Rust之路(3)——数据类型 下篇
【未经书面同意,严禁转载】 -- 2020-10-14 --
架构是道,数据是术。道可道,非常道;术不名,不成术!道无常形,术却可循规。
学习与分析数据类型,最基本的方法就是搞清楚其存储原理,变量和对象数据是在栈、堆、静态区如何分布。把数据和数据的表现形式抓住了,就能很快地明白类型的行为、转换,还有Rust牵扯到所有权和所有权移动、借用。
书接上回!
数据类型上篇依次阐述了整型、浮点型、布尔、字符型、元组、指针、数组和向量。除了向量,其他都属于基本类型,在赋值、传参时是复制一份传递过去(即值传递),而向量是引用传递类型,赋值或传参的时候,传递的是存储在栈上的指针和相关信息,而数据本身在堆内存不动。
本篇关注一下最常用的另外几种类型:切片、字符串(以及文本字符串)。
切片Slice
切片其实不是真正的“数据”类型,而指的是别人的一段数据。顾名思义,切片就是从别的序列类型(如数组、向量等)上面切了一段的数据(当然,这一段还是属于别人的一部分,并没有切下)。
但这个切片,在实际代码中是没法用的,数据属于别人的,由于Rust的所有权概念(下篇讲这个),别人的东西不能直接拿来用。而是用另一种形式使用:引用。
现在,可以把引用理解为指针。
切片的类型写法是 [T],其中T是切片中元素数据的类型,可以是u8、String等等。切片引用的写法是&[T]。后者在代码中更常用。
而切片通常指的就是前文所说的切了一段数据的引用,切片的引用包含1个指针、1个数据长度(切片所切的元素数目)。比如:
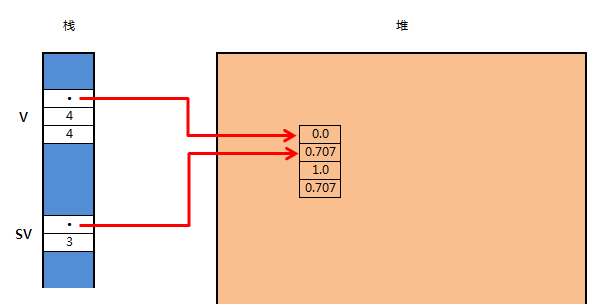
let v: Vec<f64> = vec![0.0, 0.707, 1.0, 0.707]; //一个向量
let sv: &[f64] = &v[1..3]; //sv是切片引用,指向v的索引1的元素至索引3的元素(不包括索引3的元素),切片有2个元素
/* &v[1..3]中,中括号内的表达式由两个整数和一个..操作符构成,..操作符是range生成操作符,产生一个range类型(其实
根据两个整数是否省略分为4种类型,统称为range类型)的值。用于序列类型的后面,产生一个子序列。两个整数形成一个前闭
后开的区间,此例中是[1,3)。如果需要包含右边的整数索引,可以写成[1..=3];如果从切片是从开始元素到索引2,则可以
写成[..3];从索引2到末尾,写成[2..];取其所有元素,简写为[..]。
*/
其内存分布图为(图中sv中的数字2就是切片的元素数):
甚至可以把整个序列的引用赋值给一个切片引用:
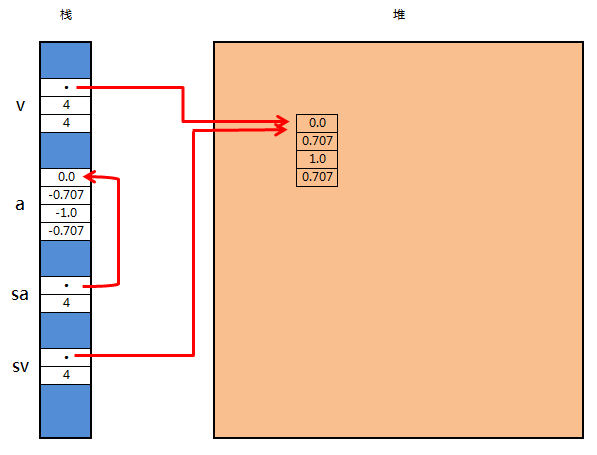
let v: Vec<f64> = vec![0.0, 0.707, 1.0, 0.707]; //一个向量,数据在堆上 let a: [f64; 4] = [0.0, -0.707, -1.0, -0.707]; //一个数组,分布在栈上 let sv: &[f64] = &v; //sv是包含向量v所有元素的切片引用,由向量v的引用转换得到 let sa: &[f64] = &a; //sa是包含数组a所有元素的切片引用,由数组a的引用转换得到
在最后两行,Rust会自动将&Vec<f64>引用和&[f64;4]引用转换为直接指向数据的切片引用。
其内存分布图为:
想编写一个对任何同类型数据序列(无论是存储在数组、向量、堆栈或堆中)进行操作的函数时,切片引用都是一个不错的选择。例如,这里有一个函数可以打印一段数字,每行一个:
fn print(n: &[f64]) { for elt in n {
println!("{}", elt); } } print(&v); // works on vectors 可以用于vector print(&a); // works on arrays 可以用于数组
因为这个函数接受切片引用作为参数,所以可以将它应用于向量或数组。实际上,Rust在切片上定义了很多方法:例如,sort和reverse方法,都可以运用在向量或数组上,对其元素进行排序或反转。
