PyTorch 入门基础实践
以下内容主要介绍 tensor 数据类型、torch 反向传播自动求导、使用 torch 实现线性回归、逻辑斯蒂回归、数据集的加载与构造、多分类 (手写数字)。
1 tensor 张量
torch.tensor 是包含单个数据类型元素的多维矩阵,与 numpy 数组十分相似。tensor 有两种属性:类型和形状
tensor 的数据类型:Torch 定义了 9 种 CPU 张量类型和 9 种 GPU 张量类型,torch.tensor 默认 torch.FloatTensor 类型。
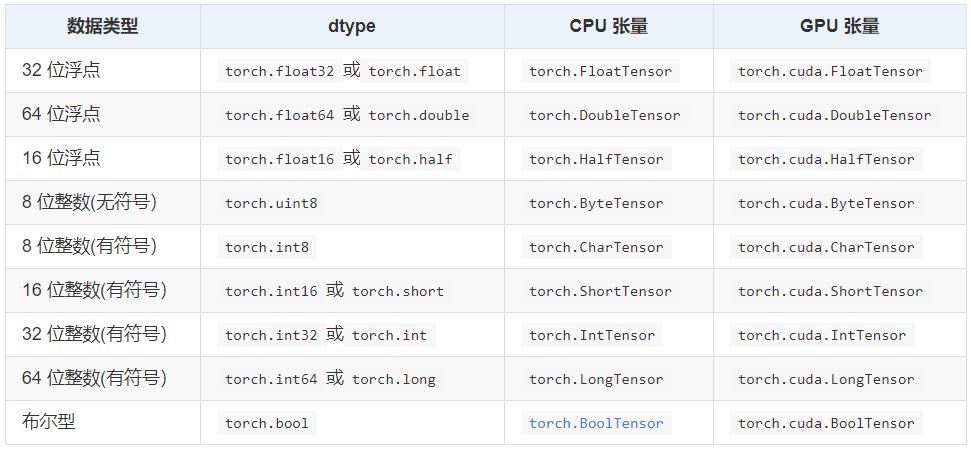
tensor 的常见形式:tensor 就是一个多维数据,例如,
0 维张量,标量:
# Scalar x = tensor(42.) print(x) print(x.item()) print(x.dim()) print(2*x)
输出:
tensor(42.) 42.0 0 tensor(84.)
1 维张量,矢量:
# Vector v = tensor([1.5, -1.5, 3.0]) print(v) print(v.dim()) print(v.size())
输出:
tensor([ 1.5000, -1.5000, 3.0000]) 1 torch.Size([3])
2 维张量,矩阵:
# Matrix M = tensor([[1., 2.], [3., 4.]]) print(M) print(M.matmul(M)) # 矩阵乘法 print(M*M) # 矩阵内积 print(tensor([1., 2.]).matmul(M))
输出:
tensor([[1., 2.], [3., 4.]]) tensor([[ 7., 10.], [15., 22.]]) tensor([[ 1., 4.], [ 9., 16.]]) tensor([ 7., 10.])
