MIT6.824 spring21 Lab2A总结记录
写在前面
这是我第一次写博客,主要是为了记录自己在做MIT6.824 Lab的过程中的实现设计,防止以后忘记。
其实之前做完6.828的时候就想写了来着,但是还是由于种种原因搁置了(其实是因为懒。。。)
这次下定决心,主要是因为完成这次实验花了相当久的时间,修改了好几版才想出现在的版本。
在基本逻辑实现之后又排除掉了很多race和goroutine leakage的问题。总觉得不记录下来,以后全都忘掉太亏了(😂)
我跑了50次test,都通过了。代码正确性应该没有问题。但是很多地方都有冗余(毕竟是一遍一遍修改出来的。。。),还可以改的更精简。
如果你在看,请多多包涵!
整体结构
---------------------------------------------注意:整体结构在2B/2C中有较大调整!-------------------------------------------------------
主要调整的部分是蓝色线消息通知的部分。详见Lab2B/2C总结记录。
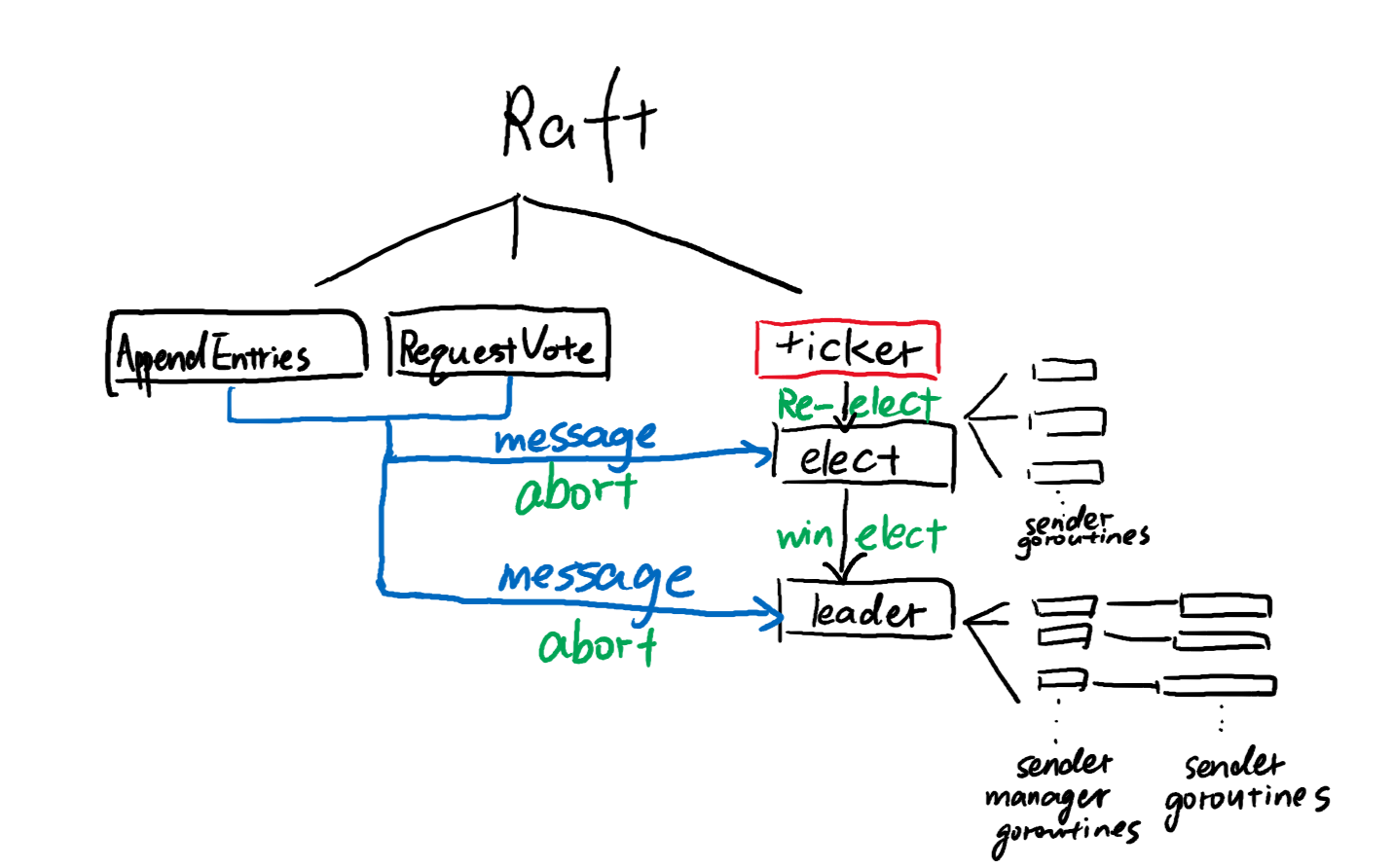
实现的整体结构大概就是这样。图中的每个框框都表示一个goroutine,对应着一个函数。
左边的两个框框是两个RPC Handler。
红色的框框(ticker)表示说这个goroutine不会终止。它将在死循环中永远执行。
蓝色的messge表示channel。两个RPC handler通过*非阻塞的*channel,向elect()和leader()这两个gouroutine发送终止信号。
绿色的字表示相关的箭头的发生时机,这个后面会加以详细解释。
状态(State)
在开始描述各个函数之前,让我先来讲一讲Raft状态的表示。
为了方便起见,我在Raft struct中维护了一个枚举类型的状态变量state。它一共有三种取值:follower/candidate/leader.
