Transformer、BERT
Transformer
自 Attention 机制提出后,加入 Attention 的 seq2seq 模型在各个任务上都有了提升,所以现在的 seq2seq 模型指的都是结合 RNN 和 Attention 的模型。
Transformer 模型使用了 self-Attention 机制,不采用 RNN 的顺序结构,使得模型可以并行化训练,而且能够拥有全局信息。
下图是 Transformer 的结构。左边是 encoder,右边是 decoder。encoder 和 decoder 都先采用 self-Attention 计算上下文向量,再加上 decoder 中 attention 的使用。
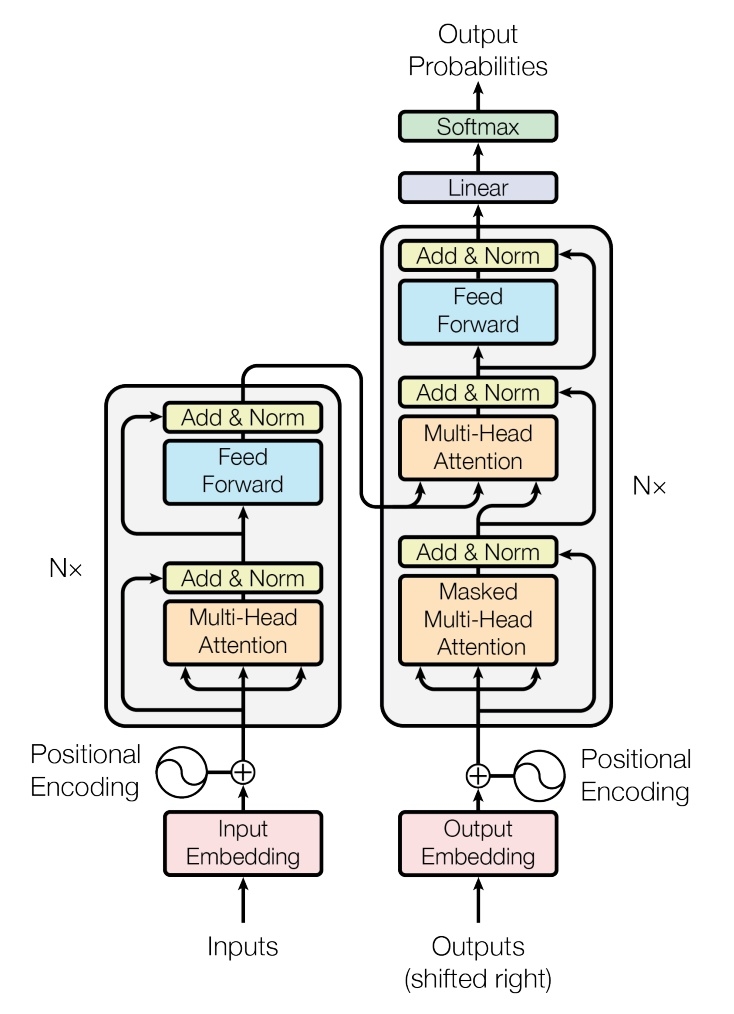
(1)encoder
每个层由两个部分组成,分别是 multi-head self-attention mechanism 和 fully connected feed-forward network。“N×” 就是有几层,这里都是 6 层。
① multi-head self-attention mechanism
首先 Scaled Dot-Product Attention 公式如下,在 QKT 之后,为了防止其结果过大,会除以根号 dk,dk 由 Q 和 K 的 维度决定。
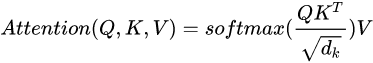
而 multi-head self-attention mechanism 就是把输入分割成 n 个(论文中为8),然后对每份进行 Scaled Dot-Product Attention,再把输出合起来。每个 head 可以学习到在不同表示空间中的特征。
② fully connected feed-forward network
全连接层,主要用来提供非线性变换。
是一个两层的全连接层,第一层的激活函数为 Relu,第二层不使用激活函数
(2)decoder
输入:encoder 的输出以及对应前一位置 decoder 的输出。所以中间的 attention 不是 self-attention,它的K、V来自 encoder 的输出,Q来自上一位置 decoder 的输出。
输出:对应位置的输出词的概率分布。
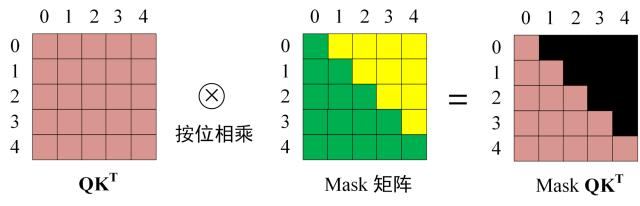
第二层和第三层与 encoder 中的相似。第一层的 attention 多加了一个 mask,因为只能 attention 只能知道到前面已经翻译过的输出的词语,翻译过程中还并不知道下一个输出词语,这是之后才会推测到的。mask 操作产生一个上三角矩阵,上三角的值全为0,Softmax 之前需要使用 Mask 矩阵(与 QKT 相乘)遮挡住每一个单词之后的信息。
