卷积神经网络 (Convolution Neural Networks, CNN)
卷积神经网络一般用在图像处理、计算机视觉等领域。下面1-4节介绍了构造卷积神经网络基础知识,第5节介绍一些经典的卷积神经网络,7-9节介绍了三种CNN常见应用:目标检测、人脸识别、风格迁移。
1. 卷积计算
1.1 卷积运算 (Convolution):
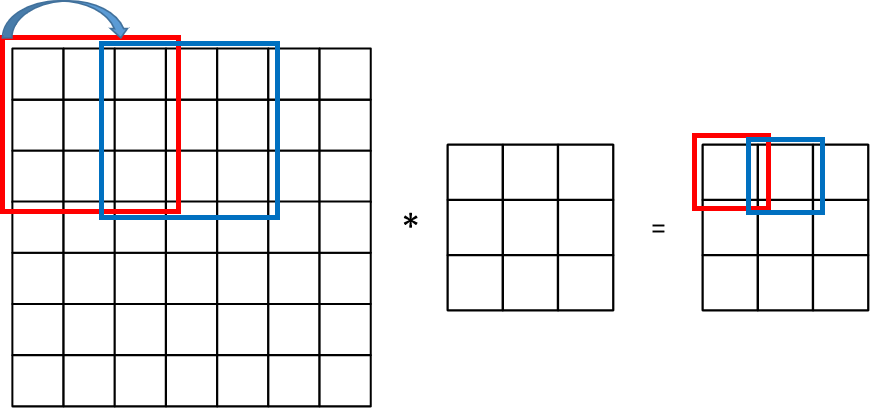
如图,一个6×6的矩阵A与一个3×3的filter矩阵进行卷积计算,生成了一个4×4的矩阵B,B[1][1]就是矩阵A红色边框中的数字与filter矩阵依次相乘再相加计算出来的,滑动边框依次计算就可以得到B。
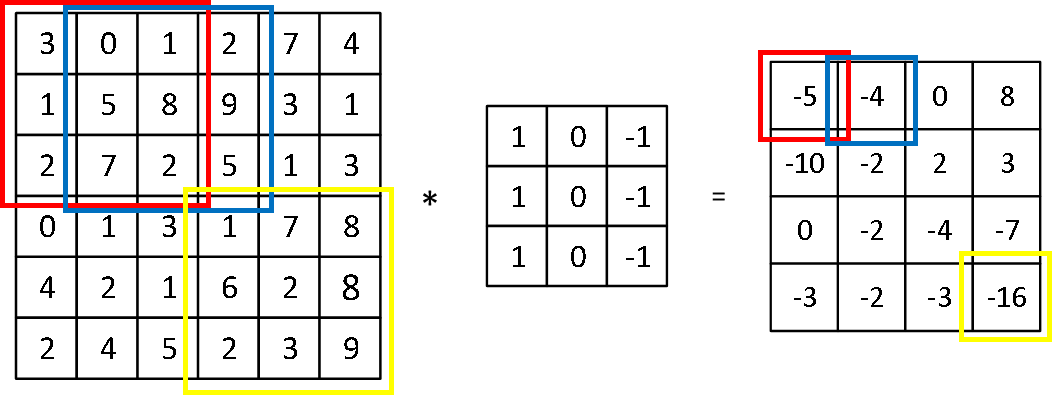
滤波器大小一般是奇数,例如3×3、5×5等,这样就会有一个中心点,便于计算。
注意:在一些数学书籍上,卷积需要对滤波器进行镜像操作,没有镜像操作的运算称为“互相关”。但在深度学习文献中,卷积一般没有镜像操作。
1.2 边缘检测 (Vertical edge detection):
下面展示了一个垂直滤波器(vertical filters)的效果 ,可以检测出垂直的边缘,还可以反映由明到暗或由暗到明的变化。
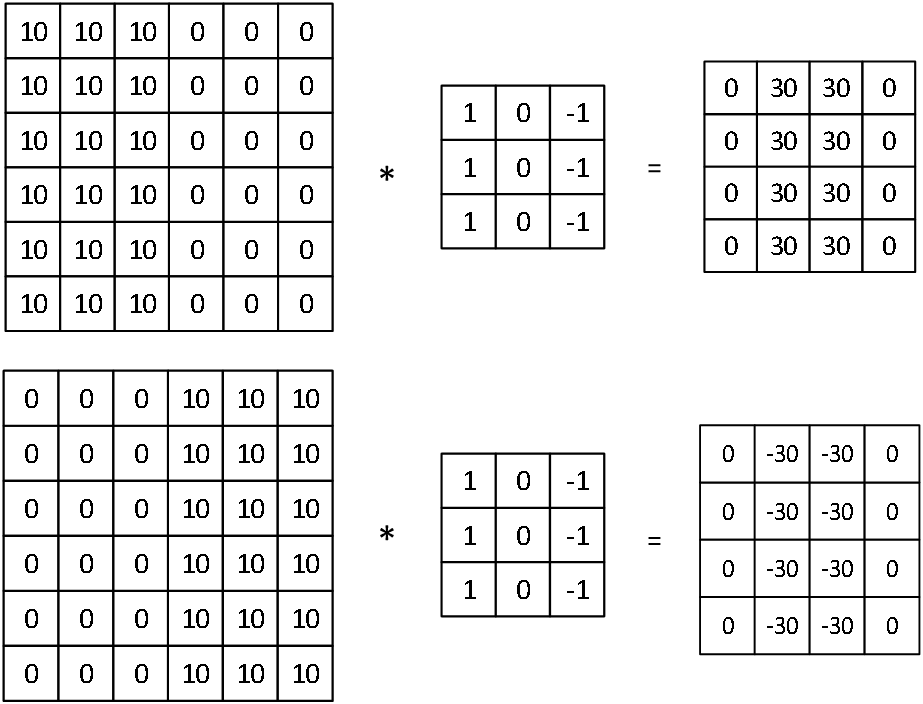
滤波器的大小、参数可以根据需要设计,例如还可以实现不同角度的边缘检测。在神经网络中,参数可以通过训练得出。

