Redis
一、NoSql入门和概述
1、为什么用NoSql?


今天我们可以通过第三方平台(如:Google,Facebook等)可以很容易的访问和抓取数据。用户的个人信息,社交网络,地理位置,用户生成的数据和用户操作日志已经成倍的增加。我们如果要对这些用户数据进行挖掘,那SQL数据库已经不适合这些应用了, NoSQL数据库的发展也却能很好的处理这些大的数据。
2、NoSql是什么?

NoSQL(NoSQL = Not Only SQL ),意即“不仅仅是SQL”,
泛指非关系型的数据库。随着互联网web2.0网站的兴起,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题,包括超大规模数据的存储。
(例如谷歌或Facebook每天为他们的用户收集万亿比特的数据)。这些类型的数据存储不需要固定的模式,无需多余操作就可以横向扩展。
3、优点?
1、易扩展
NoSQL数据库种类繁多,但是一个共同的特点都是去掉关系数据库的关系型特性。
数据之间无关系,这样就非常容易扩展。也无形之间,在架构的层面上带来了可扩展的能力。
2、大数据量高性能
NoSQL数据库都具有非常高的读写性能,尤其在大数据量下,同样表现优秀。
这得益于它的无关系性,数据库的结构简单。
一般MySQL使用Query Cache,每次表的更新Cache就失效,是一种大粒度的Cache,
在针对web2.0的交互频繁的应用,Cache性能不高。而NoSQL的Cache是记录级的,
是一种细粒度的Cache,所以NoSQL在这个层面上来说就要性能高很多了
3、多样灵活的数据模型
NoSQL无需事先为要存储的数据建立字段,随时可以存储自定义的数据格式。而在关系数据库里,增删字段是一件非常麻烦的事情。如果是非常大数据量的表,增加字段简直就是一个噩梦
4、传统RDBMS VS NOSQL
RDBMS
- 高度组织化结构化数据
- 结构化查询语言(SQL)
- 数据和关系都存储在单独的表中。
- 数据操纵语言,数据定义语言
- 严格的一致性
- 基础事务
NoSQL
- 代表着不仅仅是SQL
- 没有声明性查询语言
- 没有预定义的模式
-键 - 值对存储,列存储,文档存储,图形数据库
- 最终一致性,而非ACID属性
- 非结构化和不可预知的数据
- CAP定理
- 高性能,高可用性和可伸缩性
4、3v+3高
大数据时代的3v
1、海量Volume
2、多样Variety
3、实时Velocity
互联网需求的3高
1、高扩展
2、高并发
3、高性能
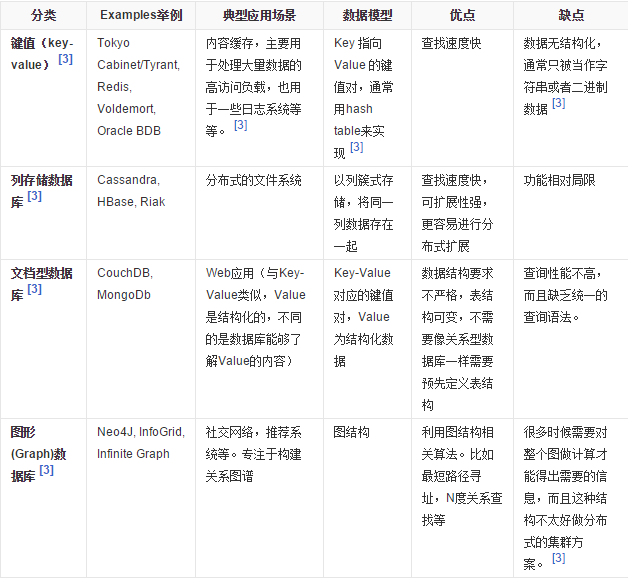
5、NoSql数据库的四大分类
1、KV键值 redis
2、文档型数据库(bson格式比较多) mongodb
3、列存储数据库 HBase
4、图关系数据库
6、在分布式数据库中CAP原理CAP+BASE
6.1 传统的ACID分别是什么
A (Atomicity) 原子性 C (Consistency) 一致性 I (Isolation) 独立性 D (Durability) 持久性
6.2 CAP
C:Consistency(强一致性) A:Availability(可用性) P:Partition tolerance(分区容错性)
6.3 CAP的3进2
CAP理论就是说在分布式存储系统中,最多只能实现上面的两点。
而由于当前的网络硬件肯定会出现延迟丢包等问题,所以
分区容忍性是我们必须需要实现的。
所以我们只能在一致性和可用性之间进行权衡,没有NoSQL系统能同时保证这三点。
=======================================================================================================================
C:强一致性 A:高可用性 P:分布式容忍性
CA 传统Oracle数据库
AP 大多数网站架构的选择
CP Redis、Mongodb
注意:分布式架构的时候必须做出取舍。
一致性和可用性之间取一个平衡。多余大多数web应用,其实并不需要强一致性。
