimizer.zero_grad() #正向传播+反向传播+优化 outputs=net(inputs) loss=criterion(outputs,labels) loss.backward() optimizer.step() #输出统计信息 if i%100==0: print('Epoch: %d Minibatch: %5d loss: %.3f' %(epoch+1,i+1,loss.item())) print('Finished Training')

数据集预测正确率
#整个数据集的正确率 correct=0 total=0 for data in testloader: images,labels=data images,labels=images.to(device),labels.to(device) outputs=net(images) _,predicted=torch.max(outputs.data,1) total+=labels.size(0) correct+=(predicted==labels).sum().item() print('Accuracy of the network on the 10000 test images: %d %%' %(100*correct/total))

总结:通过这个实验,我更清晰地理解了卷积池化的过程,分别是3channel和6filter、6channel和16filter的卷积,均使用2*2的池化,最后再进行全连接。同时这次实验的网络的forward函数的定义与第一次CNN实验的定义有所不同,但是含义是一样的,从最后的结果可以看出卷积神经网络对CIFAR10数据集分类的预测效果是不太好的。
我有个奇怪的想法,对于优化函数Adam,如果定义的lr从0.001到0.0001会怎么样呢?会发现预测效果是很差的,原来learning_rate指的是学习速率,值越大表示权值调整动作越大。
lr=0.0001
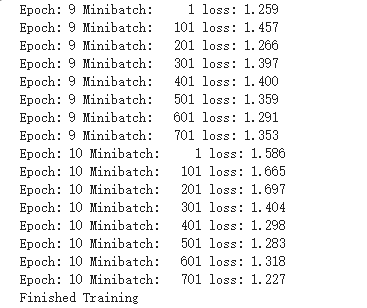

3、使用VGG16对CIFAR10进行分类
先针对训练数据和测试数据进行不同的变换,再加载数据
#训练时组合了多个函数 transform_train=transforms.Compose([ transforms.RandomCrop(32,padding=4),##每边填充4,把32^*32填充至40*40,再随机裁剪 transforms.RandomHorizontalFlip(),#随机左右翻转 transforms.ToTensor(), transforms.Normalize((0.4914,0.4822,0.4465),(0.2023,0.1994,0.2010))]) #测试时组合两个函数 transform_test=transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.4914,0.4822,0.4465),(0.2023,0.1994,0.2010))]) #训练时可以打乱顺序增加多样性,测试时没有必要,所以shuffle=False trainset=torchvision.datasets.CIFAR10(root='./data',train=True,download=True,transform=transform_train) trainloader=torch.utils.data.DataLoader(trainset,batch_size=128,shuffle=True,num_workers=2)#使用两个子进程 testset=torchvision.datasets.CIFAR10(root='./data',train=False,download=True,transform=transform_test) testloader=torch.utils.data.DataLoader(testset,batch_size=128,shuffle=False,num_workers=2)
定义VGG网络,此处的forward函数又是使用了一种新的定义方式,模型由若干卷积层和池化层堆叠而成
class VGG(nn.Module): def __init__(self): super(VGG,self).__init__() self.cfg=[64,'M',128,'M',256,256,'M',512,512,'M',512,512,'M']#64conv/maxpooling/128conv/maxpooling self.features=self._make_layers(self.cfg) self.classifier=nn.Linear(512,10) def forward(self,x): out=self.features(x) out=out.view(out.size(0),-1) out=self.classifier(out) return out def _make_layers(self,cfg): layers=[] in_channels=3 for x in cfg: if x=='M': layers+=[nn.MaxPool2d(kernel_size=2,stride=2)] else: layers+=[nn.Conv2d(in_channels,x,kernel_size=3,padding=1),nn.BatchNorm2d(x),nn.ReLU(inplace=True)] in_channels = x layers+=[nn.AvgPool2d(kernel_size=1,stride=1)] return nn.Sequential(*layers)
运行结果:
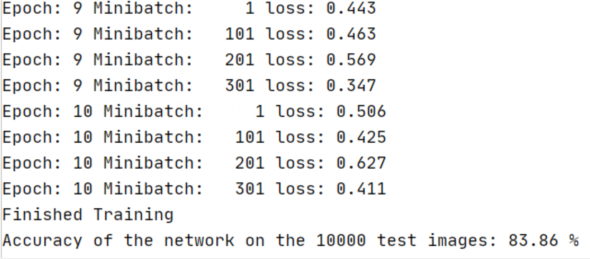
总结:由于自个的电脑配置实在是太低了,跑了一个小时,才跑到第3个epoch,使用别人的电脑用不到五分钟就可以跑完,这坚定了我双十一要买电脑的决心。但是VGG16的正确率较CNN有了很大的提升。
4、遇到问题
(1)此处.cpu()是何含义,毕竟使用的是GPU,应该用cuda?

(2)本来不理解为何此处的fc1的n_feature要*4*4,发现在forward里在全连接前x是*4*4的

(3)本来以为train_lorder和test_lorder都使用了shuffle=True打乱顺序,为什么还要定义打乱顺序函数,后来查资料理解了shuffle打乱的是图片顺序,而定义的函数是打乱像素顺序
(4)不太能理解为什么此处要加转置:plt.imshow(np.transpose(npimg,(1,2,0)))?查阅资料得知,Pytorch中使用的数据格式与plt.imshow()函数的格式不一致,Pytorch中为[Channels, H, W],而plt.imshow()中则是[H,W,Channels],因此,要先转置一下transpose(1,2,0)
(5)VGG16这段代码有报错的地方,首先是将self.features=self._make_layers(cfg)的参数cfg改成self.cfg,然后出现了m1和m2格式不匹配问题,我尝试修改了(1024,10),把他改为(512,10)居然成功了!
(6)VGG网络构建的这段代码感觉有点理解,但是细看每一行代码又不理解。
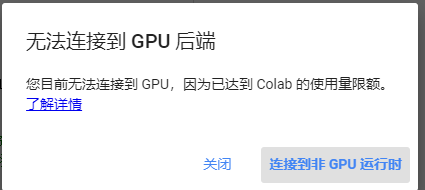
(7)VGG代码运行太慢,石同学说是没在GPU上运行的问题,但是我colab连接不上GPU,百度说是要24小时之后才可以连接
三、实验总结
这次学习数学基础方面匆匆带过,CNN视频那块看了两遍,理论是比较清晰的了。代码学习这块呢,通过全连接、卷积神经网络、VGG16可以学习到如何进行forward函数的卷积、池化等等操作,也可以感受到卷积神经网络的优越性。随着CNN的不断发展,VGG、GoogleNet等等的准确性能也在不断提升,但是对电脑性能的要求也是越来越高。