1.3 填充 (Padding):
在卷积计算中,矩阵大小变化为:( n × n ) * ( f × f ) = ( n-f+1 × n-f+1 )。这样的计算存在两个问题:(1) 输出缩小,随着网络的加深,图片经过多次卷积处理会越来越小;(2) 图像边缘的大部分信息丢失,例如左上角的元素只使用过一次。所以我们需要填充一层像素,使( n × n ) * ( f × f ) = ( n × n ),一般会填充0,如图所示:
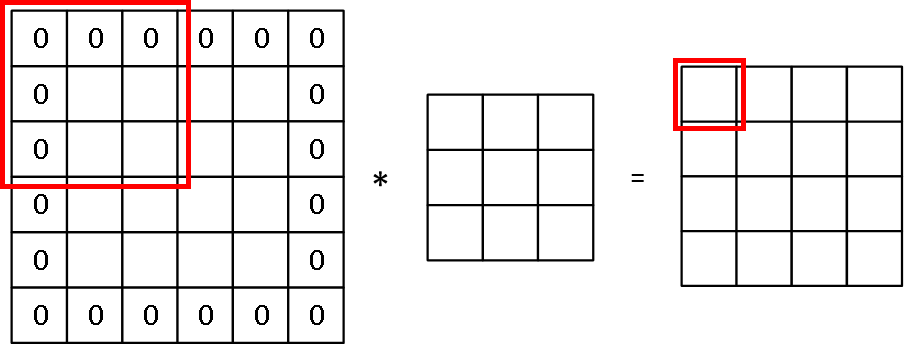
其中 n=4、f=3、p(padding amount)=1。
因此,后面说的卷积有两种模式:
- Valid convolution:不填充数据
- Same convolution:填充数据,输入输出大小相同,p=(f-1)/2
没有特殊说明一般指Valid convolution。
此外,还有一个参数是卷积的歩长s (strided convolution),一般默认s=1,下面给出了一个s=2的例子:
所以,卷积后的大小为: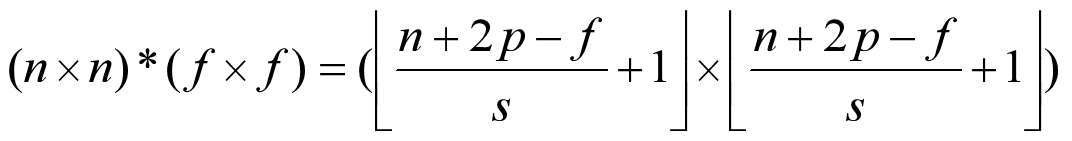
1.4 三维卷积:
下面给出了一个三通道图像卷积的示例:
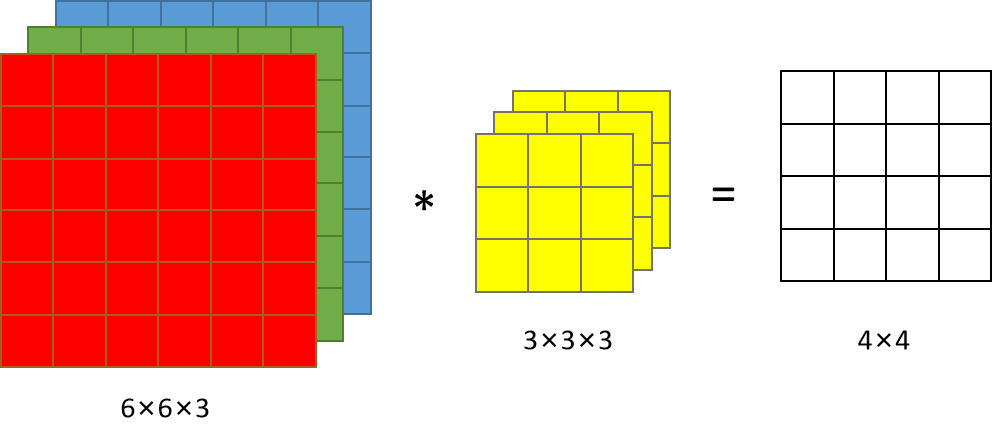
图像的大小为 6×6×3,分别为宽w、高h、通道数c。滤波器也是三维的,其中滤波器的通道数必须与图像相同,所以后面可能不会注明滤波器的通道数。最终的结果是只有一个通道的4×4图像。
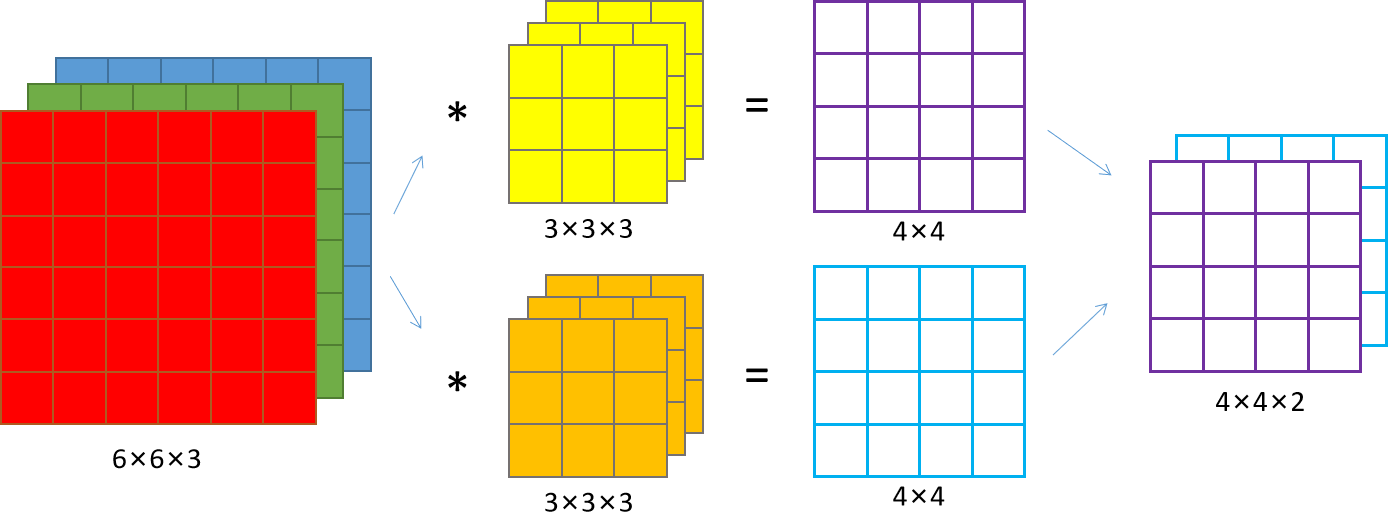
如果我们有多个滤波器 (Multiple filters),可以做以下运算:

当有两个滤波器的时候,可以得到一个二通道图像。
2. 卷积层 (Convolution layer)
其实,使用多个滤波器对图像进行处理就构成了一个卷积层,同该例:
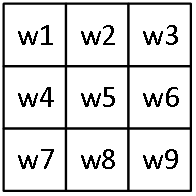
下面对卷积层进行符号说明:如果第ζ层是一个卷积层:

Example ConvNet:
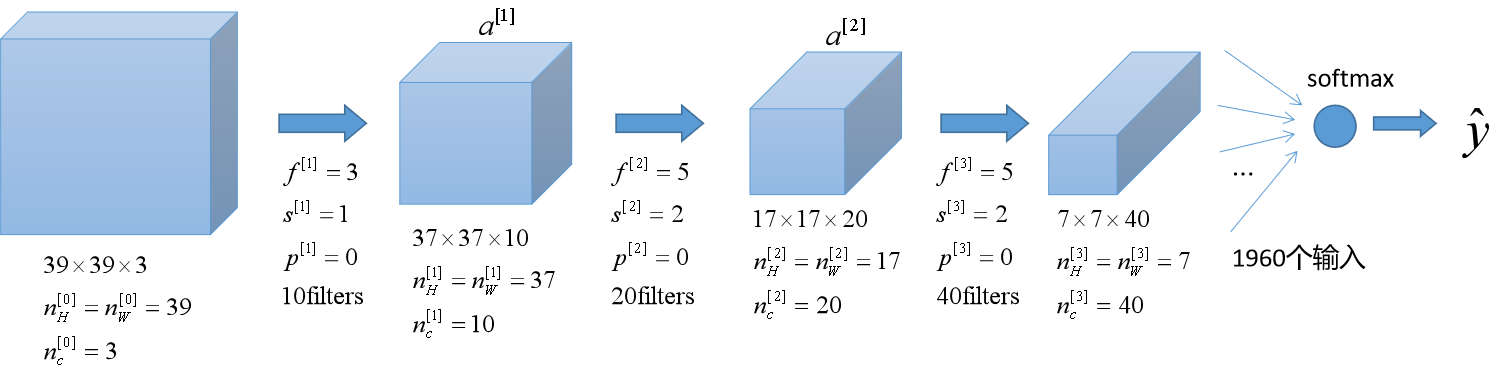
其中前三层都为卷积层,最后一层使用了全连接和softmax激活函数。
3. 池化层 (Pooling layer)
池化其实是一种降采样,有多种不同形式的非线性池化函数。最常见的有“最大池化(Max pooling)”:
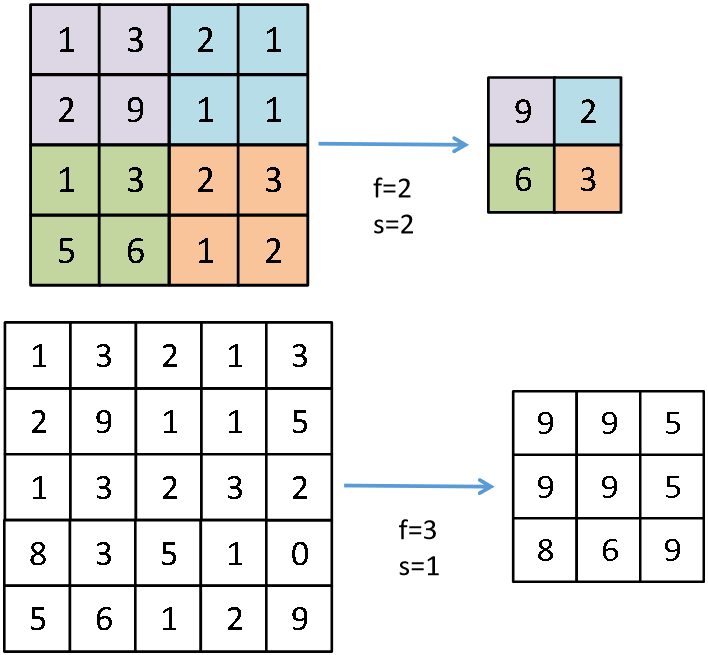
池化层没有需要训练的权重和阈值等参数,只有需要提前设定的超参数:f (filter size)、s (stride)、max or average pooling。
4. 卷积神经网络
