

深度学习概念学习+colab初次使用
本周基于两个视频了解深度学习的概念,使用colab进行pytorch基础代码练习,实现螺旋数据分类
1、概念学习
(1)人工智能:使一部机器像人一样进行感知、认知、决策、执行的人工程序或系统。(达特茅斯会议标志AI的诞生)
人工智能的三个层面:①计算智能;②感知智能;③认知智能;
人工智能>机器学习>深度学习
(2)机器学习三个要素:模型(问题建模)、策略(确定目标函数)和算法(求解模型参数)
针对模型而言:
数据标记:监督学习、无监督学习、半监督学习、强化学习
数据分布:参数模型、非参数模型
建模对象:生成模型、判别模型
(3)深度学习
感知器(Perceptron)是第一个具有自组织自学能力的数学模型。
BP算法由Hinton和David Rumelhart第一次系统阐述,增加了隐层(hidden layer),解决了异或(XOR)难题。
卷积神经网络(CNN)最初由Lecun用于开发商业软件。
GPU在最底层的算术逻辑单元基于单指令多数据流(Single Instruction Multiple Data)的架构,可以并行处理大量数据,运行速度比传统双核CPU快得多。
修正线性单元(RELU):对于特定的输入,统计上有一半神经元是没有反应,保持沉默的。优点是识别错误率普遍更低。
长短期记忆(LSTM):通过内在参数的设定,决定输入信息何时取出和何时废弃。
(4)神经网络发展
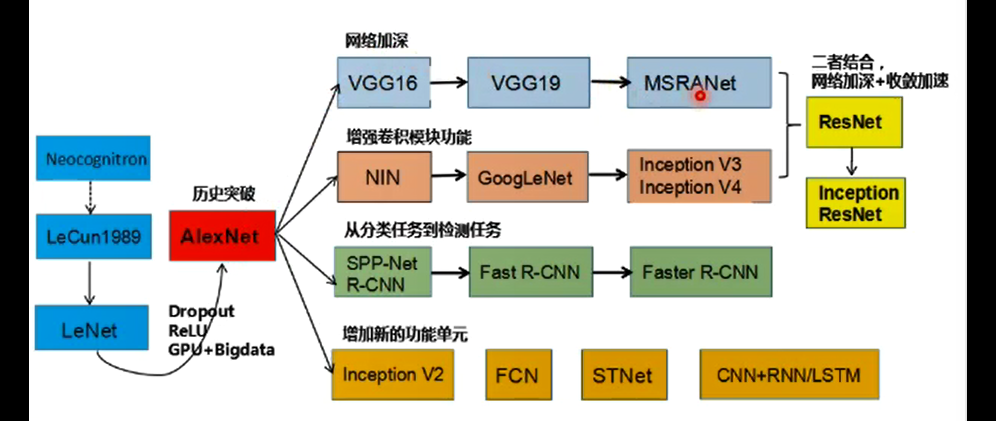
(5)深度学习应用(图像多媒体研究)
视觉:特征提取、物体检测、语义标注、实体标注(神经网络的应用大幅提升了准确率)
语言:描述生成、多媒体问答、多媒体叙事
深度学习的特点:
①算法输出不稳定,容易被攻击
②模型复杂度高,可调试性差
③模型层级复合程度高,参数不透明
④端到端训练方式对数据依赖性强,模型增量性差
⑤专注直观感知类问题,推理能力差
⑥人类知识无法有效引入进行监督,存在机器偏见
符号主义(以逻辑为核心、知识图谱)、连接主义(以统计为核心、深度学习)
(6)浅层神经网络
生物神经元与神经网络相关点:
①每个神经元都是一个多输入单输出的信息处理单元——>多个输入信号
②神经元具有空间整合和时间整合特性——>信号进行累加整合
③神经元输入分兴奋性输入和抑制性输入两种类型——>权值wi正负模拟兴奋抑制,大小模拟强度
④神经元具有阈值特性——>输入和超过阈值,神经元被激活,如果没有激活函数f,就相当于矩阵相乘,只能拟合线性函数
单层感知器:线性激活函数g(z)=z+非线性激活函数 可用于与或非的逻辑的实现,从而实现分类任务
多层感知器:三层感知器实现同或门
万有逼近定理:如果一个隐层包含足够多的神经元,三层前馈神经网络(输入-隐层-输出)能以任意精度逼近任意预定的连续函数。当隐层足够宽时,双隐层感知器(输入-隐层1-隐层2-输出)可以逼近任意非连续函数。
误差反向传播:多层神经网络(符合的非线性多元函数),第一层的输出作为第二层的输入...,通过给定的训练数据,希望误差尽可能小。如果误差较大,让误差反向传播(回传),重新调整神经元的权重,回传和更新的机制利用的是梯度。
梯度:多元函数在每个点可以有多个方向,每个方向可计算相应方向导数,梯度是一个向量,方向是最大方向导数的方向,模是方向导数最大值。
无约束优化:梯度下降。参数沿负梯度方向更新可以使函数值下降。
梯度消失:深度增加会造成误差无法准确反向传播无从查,会造成梯度消失;多层网络容易陷入局部极值,难以训练。所以尽量不使用sigmoid函数。
(7)神经网络基础
逐层预训练(layer-wise pre-training):由于局部极小值(会随着层数增加而成倍增长)和梯度消失两个问题,每次训练一层,逐层累加,在最后一层加上监督信息,从上到下微调。
受限玻尔兹曼机(RBM、无监督逐层预训练):两层神经网络,包含可见层v(输入层)和隐藏层h,二分图式连接。通过p(h|v)和p(v|h)两个条件概率可以使得计算的v'和原来的v分布一致。玻尔兹曼来自于物理的能量分布。
自编码器(无额外的监督的逐层预训练):假设输出输入相同,将input输入一个encoder编码器,就会得到一个code,加一个decoder解码器,输出信息。调整编码器和解码器的参数,使重构误差最小。
2、Pytorch代码试运行
Pytorch提供了GPU加速的张量计算和构建在反向自动求导系统上的深度神经网络。
torch.tensor()可以创建一个张量,创建Tensor有多种方法,包括:ones, zeros, eye, arange, linspace, rand, randn, normal, uniform, randperm
pytorch的运算种类包括基本运算、布尔运算和线性运算、
基本运算: abs/sqrt/div/exp/fmod/pow ,及一些三角函数 cos/ sin/ asin/ atan2/ cosh,及 ceil/round/floor/trunc
布尔运算: gt/lt/ge/le/eq/ne,topk, sort, max/min
线性计算: trace, diag, mm/bmm,t,dot/cross,inverse,svd
通过代码的试运行,比较之前在anaconda3使用的jupyter notebook,在代码的书写和UI的交互上,两者相差不大,但是jupyter notebook的库的使用相当繁琐,第一次用的库都要去anaconda prompt中conda install,很多时候安装还会找不到路径,而colab的内容存放在google drive里,安装和使用相当便捷。
3、螺旋数据分类
当使用线性模型分类时:

当使用两层神经网络分类时:

两段代码的区别在于建立模型时神经网络分类加了一个ReLU激活函数,当仍然使用梯度下降优化算法时两者的正确率都在50%左右。仔细研究代码,发现在神经网络分类时,其optim应该使用的是Adam优化神经网络,从而使得正确率大幅提高到96%。
4、学习总结
就视频学习而言,我认识了机器学习、深度学习和神经网络的相关概念;通过代码练习,我掌握了如何定义数据和计算数据,也初步了解到线性模型分类和神经网络分类的步骤以及二者之间的差异。