tensor 的一些基本操作:
import torch # 版本 print(torch.__version__) # 创建矩阵 x = torch.empty(5, 3) print(x) x = torch.rand(5, 3) print(x) x = torch.zeros(5, 3, dtype=torch.long) print(x) x = torch.tensor([5.5, 3]) print(x) x = x.new_ones(5, 3, dtype=torch.double) print(x) x = torch.randn_like(x, dtype=torch.float) # 构建一个相同大小的随机矩阵 print(x) # 展示矩阵大小 print(x.size()) # 基本计算方法 y = torch.rand(5, 3) print(x + y) print(torch.add(x, y)) # 索引 print(x[:, 1]) print(x[1, :]) # view 改变矩阵维度 x = torch.randn(4, 4) y = x.view(16) z = x.view(-1, 8) print(x.size(), y.size(), z.size()) print(x) print(y) print(z) # 与 numpy 的相互转换 import numpy as np a = torch.ones(5) b = a.numpy() print(b) a = np.ones(5) b = torch.from_numpy(a) print(b)
2 torch 自动求导
这里拟合一个简单的线性方程 y'=w*x ,损失函数为 (y'-y)2,
import torch x_data = [1.0, 2.0, 3.0] y_data = [2.0, 4.0, 6.0] w = torch.Tensor([1.0]) w.requires_grad = True def forward(x): return x * w def loss(x, y): y_pred = forward(x) return (y_pred - y) ** 2 print("predict (before training)", 4, forward(4).item()) for epoch in range(100): for x, y in zip(x_data, y_data): l = loss(x, y) # 构建计算图中直接使用张量 l.backward() print('\tgrad:', x, y, w.grad.item()) w.data = w.data - 0.01 * w.grad.data # 取data计算不会生成张量图,权重更新时单纯的求数据不需要求梯度 # eg:sum+=l 会不断构建张量图,循环次数过多会消耗内存,所以应该用 sum+=l.item() w.grad.data.zero_() # 梯度会保留下来,如果不清零会不断累加,有些模型会需要这种累加功能,这里不需要就要清零 print("progress:", epoch, l.item()) print("predict (before training)", 4, forward(4).item())
对于需要计算梯度的参数 w,要将 w.requires_grad 置为 True;
在计算前向传播和损失函数中,构造了一个计算图,通过直接调用 backward() ,w 的梯度值会被自动累加到 w.grad 中;
注意,w.grad 会被保存下来,每次反向传播计算的梯度是累加进去的,所以往往需要手动清零;
当 w 设置了 requires_grad 时,如果我们只是需要使用张量的值,而不是构造计算图计算梯度,应该使用 w.data,而不是 w ;
3 线性回归
同样使用上面的数据,但这里的模型使用类来构造,优化器和损失函数直接调用 torch 已有的包,
import torch x_data = torch.Tensor([[1.0], [2.0], [3.0]]) y_data = torch.Tensor([[2.0], [4.0], [6.0]]) class LinearModel(torch.nn.Module): def __init__(self, input_dim, output_dim): super(LinearModel, self).__init__() # 调用父类的构造函数 self.linear = torch.nn.Linear(input_dim, output_dim) def forward(self, x): out = self.linear(x) return out model = LinearModel(1, 1) criterion = torch.nn.MSELoss(size_average=False) optimizer = torch.optim.SGD(model.parameters(), lr=0.01) # 确定需要优化的参数,学习率等 for epoch in range(10): y_pred = model(x_data) loss = criterion(y_pred, y_data) print(epoch, loss) optimizer.zero_grad() loss.backward() optimizer.step() print('w=', model.linear.weight.item()) print('b=', model.linear.bias.item()) x_test = torch.Tensor([[4.0]]) y_test = model(x_test) print('y_pred=', y_test.data)
torch.nn.Linear 是一个线性模型,其中有参数 w 和 b ;
torch.nn.MSELoss 是均方损失函数,size_average 表示是否需要取均值 (即 /n);
torch.optim.SGD 是 SGD 优化器,model.parameters() 可以确定模型中所有需要优化的参数;
从上面可以看出,从模型的设计到训练一般分为四步:1.准备数据集;2.设计模型(class);3.构造损失函数和优化器;4.训练模型。
其中训练模型一般包括:1.前向传播;2.计算损害函数;3.梯度清零(要在反向传播之前);4.反向传播;5.参数更新。
4 逻辑斯蒂回归
这是一个单特征二分类问题, y 取值为 0 或 1,
import torch import torch.nn.functional as F x_data = torch.tensor([[1.0], [2.0], [3.0]]) y_data = torch.tensor([[0.], [0.], [1.]])