Neural network example:卷积层(CONV)、池化层(POOL)、全连接层(FC)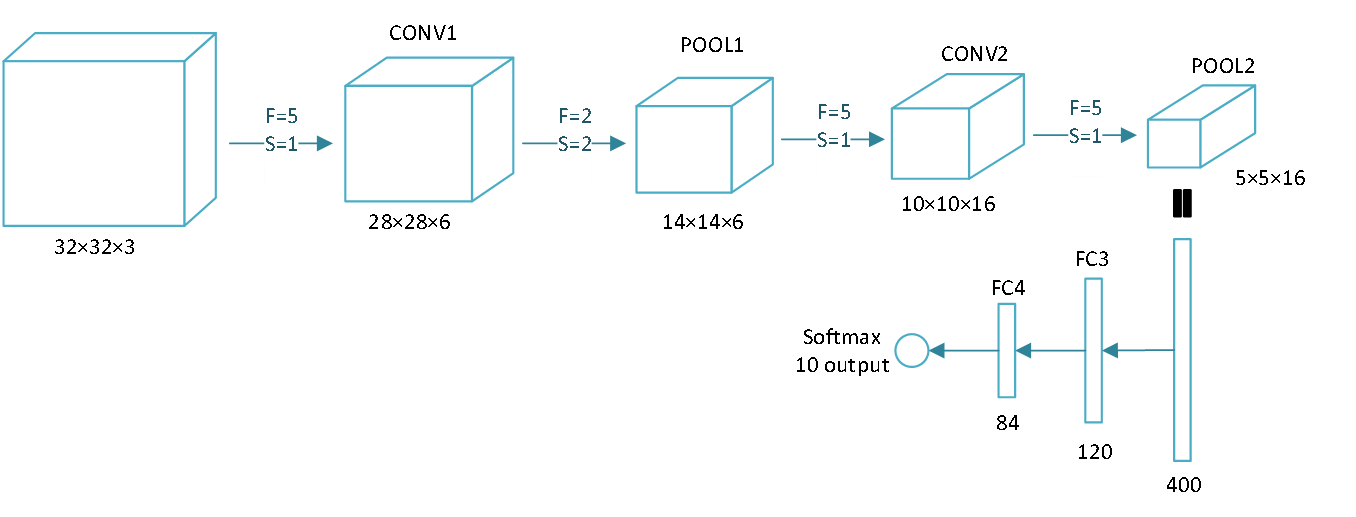
这是一种卷积神经网络的经典模式:conv - pool - conv - pool - fc - fc -fc - softmax。因为池化层没有参数,所以有时卷积层和池化层算作神经网络的一层。其中的超参数尽量不要自己随意设置,而应该参考别人文献中的设置。
可以发现一个规律,随着神经网络的加深,激活值的size逐渐变小。
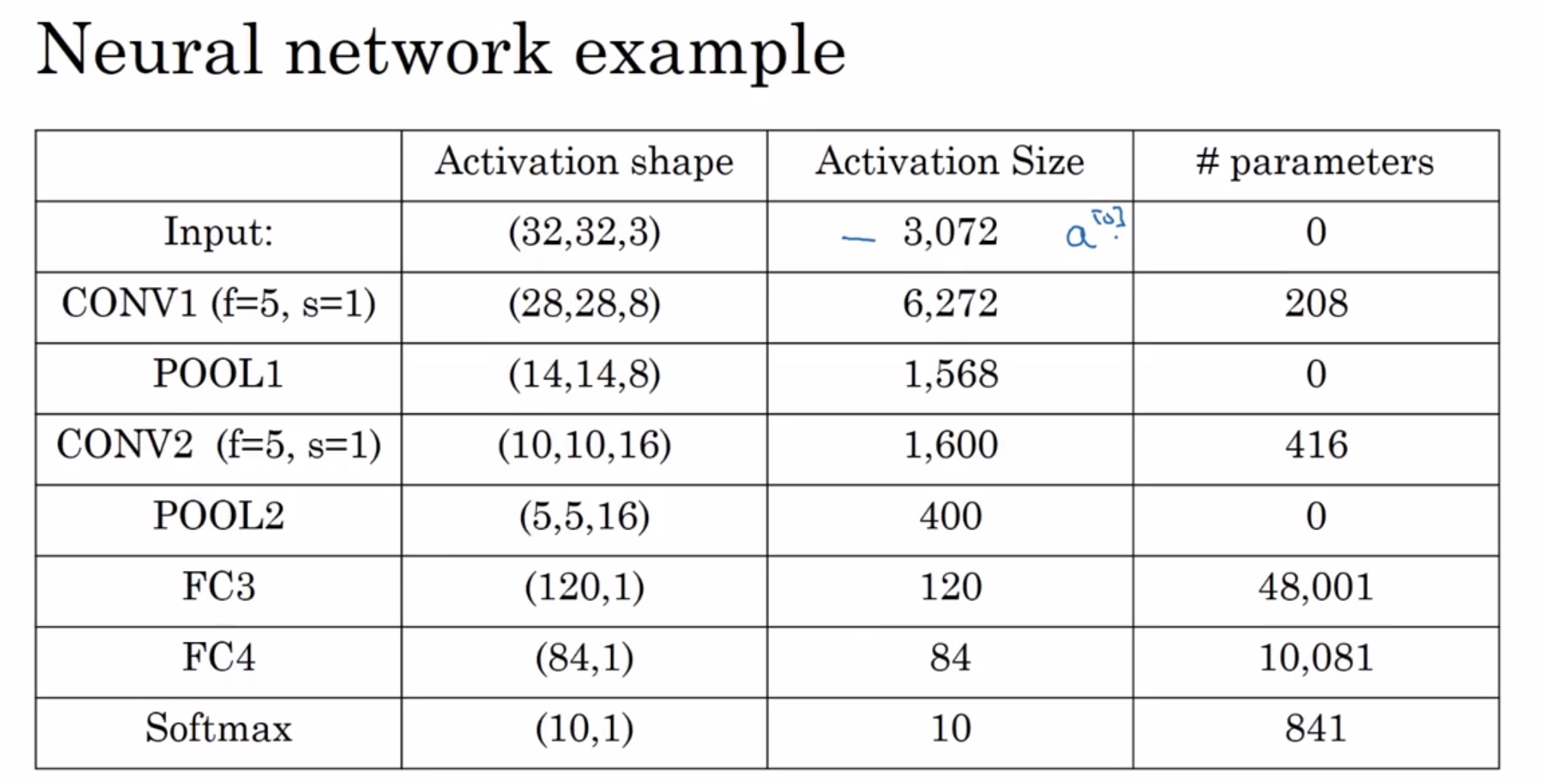
为什么要使用卷积?相比于全连接层有什么优势?
- 参数共享,适用于图像一部分的特征检测器(例如边缘检测)也同样适用于图像的其他部分,可以看出卷积层参数远远小于全连接层;
- 稀疏连接,卷积层输出的每个数值仅依赖于输入的很小一部分,不受其他部分的影响。
5. 经典的卷积神经网络
5.1 LeNet-5
结构:conv - pool - conv - pool - fc - fc - softmax
该网络提出的时间较早,使用的激活函数还是 sigmoid / tanh