值得一提的是,这个变量的维护(防止race)是一件比较麻烦的事情。在这次实验的整体逻辑完成之后,我也的确花了不少的时间来找出潜在的race。
(虽然我觉得我把race都找出来了,但可能实际上还是有。。。分布式嘛。
解决race问题的主要指导思想就是:
在raft执行的整个过程中,只有elect和leader这两个goroutine可以修改rf.state。
这里主要想记录一下go中枚举类型的表示方法。
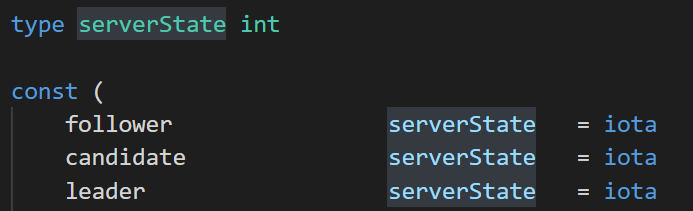
golang里面是没有枚举变量这种东西的。所以要表示枚举变量,就需要通过间接的方式实现。
上面图中的代码是写在所有函数定义最前面的。这里定义了serverState类型(int的别名)。
在const声明中,我们看到了iota这个表达式。它可以从1开始自动递增。因此这里follower就等于1,后面的以此类推。
在定义了枚举类型之后,我们可以继续向下了。
RPC Handler
首先来挑简单的说。两个RPChandler是Hint中推荐先实现的两个函数。因此我也从这里开始说起。
两个handler有一些共性。
首先由于它们都需要密集地读取包括rf.currentTerm在内的多个共享状态,因此我把他们设计成在最开始获取rf.mu这把锁,并在执行的全过程中持有锁。
其次,它们都需要在reply中给出rf.currentTerm。(注意rf.currentTerm可能需要在处理的过程中被修改。reply中的值应该是处理完成后的最终值。)
最后,它们都需要根据args.Term和rf.currentTerm之间的大小关系做不同的处理。
综合这三点,两个RPC handler的结构大致如下:
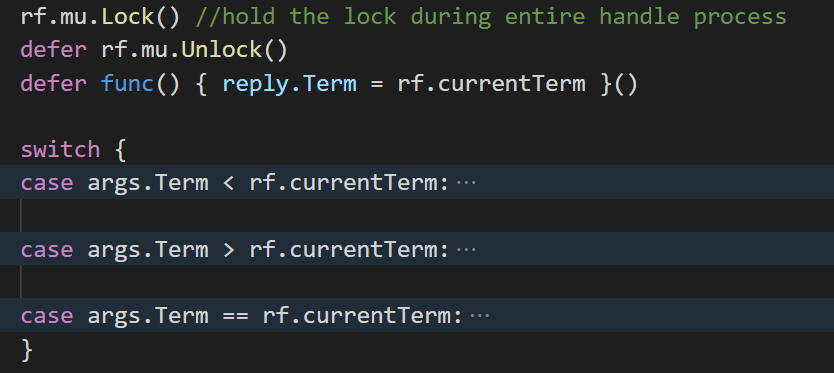
各种case中具体的处理流程这里就不展开了。详细的东西可以去看论文和我具体的代码实现。
值得讲的是它们如何发送message给正在执行leader()和elect()的goroutine。(也就是整体结构图中的蓝色message)
这里以 args.Term > rf.currentTerm 的情况为例。此时我们收到的RPC请求方具有更高的Term。我们应该立即接受这一Term,且转为follower。
转换为followe应该区分两种情况:rf.state==leader和rf.state==candidate。
对于这两种情况,需要将终止信号分别告知leader和elect两个goroutine。
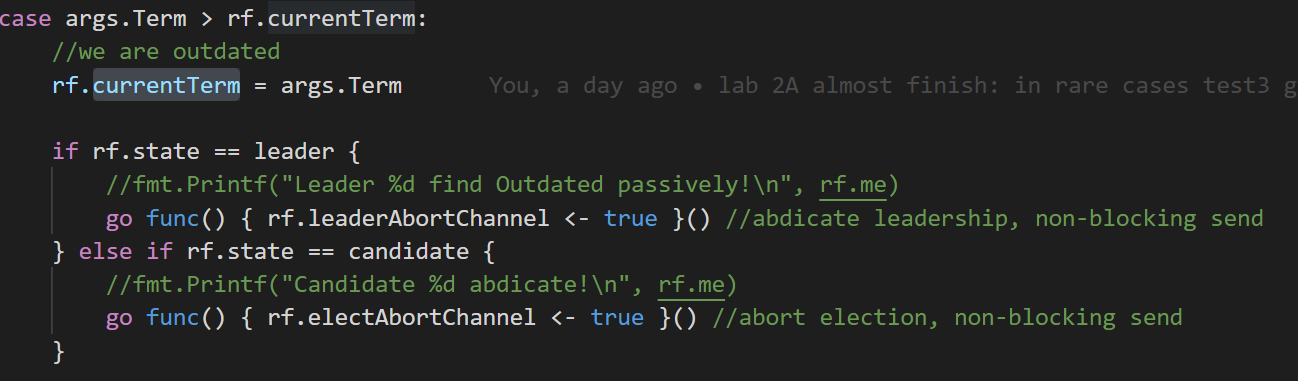
注意到这里采用了非阻塞的发送(用一个新建的goroutine去发送messge。)这样可以保证RPC handler及时退出,放弃rf.mu锁,让leader和elect能够获取到锁,继续执行。
在我最开始的实现中,没有使用非阻塞发送。这样将导致死锁😛
那么是否需要担心这里出现goroutine leak呢?如果leader或者elect不再监听对应的channel,那么这两个新建的goroutine可能阻塞在对应的channel上。
答案是不需要。因为我们可以在leader和elect函数的实现中确保:
如果rf.state==leader,则leader一定会监听leaderAbortChannel。如果leader因为其他原因退出(如leader收到了Term更大的reply),那么保证leader会尝试drain the channel,然后获取rf.mu,修改rf.state=follower。
如果rf.state==candidate,则完全类似。
这样,我们利用rf.mu将RPC handler与修改rf.state的过程串行化,确保了如果rf.state==leader/candidate,且RPC handler向channel中发送了终止信息:那么leader/elect一定会排空这个信息,让发送goroutine正常终止。
这里比较tricky,需要仔细思考一下!