因此牺牲C换取P,这是目前分布式数据库产品的方向
=======================================================================================================================
一致性与可用性的决择
对于web2.0网站来说,关系数据库的很多主要特性却往往无用武之地
数据库事务一致性需求
很多web实时系统并不要求严格的数据库事务,对读一致性的要求很低, 有些场合对写一致性要求并不高。允许实现最终一致性。
数据库的写实时性和读实时性需求
对关系数据库来说,插入一条数据之后立刻查询,是肯定可以读出来这条数据的,但是对于很多web应用来说,并不要求这么高的实时性,比方说发一条消息之 后,过几秒乃至十几秒之后,我的订阅者才看到这条动态是完全可以接受的。
对复杂的SQL查询,特别是多表关联查询的需求
任何大数据量的web系统,都非常忌讳多个大表的关联查询,以及复杂的数据分析类型的报表查询,特别是SNS类型的网站,从需求以及产品设计角 度,就避免了这种情况的产生。往往更多的只是单表的主键查询,以及单表的简单条件分页查询,SQL的功能被极大的弱化了。
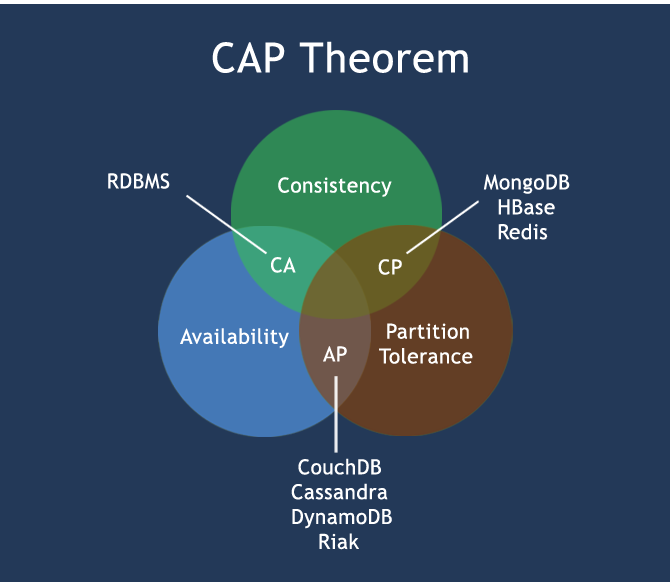
6.4 经典的CAP图
CAP理论的核心是:一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求,
最多只能同时较好的满足两个。
因此,根据 CAP 原理将 NoSQL 数据库分成了满足 CA 原则、满足 CP 原则和满足 AP 原则三 大类:
CA - 单点集群,满足一致性,可用性的系统,通常在可扩展性上不太强大。
CP - 满足一致性,分区容忍必的系统,通常性能不是特别高。
AP - 满足可用性,分区容忍性的系统,通常可能对一致性要求低一些。
6.5 BASE
BASE就是为了解决关系数据库强一致性引起的问题而引起的可用性降低而提出的解决方案。
BASE其实是下面三个术语的缩写:
基本可用(Basically Available)
软状态(Soft state)
最终一致(Eventually consistent)
它的思想是通过让系统放松对某一时刻数据一致性的要求来换取系统整体伸缩性和性能上改观。为什么这么说呢,缘由就在于大型系统往往由于地域分布和极高性能的要求,不可能采用分布式事务来完成这些指标,要想获得这些指标,我们必须采用另外一种方式来完成,这里BASE就是解决这个问题的办法
6.6 分布式和集群
分布式系统(distributed system)
由多台计算机和通信的软件组件通过计算机网络连接(本地网络或广域网)组成。分布式系统是建立在网络之上的软件系统。正是因为软件的特性,所以分布式系统具有高度的内聚性和透明性。因此,网络和分布式系统之间的区别更多的在于高层软件(特别是操作系统),而不是硬件。分布式系统可以应用在在不同的平台上如:Pc、工作站、局域网和广域网上等。
简单来讲:
1分布式:不同的多台服务器上面部署不同的服务模块(工程),他们之间通过Rpc/Rmi之间通信和调用,对外提供服务和组内协作。
2集群:不同的多台服务器上面部署相同的服务模块,通过分布式调度软件进行统一的调度,对外提供服务和访问。
二、Redis入门介绍
1、入门介绍
1.1 是什么?
1、Redis:REmote DIctionary Server(远程字典服务器)
2、是完全开源免费的,用C语言编写的,遵守BSD协议,
是一个高性能的(key/value)分布式内存数据库,基于内存运行
并支持持久化的NoSQL数据库,是当前最热门的NoSql数据库之一,
也被人们称为数据结构服务器
3、Redis 与其他 key - value 缓存产品有以下三个特点
3.1 Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用
3.2 Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储
3.3 Redis支持数据的备份,即master-slave模式的数据备份
1.2 能干嘛?