![]()
5.2 AlexNet
该网络比 LeNet 更大,但更简单。使用的激活函数是 ReLU

![]()
5.3 VGG-16
这种网络很大,但结构规整且不复杂。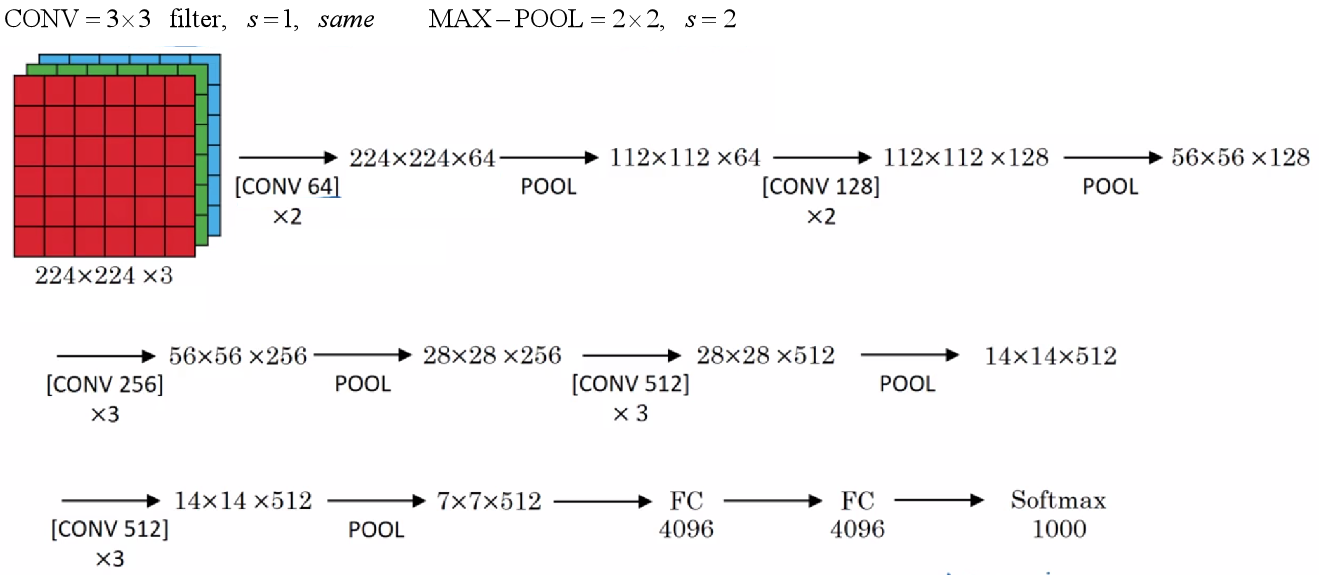
![]()
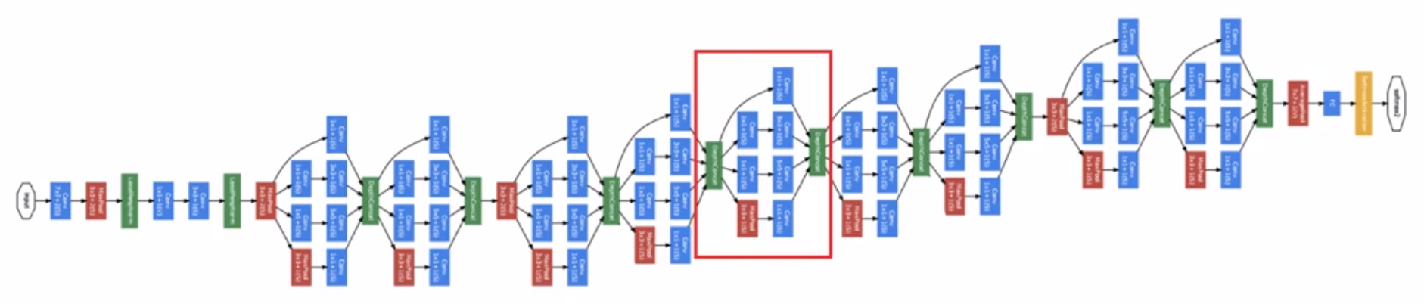
5.4 ResNet (残差网络)
Residual block (残差块):