Ticker
ticker是最特殊的函数。它将持续执行,永不终止。
在Hint中,助教提示我们不要用time.Timer或者timer.Ticker,因为它们容易导致问题。助教推荐使用time.Sleep。
但是在实际操作中我发现time.Sleep不能很好地实现reset功能。
(关于使用time.Sleep,我觉得可以这样实现:

即:把一次计时打碎为多次计时。
)
再者,time.Timer等的使用还是有必要学习一下的。(谁喜欢重复造轮子呢😂
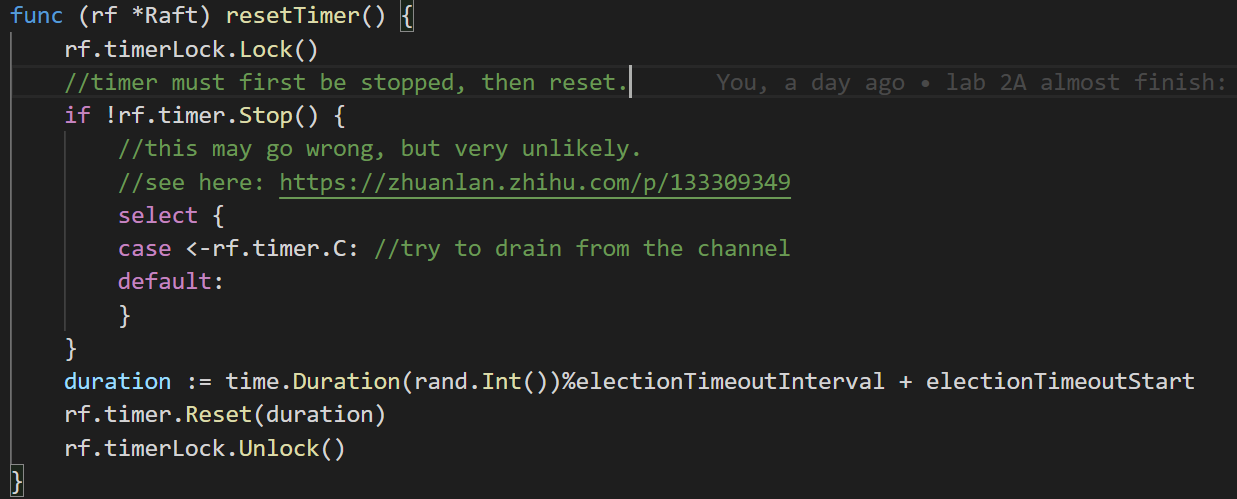
因此我使用了time.Timer实现计时器。增加了一把锁rf.timerLock用于重置timer(重置过程是互斥的)
每次Timer fire,都执行timer.Reset内置函数重置时间。
但是如果timer没有fire,reset timer的实现有必要加以注意。
此时必须要先stop timer,排空其channel,再reset timer。而且这一系列动作应该是互斥的(要加锁)。
这一套流程有固定的套路。但是这个套路仍然不能保证不发生race。这恐怕就是助教所说“容易发生错误”的原因。
详细的分析可以看https://zhuanlan.zhihu.com/p/133309349,这里不展开。
一个需要注意的点是:
如果timer fire,且当前rf.state==candidate,我们需要重新选举。
这表示我们需要放弃之前的那次选举,也就是让上一次的elect goroutine退出,且不再影响rf的任何状态(不再与RPC handler通信、不再修改rf.currentTerm等)。
可以用两个比较简单的机制来实现这两件事情:
1. 每次发现需要重新选举,都更换rf.electAbortChannel。(创建一个新的channel,赋值给它)
2. 更换之前,向之前的rf.electAbortChannel中发送一个false信号,告诉前一个elect终止,且退出时不要影响rf的状态(如修改rf.currentTerm)。
【注:正常的终止信号是true。这里发false,可以区分。】
Elect
elect函数仅由ticker调用(通过创建新的goroutine)
在elect中,我们通过创建多个send goroutine的方式并发地发送RequestVote请求。
这些send goroutine执行sendRequestVote函数,并将获得的reply发送到voteChannel。另一端,elect循环监听voteChannel。
elect函数的逻辑
elect函数的执行逻辑大致如下:
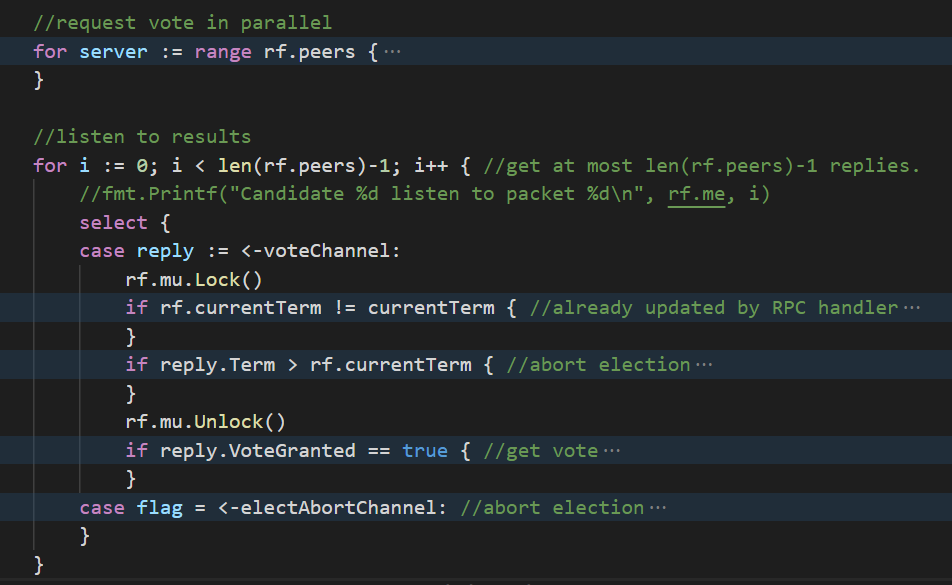
首先并发地发送requestVote请求
然后循环接受reply。
reply中的第一个if语句值得注意:
在elect函数刚刚执行时,我们记录了当时的rf.currentTerm。
在这里我们检查rf.currentTerm是否和当时记录的值相同。
如果不同,这代表RPC handler已经修改了rf.currentTerm。我们应该立即退出。
【当然,我觉得这里的实现总有些怪怪的。好像不加也可以。但是既然testcase都能过,就懒得改了😂】
最后,每次获取下一个reply时,如果有RPC handler发送了终止信号,则退出。
生产者goroutine的退出
elect函数中的实现是一个“典型的多生产者-单消费者”模式。