class LogisticRegressionModel(torch.nn.Module): def __init__(self): super(LogisticRegressionModel, self).__init__() self.linear = torch.nn.Linear(1, 1) def forward(self, x): y_pred = F.sigmoid(self.linear(x)) return y_pred model = LogisticRegressionModel() criterion = torch.nn.BCELoss(size_average=False) # 交叉熵 optimizer = torch.optim.SGD(model.parameters(), lr=0.01) for epoch in range(1000): y_pred = model(x_data) loss = criterion(y_pred, y_data) print(epoch, loss.item()) optimizer.zero_grad() loss.backward() optimizer.step()
注意,如果 y_data 中的数据没有小数点,被认为是 long 类型,使用交叉熵损失函数会被报错;
torch.sigmoid() 、torch.nn.function.sigmoid() 是函数,在 forward 中使用,torch.nn.sigmoid 是一个类,可以当做神经网络中的一层 (没有参数),在 init 中使用。
多特征二分类,下面的例子中数据 x 中的每个样本有 8 个特征,
import torch import numpy as np xy = np.loadtxt('../dataset/diabetes.csv.gz', delimiter=',', dtype=np.float32) x_data = torch.from_numpy(xy[:, :-1]) y_data = torch.from_numpy(xy[:, [-1]]) class Model(torch.nn.Module): def __init__(self): super(Model, self).__init__() self.linear1 = torch.nn.Linear(8, 6) self.linear2 = torch.nn.Linear(6, 4) self.linear3 = torch.nn.Linear(4, 1) self.sigmoid = torch.nn.Sigmoid() def forward(self, x): x = self.sigmoid(self.linear1(x)) x = self.sigmoid(self.linear2(x)) x = self.sigmoid(self.linear3(x)) return x model = Model() criterion = torch.nn.BCELoss(size_average=True) optimizer = torch.optim.SGD(model.parameters(), lr=0.1) for epoch in range(100): y_pred = model(x_data) loss = criterion(y_pred, y_data) print(epoch, loss.data) optimizer.zero_grad() loss.backward() optimizer.step()
diabetes.csv.gz 数据集可在本文末尾的参考链接中下载。
5 数据集
Dataset 和 DataLoader 的使用,
from torch.utils.data import Dataset from torch.utils.data import DataLoader # 数据集不大,可以在init中全部加载进去,数据集过大,init就只做一个初始化 class DiabetesDataset(Dataset): def __init__(self): pass def __getitem__(self, item): # 通过索引item把数据拿出来 pass def __len__(self): # 返回数据条数 pass dataset = DiabetesDataset() train_loader = DataLoader(dataset=dataset, batch_size=32, shuffle=True, num_workers=2) # 需要几个并行进程读取数据
num_workers 可能遇到的问题:直接使用 train_loader 会报错,windows 和 Linux 中多进程的实现是不一样的,即 spawn 和 fork。
解决方法:将 loader 迭代的代码封装起来,例如封装到 if 语句或函数里,if __name__ == '__main__':
if __name__ == '__main__': for epoch in range(100): for i, data in enumerate(train_loader, 0):
DataLoader 使用实例:
import torch import numpy as np from torch.utils.data import Dataset from torch.utils.data import DataLoader class DiabetesDataset(Dataset): def __init__(self, filepath): xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32) print(xy.shape) self.len = xy.shape[0] self.x_data = torch.from_numpy(xy[:, :-1]) self.y_data = torch.from_numpy(xy[:, [-1]]) def __getitem__(self, item): return self.x_data[item], self.y_data[item] def __len__(self): return self.len dataset = DiabetesDataset('../dataset/diabetes.csv.gz') train_loader = DataLoader(dataset=dataset, batch_size=32, shuffle=True, num_workers=2) class Model(torch.nn.Module): def __init__(self): super(Model, self).__init__() self.linear1 = torch.nn.Linear(8, 6) self.linear2 = torch.nn.Linear(6, 4) self.linear3 = torch.nn.Linear(4, 1) self.sigmoid = torch.nn.Sigmoid() def forward(self, x): x = self.sigmoid(self.linear1(x)) x = self.sigmoid(self.linear2(x)) x = self.sigmoid(self.linear3(x)) return x model = Model() criterion = torch.nn.BCELoss(size_average=True) optimizer = torch.optim.SGD(model.parameters(), lr=0.1) if __name__ == '__main__': for epoch in range(10): for i, data in enumerate(train_loader, 0): # Prepare dataset inputs, labels = data # Forward y_pred = model(inputs) loss = criterion(y_pred, labels) print(epoch, i, loss.item()) # Backward optimizer.zero_grad() loss.backward() # Updata optimizer.step()