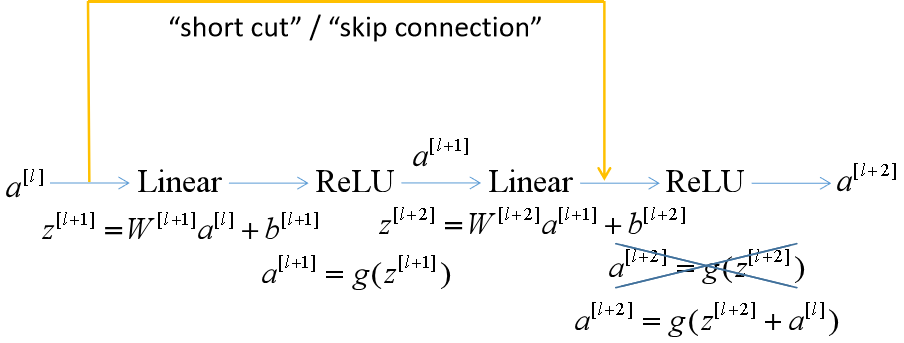
添加这样一个“捷径”,就可以构成一个残差块,将信息传递到网络的更深层。
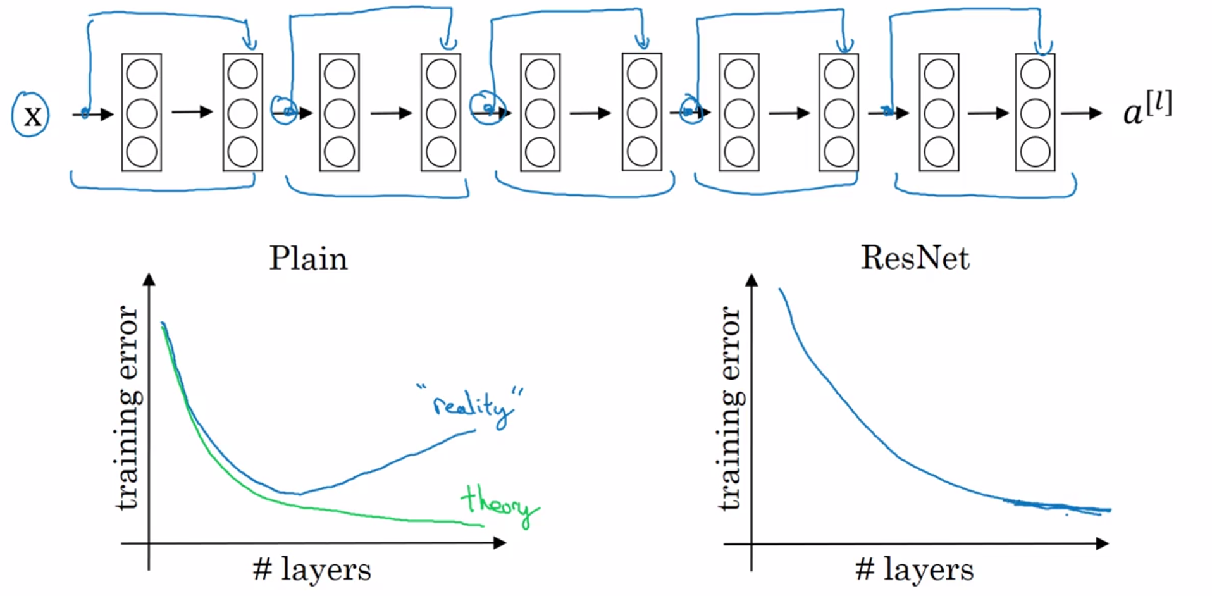
![]()
神经网络会随着层数的增加,训练误差减小,但数值传递的越深,任何一个细小的误差都会放大,训练误差反而增加。ResNet有助于解决梯度消失和爆炸问题,可以训练更深层的网络并保证良好的性能。
5.5 谷歌 Inception 网络
先介绍一下1×1卷积:

![]()
经过1×1的滤波器卷积后的图像宽和高不变,每个像素值仅与原图该像素的通道值有关。如果使用n个1×1的滤波器,那么就可以获得宽和高不变,通道数变为n的图像了。
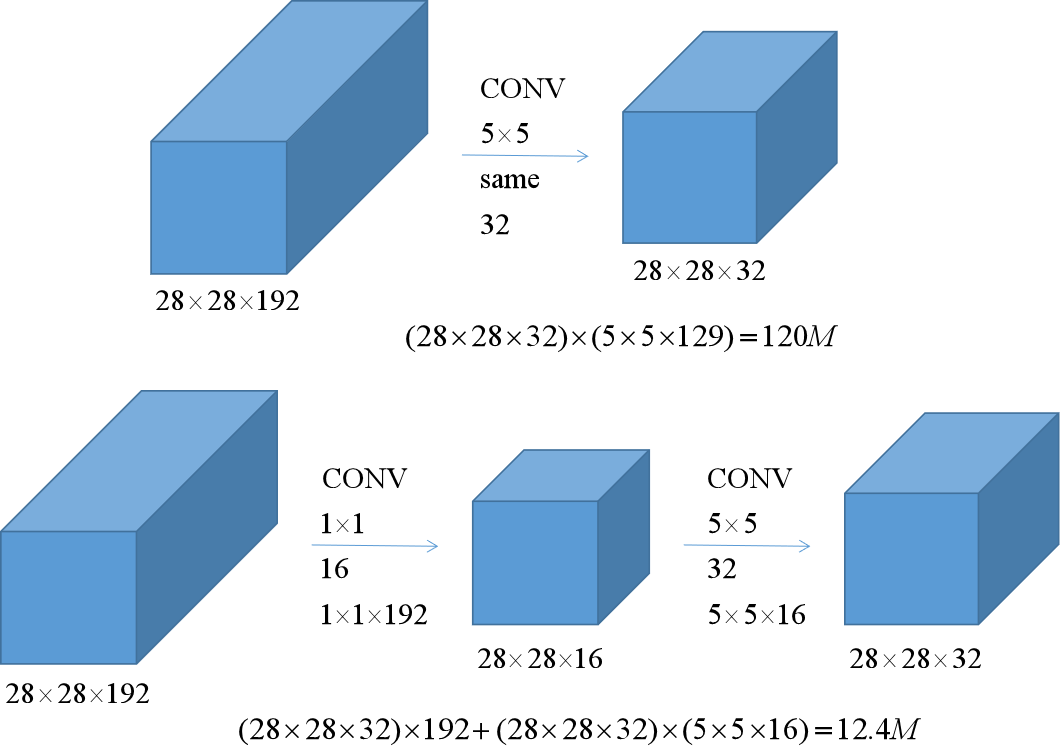
上图中,两种卷积效果基本相同,但下面的计算量仅为原来的十分之一。
Inception网络将几种卷积和池化方式放入一层计算,让网络自己选择用哪种方法:

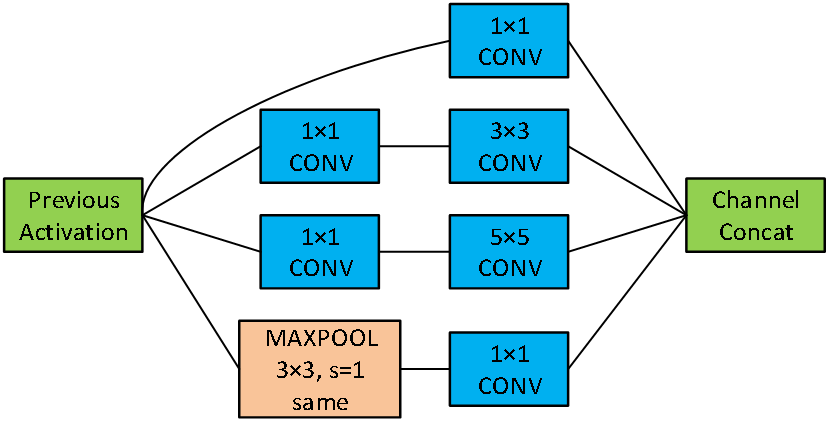
Inception network:
![]()
6. 迁移学习和数据扩充
6.1 迁移学习
如果当前任务可用数据较少,可以尝试使用别人已经训练好的网络,两个任务之间最好具有一定的相似性(例如我想训练一个识别猫的网络,可以用别人识别狗的网络)。然后删除该网络已有的softmax层,创建自己需要的softmax层。将修改后的网络前面几层参数全部冻结,只训练最后的softmax层。这样自己的训练集即使很小,也能获得不错的结果。
自己的训练集越大,需要冻结的层数就越少,可以训练的层数越多。
6.2 数据扩充
在计算机视觉领域,扩充数据对大多数任务都有帮助。常见的修改图片的方法有:镜像对称、随意裁剪、旋转、扭曲变换、色彩转换...
7. 目标检测
7.1 一些符号定义
假设我们检测的对象有:1 - pedestrian,2 - car,3 - motorcycle,4 - background(没有对象,只有背景)。
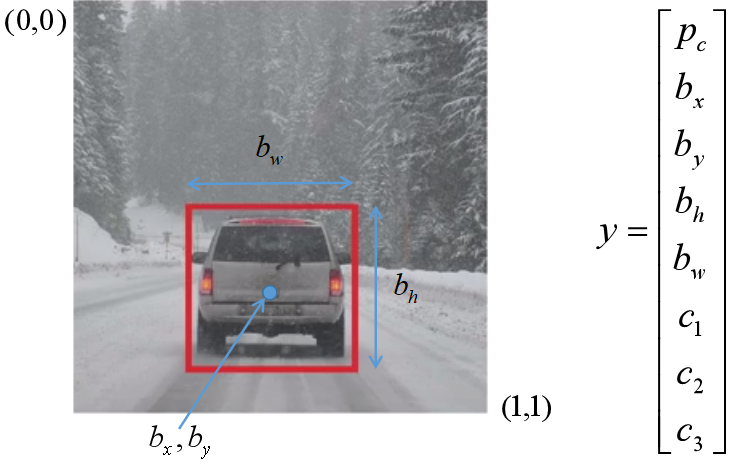 将上图输入到神经网络,那么应该输出是否检测到对象(pc=1,存在对象;pc=0,只有背景,此时后面七个参数没有意义)、检测到的对象位置及其边框信息(bx、by、bh、bw)、检测到哪个对象(c1、c2、c3,只有一个为1,其他为0)。上图的输出大概为:y = [1,0.5,0.7,0.3,0.4,0,1,0]。
将上图输入到神经网络,那么应该输出是否检测到对象(pc=1,存在对象;pc=0,只有背景,此时后面七个参数没有意义)、检测到的对象位置及其边框信息(bx、by、bh、bw)、检测到哪个对象(c1、c2、c3,只有一个为1,其他为0)。上图的输出大概为:y = [1,0.5,0.7,0.3,0.4,0,1,0]。
损失函数 (cost function):

7.2 特征点检测
这种方法需要先选定特征点个数,并生成包含这些特征点的标签训练集,然后利用神经网络输出关键特征点的位置。
例如下图中的人脸,如果有128个特征点,输出应该有129个参数(一个判断是否存在 face,其他是128个特征点位置)。

7.3 基于滑动窗口的目标检测 (Sliding windows detection)
该方法先选择一个小窗口,固定歩长滑动窗口,遍历图像,输入到卷积神经网络中判断,在增大窗口,重复以上操作...
但以上步骤的计算成本高,可以发现有很多冗余计算。