在讲elect函数的退出机制之前,我想先单独讨论下:对于“多生产者-单消费者”,多个生产者如何退出的问题。
我们知道,生产者向voteChannel发送reply是阻塞的。若消费者不再监听voteChannel,则会导致goroutine leak。
第一个自然的想法是把消费者的发送设置为非阻塞。即:
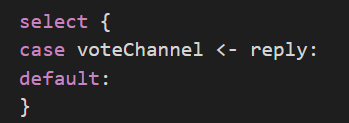
但是这种方式的问题是:可能消费者忙于处理上一个到来的reply(由其他生产者生产。)那么这个reply将drop。
第二个想法是消费者循环执行exactly len(rf.peers)-1次(所有的server数量减去我们自己),即读取voteChannel exactly len(rf.peers)-1次。
这种想法较难实现。这导致elect在收到退出信号时不能及时退出,增加了不必要的实现复杂性。因此我没有采取这种方式。
实际上这种模型有一个更好的终止办法:使用有buffer的channel。
(虽然professor明确说不建议使用buffered channel,但是我觉得应该灵活变通😛
开辟一个buffer大小为len(rf.peers)-1的terminateChannel。
当终止时,elect向这个buffer中发送len(rf.peers)-1个signal。
将生产者发送处的代码改为:
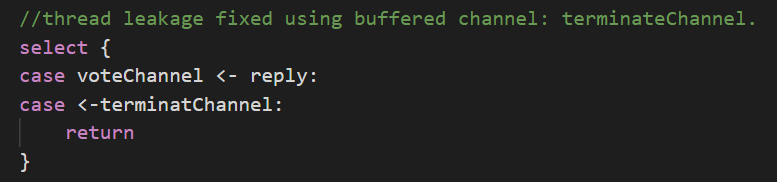
即:发送reply,或从terminateChannel读取。
这样可以很好的防止阻塞,从而避免goroutine leak。
elect函数的退出
elect函数的退出逻辑值得描述一下。虽然没有什么新的东西,但是上面提到的一些东西要在这里实现。