1.3 在哪下?
Http://redis.io/ Http://www.redis.cn/
1.4 怎么玩?

2、VMWare+VMTools千里之行始于足下

3、Redis的安装

启动命令:redis-server /myconf/redis.conf redis-cli -p 6379
4、Redis启动后杂项基础知识讲解

三、Reids的数据类型
1、Redis的五大数据类型
1:String(字符串)
string是redis最基本的类型,你可以理解成与Memcached一模一样的类型,一个key对应一个value。
string类型是二进制安全的。意思是redis的string可以包含任何数据。比如jpg图片或者序列化的对象 。
string类型是Redis最基本的数据类型,一个redis中字符串value最多可以是512M
2:Hash(哈希,类似java里的Map)
Redis hash 是一个键值对集合。
Redis hash是一个string类型的field和value的映射表,hash特别适合用于存储对象。
类似Java里面的Map<String,Object>
3:List(列表)
Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素导列表的头部(左边)或者尾部(右边)。
它的底层实际是个链表
4:Set(集合)
Redis的Set是string类型的无序集合。它是通过HashTable实现实现的
5:Zset(sorted set:有序集合)
Redis zset 和 set 一样也是string类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个double类型的分数。
redis正是通过分数来为集合中的成员进行从小到大的排序。zset的成员是唯一的,但分数(score)却可以重复。
2、哪里去获得redis常见数据类型操作命令
Http://redisdoc.com/
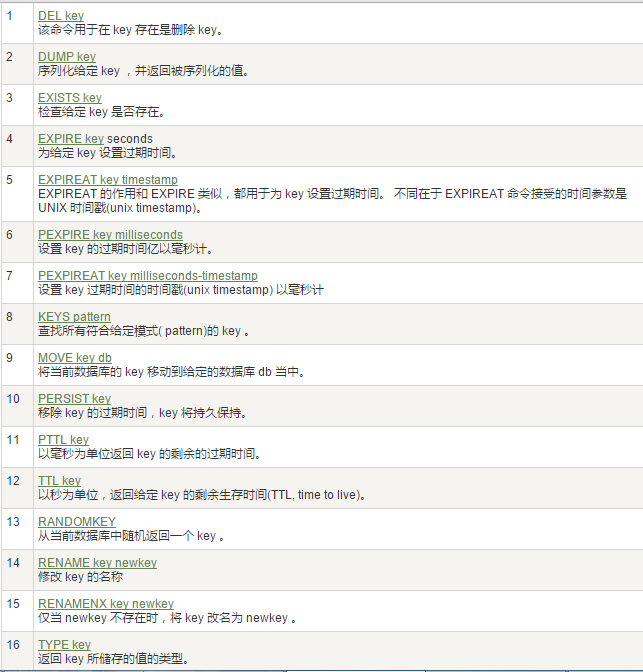
3、Redis 键(key)