最后再重复一次,真正的切片是母序列的一段数据。由于切片几乎总是以引用出现,所以通常说的切片,实际上是切片引用&[T]。
字符串String 和文本字符串(或称为字符串字面量 英文为String Literal)
Rust中,最常用的两种字符串:字符串字面量str类型、可变字符串String类型。另外还有CString、OsString等,以后用到再说。
字符串字面量是指的一串文本,因为它是确定的,不像变量一样变化,所以在程序中硬编码到程序文件内,是静态的,我们不能移动或改变这串文本。字符串字面量用双引号括起来。特殊字符用反斜杠转义序列,也可以换行:
let speech = "\"Ouch!\" it's said the well.\n"; //单行文本,双引号需要转义,但单引号不需要
//多行文本,Singing后有一个空格和换行符,第二行的前面有多个空行。打印时这些都会保留 println!("In the room the women come and go, Singing of Mount Abora");
//末尾有反斜杠转义,虽然第一行的末尾和第二行前面有多个空格、换行符,但是在and和there中间只输出一个空格!
println!("It was a bright, cold day in April, and \ there were four of us—\ more or less.");
在一些情况下,需要将字符串中的反斜杠转义是一种麻烦的事情(比如在正则表达式和Windows路径)。用小写字母“r”标记为原始字符串(raw string)。原始字符串中的所有反斜杠和空白字符都会逐字包含在字符串中。不会进行转义。但问题是,双引号就没法输入了(因为不存在转义,所以加反斜杠也没用),这时候可以在原始字符串的开始和结束加“#”号标记:
let default_win_install_path = r"C:\Program Files\Gorillas"; //Windows路径 let pattern = Regex::new(r"\d+(\.\d+)*"); //正则表达式 //用字母r和#表示的原始字符串,r是raw string的首字母 println!(r###" This raw string started with 'r###"'. Therefore it does not end until we reach a quote mark ('"') followed immediately by three pound signs ('###'): "###);
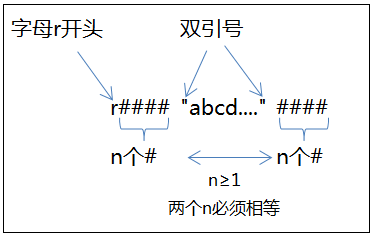
加“#”的原始字符串,规则是:字母r,后面是n个#(n≥1),后面跟双引号引起来的字符串,后面是n个#(跟前面的n必须相等):
可变的字符串
内容和长度可变的字符串是String类型,和大多数语言中的可变字符串相似。但是也有很多严格不同之处。就像开头所述,要明白它的行为,需要先摸清它在内存是怎么存储的。
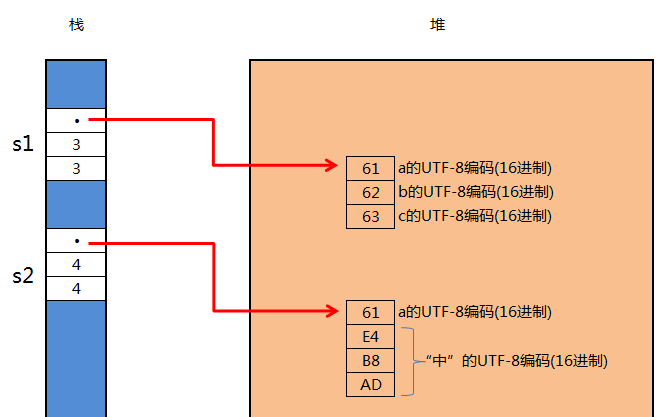
String存储一串字符,字符的编码是UTF-8,而UTF-8是变长的,前篇我们已经详解了。所以存储了“abc”的字符串长度是3个字节,而存储了“a中”的长度是4个字节,其中中文占3字节。
let s1: String = "abc".to_string(); let s2: String = "a中".to_string();
println!("{} {} {} ", s1, s1.capacity(), s1.len()); //输出 abc 3 3
println!("{} {} {} ", s2, s2.capacity(), s2.len()); //输出 a中 4 4
亮点来了哈:
如果用len()函数计算字符串的长度,结果是字节数,而不是有多少个字符!!所以,无法把字符串简单的看做字符的数组,也就不能直接用索引法 s1[1]来表示第2个字符,也不能用for...in 来遍历字符串!!