这里以reply.Term>rf.currentTerm的情况为例:
首先,需要按照【生产者goroutine的退出】一节中的描述,向terminateChannel中发送len(rf.peers)-1个终止信号。
其次,需要按照【RPC Handler】一节中的描述,drain electAbortChannel。
最后,需要按照【ticker】一节中的描述,检查drain electAbortChannel得到的值(如果有)是否为false。若为false,则不修改任何状态,直接退出。
下面展示了一个典型的elect退出情况
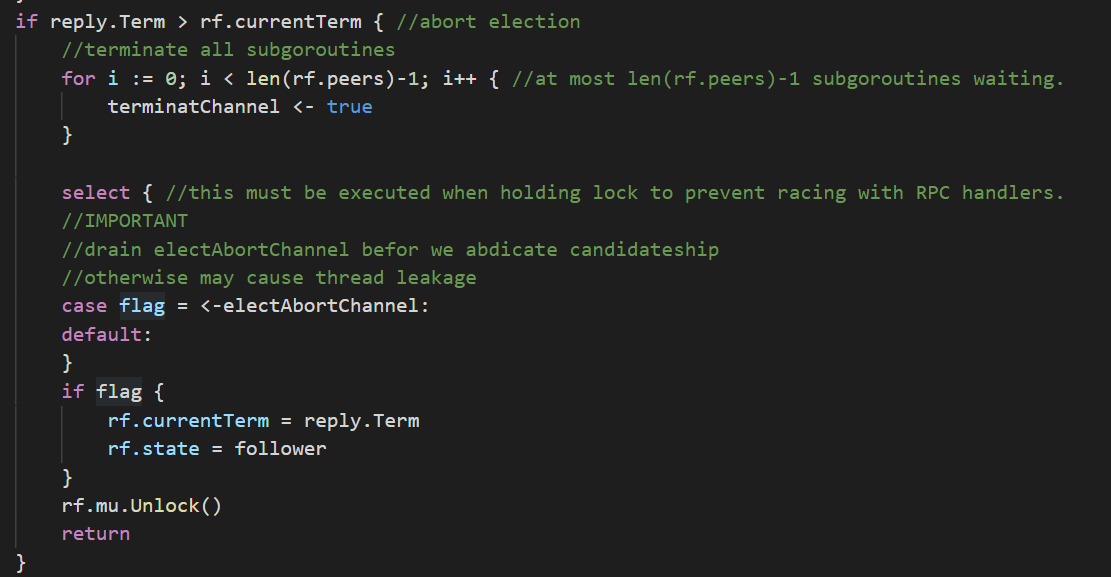
Leader
leader函数仅由elect调用(通过创建新的goroutine)
在leader中,我们同样通过创建多个send manager的方式并发地发送RequestVote请求。
这些send manager再周期性创建send goroutine,执行sendAppendEntries函数,并将获得的reply发送到heartbeatChannel。另一端,leader循环监听heartbeatChannel。
(与elect很相似。不过多了一级goroutine)
leader函数的逻辑
leader函数的执行逻辑大致如下:
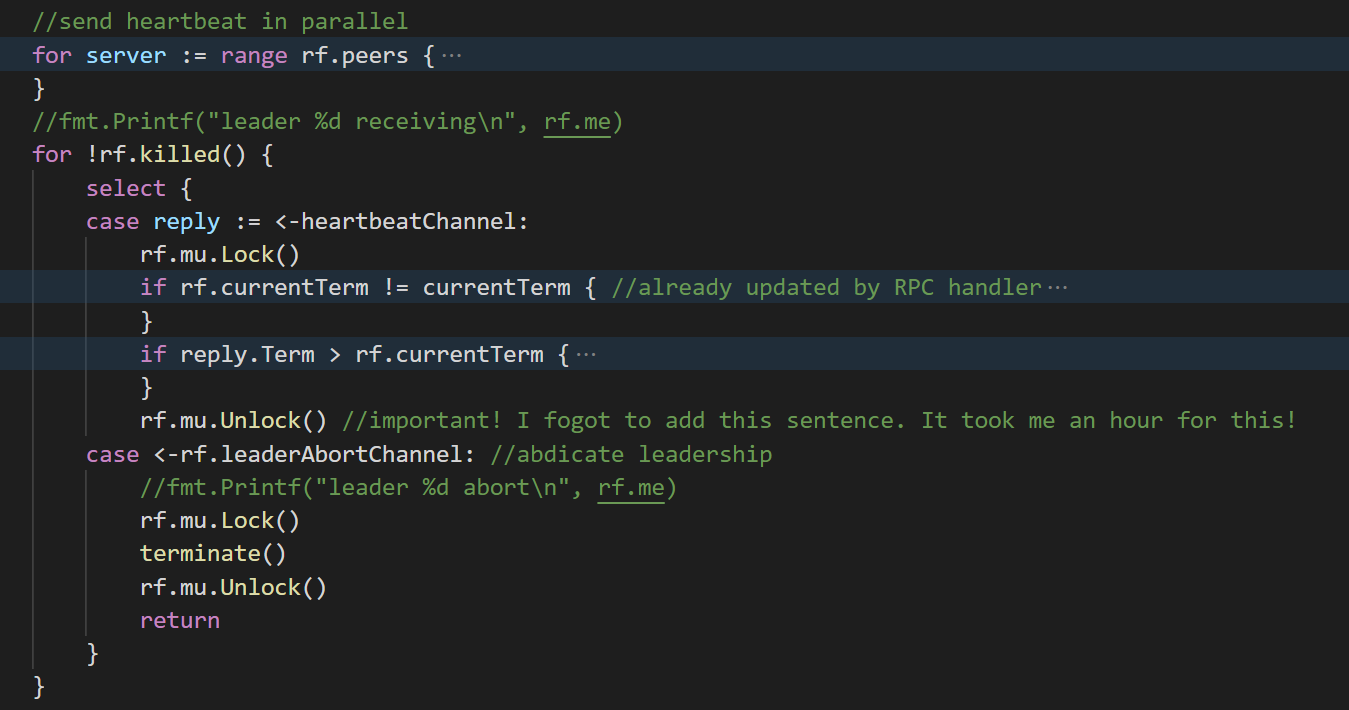
其实和elect在整体结构上并没有任何不同。。。
(但是细节上还是有需要注意的地方!😂
send manager
首先要说的就是send manager。
你可能会疑惑,为什么要引入这个东西?像elect一样不好吗?