为了改善这个问题,这里先介绍如何将全连接层转换为卷积层:
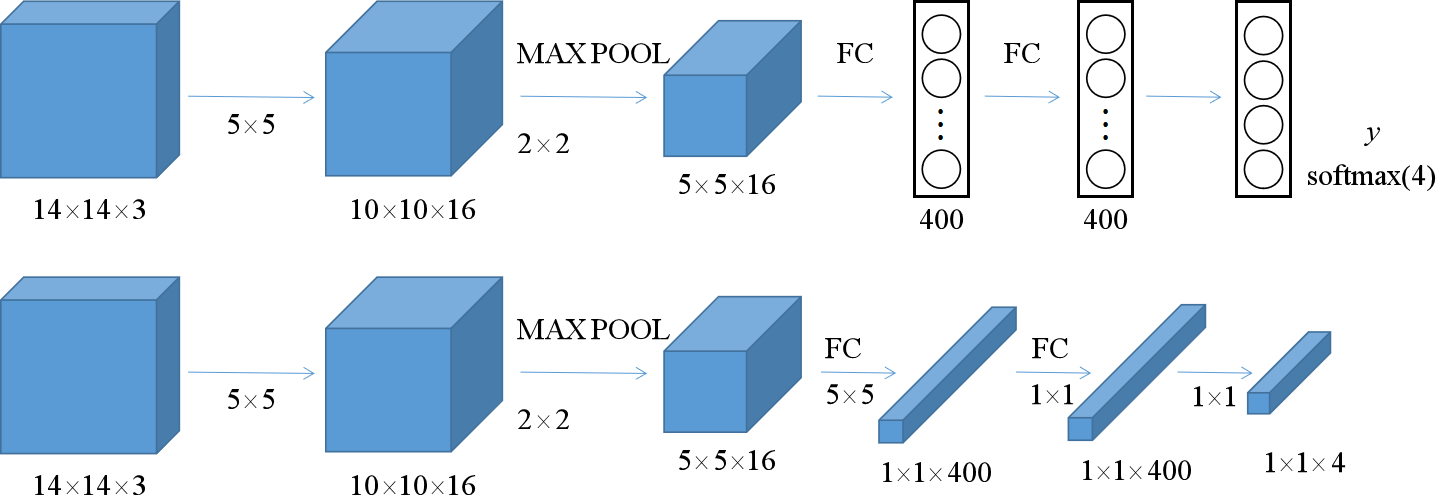
这两个网络是相同的,但下面的网络只有卷积运算了。
Convolution implementation of sliding windows:

假设我们的图片大小为16×16,窗口大小为14×14,滑动窗口后,需要向卷积神经网络输入四次并计算,如我们将整张图片直接输入,如上图,那么我们就不需要再重复计算了,没有再进行中间重叠部分的冗余计算了。
7.4 YOLO算法

这里使用了3×3的网格,实际使用中会使用更精细的网格 (如19×19),YOLO算法基本思路是将之前介绍的图像定位和分类算法应用到每个格子中,每个格子都会输出一个y(7.1所描述的y,但在这里,对象的位置是相对于所在的格子,而不是整张图片,bh和bw可能会大于1。每个对象根据中点的位置只会被分配到一个格子中,即使对象横跨几个格子。) ,所以这里的目标输出尺寸是3×3×8。
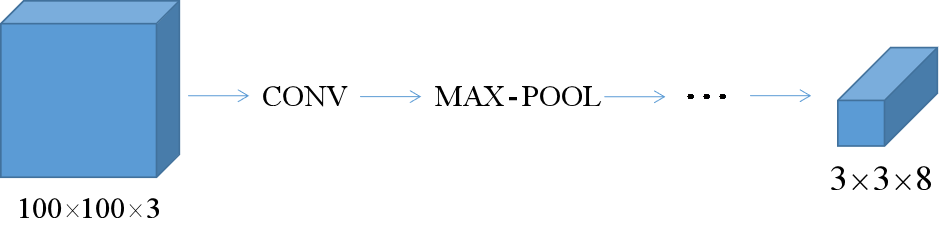
![]()
这样做的好处就是神经网络可以输出精确的边界框。因为只有一次卷积网络计算,所以YOLO的运行速度非常快,可以达到实时识别。
更多细节可以看原文文献,据说难度相对较高。
7.5 交并比 (Intersection over union)
交并比是为了判断目标检测算法运作是否良好,通过计算两个边框的交集和并集的比,一般大于0.5就认为是可接受的。

7.6 非极大值抑制 (Non-max suppression)
非极大值抑制是为了确保每个对象只被检测到一次。

在滑动窗口中,如果已经检测到多个边界框了:1)先抛弃概率 (Pc) 较低的输出边界框;2)在剩余的边界框中选择概率最高的边框,预输出;3)去掉剩下与该边框有高度重叠的边框;4)重复2~3步,直到处理完毕。

在YOLO中,也是类似的,先找到概率最大的格子,认为是最可靠的检测,标记,再逐一审视剩下的矩形,和这个边框有高交并比或高度重叠的其他边框会被抑制输出。
如果有多种对象,需要独立进行多次非极大值抑制。
7.7 Anchor boxes
如果一个格子或窗口中可能存在多个对象,那么久需要增加输出y的维度了:
![]()
这样的输出就可以检测出两个以内的对象了。
7.8 R-CNN
带区域的卷积网络 (R-CNN) 主要是尝试选出一些候选区域 ( Region proposals),在这些区域上运行卷积网络分类器,这样就可以只在少数窗口上运行了。例如下面的图像使用图像分割算法得到色块,在色块上运行卷积网络。

R-CNN运行很慢,也有很多改进算法,例如Fast R-CNN、Faster R-CNN等。
8. 人脸识别 (Face recognition)
Verification (验证):
- 输入:图像、名字或ID
- 输出:输入的图像是否是该名字或ID对应的人
Recognition (识别):
- 已有一个K个人的数据库
- 输入:图像
- 输出:图像中的人所对应的ID,或无法识别
Siamese network:对于两个不同的输入,运行相同的卷积神经网络,然后比较它们。损失函数:
![]()
Triple loss:训练对象是一个三元组 (anchor、positive、negative):
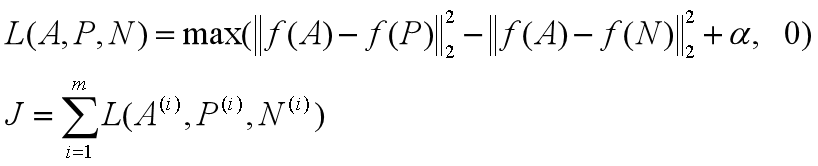
9. 风格迁移 (Neural style transfer)

10. 关于深层卷积神经网络到底在学什么
卷积神经网络的可视化:
层数越深,特征越复杂。
以上内容主要参考吴恩达《深度学习》课程第四课
tensorflow2.0 搭建卷积神经网络可见:tf.keras搭建CNN

 浙公网安备 33010602011771号
浙公网安备 33010602011771号