当然,切片也不建议用,因为s1[1..3]能正确的得出是“bc”,而s2[1..3]则会出错,因为这个切片是切了“中”字三个字节当中的前两个字节。
这么神奇吗?
作为最常用类型,当然不会这么弱智!办法是用到String类型的chars方法。s1.chars()返回一个序列类型(类型名称是Chars),包含了a、b、c三个元素,s2.chars()返回的序列包含a、中两个字符(序列的类型是前面我们讲到的char类型,每个char类型占4字节空间)。
所以,索引、迭代、切片的使用方法,都可以用在这个序列上!
String的用法(更多用法可以查参考手册):
//创建字符串 let s1 = "too many pets".to_string(); //用字符串字面量的to_string方法 let s2 = format!("{}年龄:{}", "林冲", 29); //用format!宏创建,它的使用方法和printnl!宏相同,但是末尾不加换行 let bits = vec!["阮小二", "阮小五", "阮小七"]; assert_eq!(bits.concat(), "阮小二阮小五阮小七"); //用序列类型的concat方法 assert_eq!(bits.join(", "), "阮小二, 阮小五, 阮小七"); //用序列类型的join方法,可以在各元素中间加间隔符 //比较 assert!("ONE".to_lowercase() == "one"); //支持比较运算符==、!=、>、<、<=、>和>= //一些方法
let mut s = String::from("源字符串"); //必须声明为mut,才能改变字符串的内容 assert_eq!(s.pop(), Some('o')); //弹出最后一个字符,返回一个Option类型,其中包装了弹出的值,或者None
s.push("新增"); //追加到末尾 assert!("peanut".contains("nut")); //是否包含文字 assert_eq!("?_?".replace("?", "■"), "■_■"); //替换 assert_eq!(" clean\n".trim(), "clean"); //去除收、尾的空格、换行符等等空白字符 for word in "veni, vidi, vici".split(", ") { //分割为字符串序列 assert!(word.starts_with("v")); //测试开始字符串,ends_with是测试末尾 }
&str类型
&str是一种引用类型,类似切片,引用了字符串字面量或者是String的一段,它其实也是一个组合指针:包括引用目标的指针和引用的长度(当然也是以占用字节数计量的)。
&str最大的用处是在函数传参中。因为它可以引用任何字符串的任何片段,不管它是字符串字面量文本(存储在可执行文件中)还是字符串(在运行时分配和释放)。想让函数允许传递任何一种字符串的参数时,&str比其他字符串类型更适合。
最后,说一下引用和非引用。
引用的实质是指针,在C语言中,如果用指针所指的值,需要解引用;在C++中有引用类型,它掩盖了解引用的步骤:
// C或C++
int a = 32; int *ra = &a; //修改a的值 *ra = 64; // 在C++代码中 int x = 10; int &r = x; // initialization creates reference implicitly r = 20; // stores 20 in x, r itself still points to x
在Rust中,指针类型其实也需要解引用。使用&运算符显式创建引用,并使用*运算符显式解引用:
// 在Rust中 let x = 10; let r = &x; // &x 是指向 x 的引用 assert!(*r == 10); // 显式地解引用r
但是,在需要的时候,点.运算符为解引用提供了便利,可以隐式解引用其左操作数而不用写 *,这在面向对象代码中大量使用。例如访问结构体对象的元素或元组中的元素:
let t = (123, "bubble", "测试");
let rt = &t; //元组的引用
assert_eq!(rt.2, "测试"); // 和上面一句相同: assert_eq!((*rt).2, "测试");
struct Anime { age: i32, bechdel_pass: bool }; let aria = Anime { age: 32, bechdel_pass: true }; let anime_ref = &aria; //结构体的引用 assert_eq!(anime_ref.age, 32); // 和上面一句相同: assert_eq!((*anime_ref).age, 32);
字符串在各种语言中都是最常用的,但是其复杂度经常超出普通人的想象。所以,有坑慢慢踩,且行且珍惜!
除了上篇和本篇,还有三种用户自定义类型:结构体struct、枚举enum和特性trait:struct、enum类似其他语言里的结构体/类和枚举,但也有很多不同之处,不可混为一谈。trait在其他语言中也有出现,但本人不是太了解其他语言的trait是什么......
这三种类型将在后面分别单独阐述。
基础的数据类型就到这里吧,下篇开始进入Rust的核心!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号