先别急。
我们知道,leader是要周期性地向所有其他server发送心跳的。
如果我们不采用send manager:在send manager中,我们故技重施(仿照ticker):创建一个time.Timer。每当timer fire,创建一个send goroutine发送heartbeat。
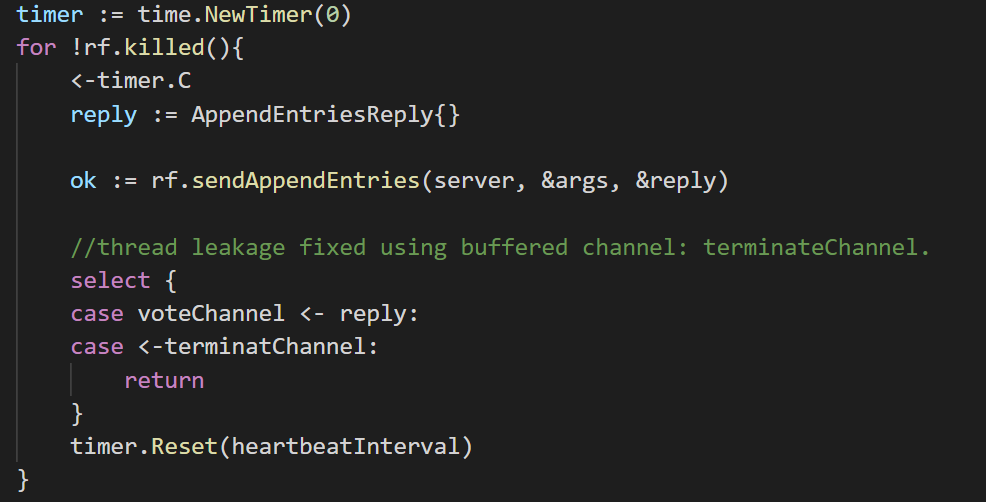
看起来似乎很美好。
但注意,这种实现会出问题!