4、Redis字符串(String)
特点:单key单value


5、Redis列表(List)
特点:单key多value

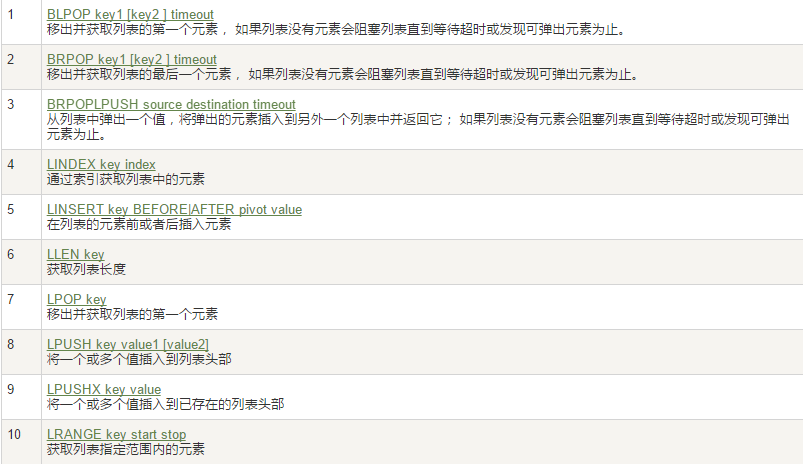
它是一个字符串链表,left、right都可以插入添加;
如果键不存在,创建新的链表;
如果键已存在,新增内容;
如果值全移除,对应的键也就消失了。
链表的操作无论是头和尾效率都极高,但假如是对中间元素进行操作,效率就很惨淡了。
6、Redis集合(Set)
特点:单key多value

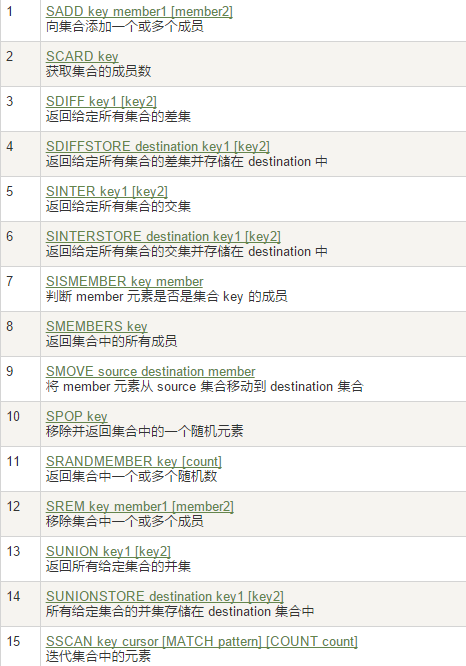
7、Redis哈希(Hash)
特点:KV模式不变,但V是一个键值对

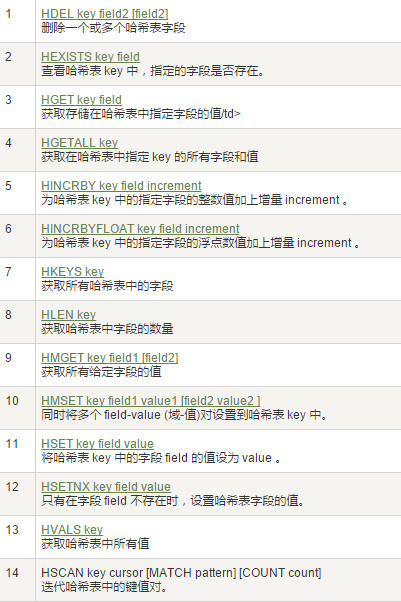
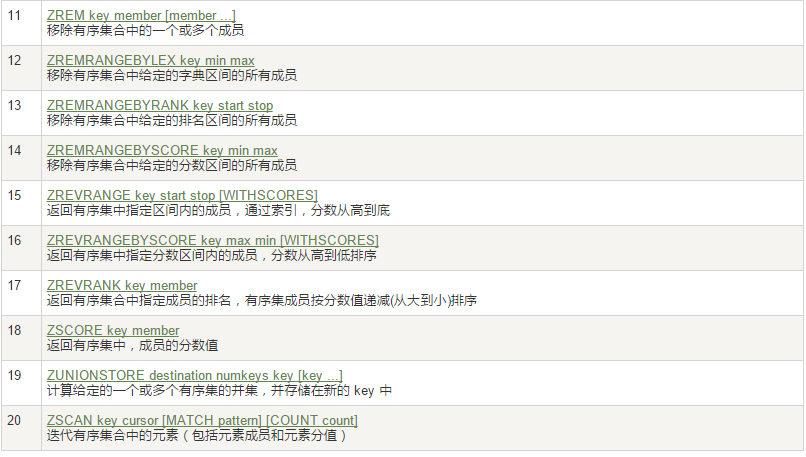
8、Redis有序集合Zset(sorted set)
特点:在set基础上,加一个score值。之前set是k1 v1 v2 v3,现在zset是k1 score1 v1 score2 v2

四、解析配置文件redis.conf



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~
2020-04-20 Linux学习笔记