torchvision.datasets 中的数据集

如何使用:
import torchvision from torchvision import transforms from torch.utils.data import DataLoader train_dataset = torchvision.datasets.MNIST(root='../dataset/mnist', train=True, transform=transforms.ToTensor(), download=True) test_dataset = torchvision.datasets.MNIST(root='../dataset/mnist', train=False, transform=transforms.ToTensor(), download=True) train_loader = DataLoader(dataset=train_dataset, batch_size=32, shuffle=True) test_loader = DataLoader(dataset=test_dataset, batch_size=32, shuffle=False)
download=True 时,如果没有下载数据集,会自动下载。
6 多分类问题
第 4 节讨论了多特征二分类问题,本节讨论多分类问题,使用了 softmax 层、交叉熵损失函数。
交叉熵损失函数:
import torch y = torch.LongTensor([0]) z = torch.Tensor([[0.2, 0.1, -0.1]]) criterion = torch.nn.CrossEntropyLoss() loss = criterion(z, y) print(loss)
交叉熵损失函数中的参数,标签 y 是一个长整型,上面的例子表示第 0 类,预测 z 是一个长度为 n 的向量 (一共 n 类),这一层 (即神经网络的最后一层) 不需要激活函数,直接代入到 softmax 中 (也不需要自己写,交叉熵损失函数会自己计算),通过这两个参数求出损失。
import torch criterion = torch.nn.CrossEntropyLoss() Y = torch.LongTensor([2, 0, 1]) Y_pred1 = torch.Tensor([[0.1, 0.2, 0.9], [1.1, 0.1, 0.2], [0.2, 2.1, 0.1]]) Y_pred2 = torch.Tensor([[0.8, 0.2, 0.3], [0.2, 0.3, 0.5], [0.2, 0.2, 0.5]]) l1 = criterion(Y_pred1, Y) l2 = criterion(Y_pred2, Y) print("Batch Loss1 = ", l1.data, "\nBatch Loss2 = ", l2.data)
这个例子中计算了三个样本两种预测的交叉熵损失。
手写数字识别:
import torch from torchvision import transforms from torchvision import datasets from torch.utils.data import DataLoader import torch.nn.functional as F import torch.optim as optim batch_size = 64 transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,)) # 两个参数分别表示 均值mean、标准差std ]) train_dataset = datasets.MNIST(root='../dataset/mnist', train=True, transform=transform, download=True) test_dataset = datasets.MNIST(root='../dataset/mnist', train=False, transform=transform, download=True) train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True) test_loader = DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False) class Net(torch.nn.Module): def __init__(self): super(Net, self).__init__() self.l1 = torch.nn.Linear(784, 512) self.l2 = torch.nn.Linear(512, 256) self.l3 = torch.nn.Linear(256, 128) self.l4 = torch.nn.Linear(128, 64) self.l5 = torch.nn.Linear(64, 10) def forward(self, x): x = x.view(-1, 784) x = F.relu(self.l1(x)) x = F.relu(self.l2(x)) x = F.relu(self.l3(x)) x = F.relu(self.l4(x)) return self.l5(x) # 最后一层接softmax层,不做激活 model = Net() criterion = torch.nn.CrossEntropyLoss() optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5) def train(epoch): running_loss = 0.0 for batch_idx, data in enumerate(train_loader, 0): inputs, target = data optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, target) loss.backward() optimizer.step() running_loss += loss.item() if batch_idx % 300 == 299: print('[%d, %5d] loss: %.3f' % (epoch+1, batch_idx+1, running_loss/300)) running_loss = 0.0 def test(): correct = 0 total = 0 with torch.no_grad(): # 测试不需要计算梯度 for data in test_loader: images, labels = data outputs = model(images) _, predicted = torch.max(outputs.data, dim=1) total += labels.size(0) correct += (predicted == labels).sum().item() print('Accuracy on test set: %d %%' % (100 * correct / total)) if __name__ == '__main__': for epoch in range(100): train(epoch) test()
transform 参数将 PIL image 转换为了 Tensor,且将像素值标准化为均值 0.1307、方差 0.3081 的数据,同时,将 28*28 的数据转换为 1*28*28 的数据 (1 表示单通道)。
PIL image:大小 28*28,像素值 0~255;
PyTorch Tensor:大小 1*28*28,像素值 0~1 。
主要参考:《PyTorch深度学习实践》 (B站 BV1Y7411d7Ys)
课件下载:链接: https://pan.baidu.com/s/1Ku5c99yDHNFMt8EJAcF5LA 提取码: n4xh

 浙公网安备 33010602011771号
浙公网安备 33010602011771号