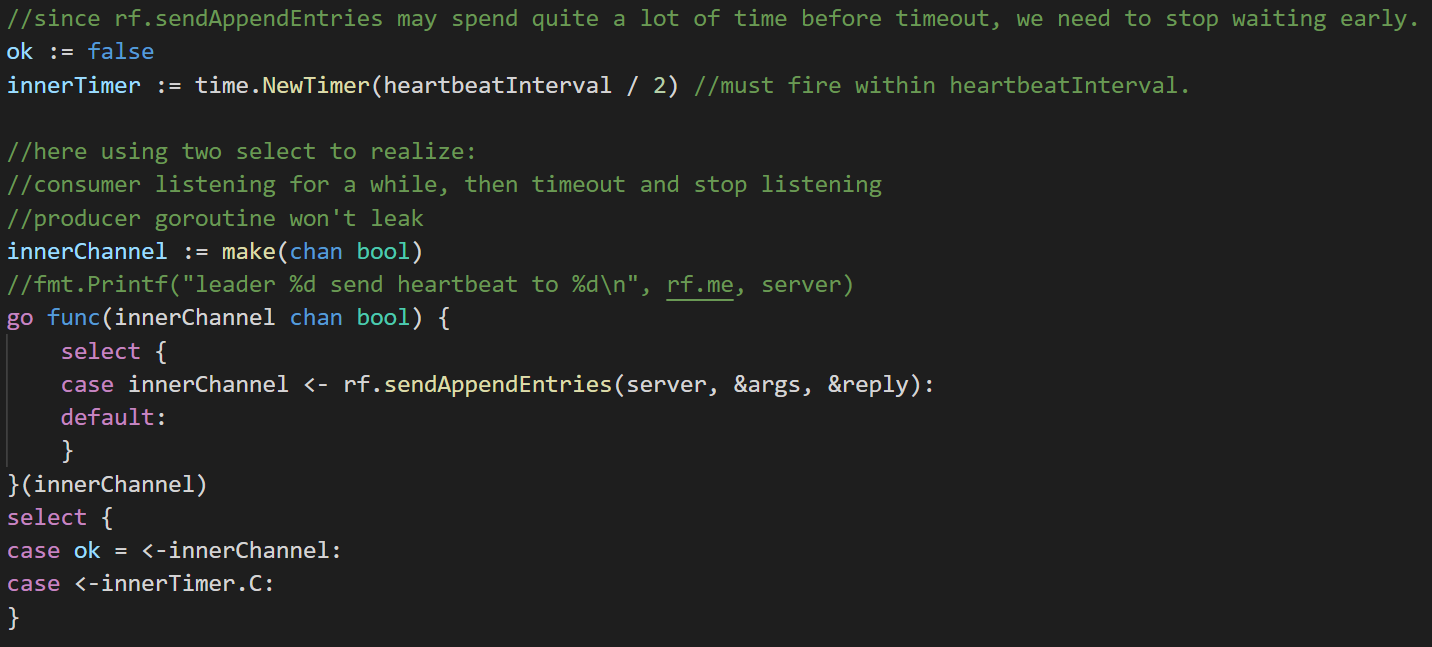
通过这种方式,我们实现了heartbeat的周期性发送。
leader函数的退出
leader函数的退出流程与elect相似。
但是leader相比于elect,有两个简化点:
1. leader不会发生elect中的"re-elect"现象(leaderAbortChannel中的信号只能为true,无需检查)
2. leader如果发生状态改变,一定是变为follower
因此我们可以将终止时的逻辑抽象成函数:
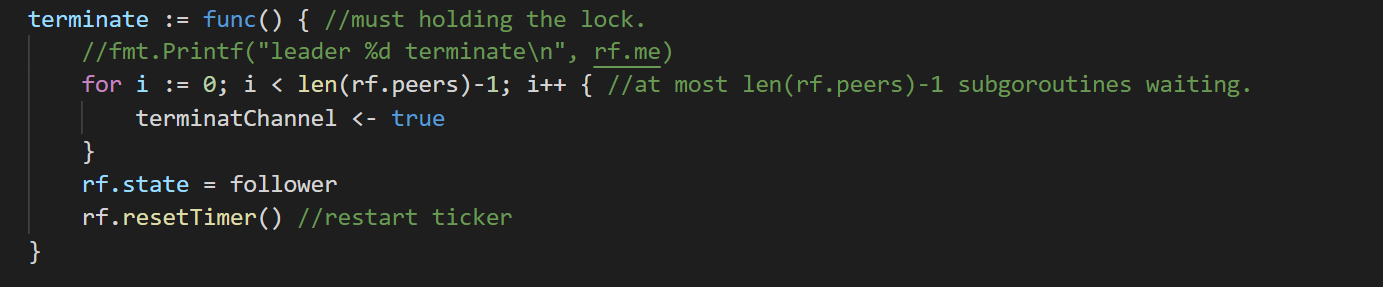
(注意:drain leaderAbortChannel的过程并不包含在这里。至于原因,可以看代码。一句话说不清楚。)
(注意:leader转变回follower,要resetTimer)
总结
至此,代码实现中的关键点总结完毕。
如果对raft选举的流程有疑问,可以仔细研究下论文。
本篇博客的重点不是选举逻辑,而是避免race,避免thread leak,避免deadlock,以及一些设计哲学。
我感觉有很多地方写的都不好,如果你在看,还请多多包涵!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号