Transformer 中,每层都有Add & Norm。Add 表示残差连接,用于防止网络退化;Norm 表示 Layer Normalization,进行归一化,将每一层神经元的输入都转成均值方差都一样的,这样可以加快收敛。
还注意到在输入之后,有一个 Positional Encoding,Transformer 不采用 RNN 的结构,而是使用全局信息,不能利用单词的顺序信息,而这部分信息对于 NLP 来说非常重要,否则 Transformer 就是一个词袋模型了。所以 Transformer 中使用 Positional Encoding 保存单词在序列中的相对或绝对位置。PE 的维度与单词 Embedding 是一样的。
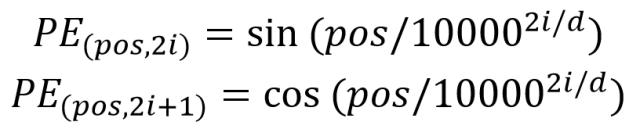
上述公式表示的是绝对位置,选择这个公式的原因是它可以用三角函数转换表达相对位置。细节可以看这篇 https://zhuanlan.zhihu.com/p/137615798。
总结:
Transformer 与 RNN 不同,可以比较好地并行训练,计算速度更快。
Transformer 的重点是 self-Attention 结构,其中用到的 Q, K, V矩阵通过输出进行线性变换得到。
数据量大可能用 Transformer 好一些,数据量小的话还是 RNN-based model。
BERT
Bidirectional Encoder Representation from Transformers,即双向 Transformer 的 Encoder。
BERT模型实际上是一个语言编码器,把输入的句子或者段落转化成特征向量(embedding)。
论文中有两大亮点:1. 双向编码器。作者沿用 Tansformer,并提出双向的概念,利用 masked 实现双向;2. 作者提出了两种预训练的方法:Masked-LM 和 Next Sentence Prediction 方法。作者认为现在很多语言模型低估了预训练的力量。masked 语言模型比起预测下一个句子的语言模型,多了双向的概念。
下图最左为 BERT 的基本结构。
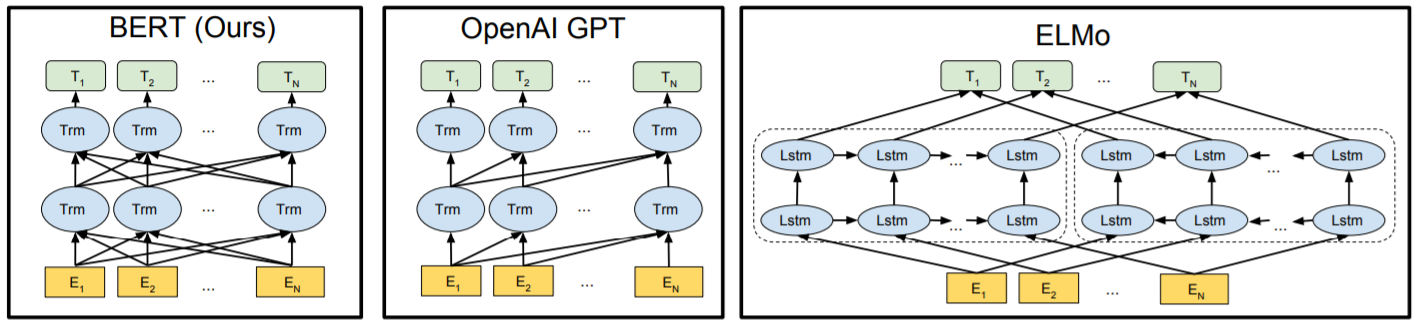
ELMo:使用 LSTM的方法实现。用双向 LSTM 获得前后上下文的信息。
OpenAI GPT:通过 Transformer 学习出来一个语言模型,也就是缺少了 encoder 的 Transformer(使用的 decoder 去掉第二层 self-Attention层 )。
GPT 和 ELMo 很大的不同就是在使用上,不再是将模型当作一个精致的特征提取器,后再加上特定模型,而是将模型当作处理大量特定问题的基础模型,再上面进行 fine-tuning。就是把 pre-train 的模型当作基础模型,特定问题只需要再上面做 fine-tuning(加特定输出结构,改变输入格)的模式。
而 BERT 在 OpenAI GPT 的基础上,使用双向的 Transformer block 连接。
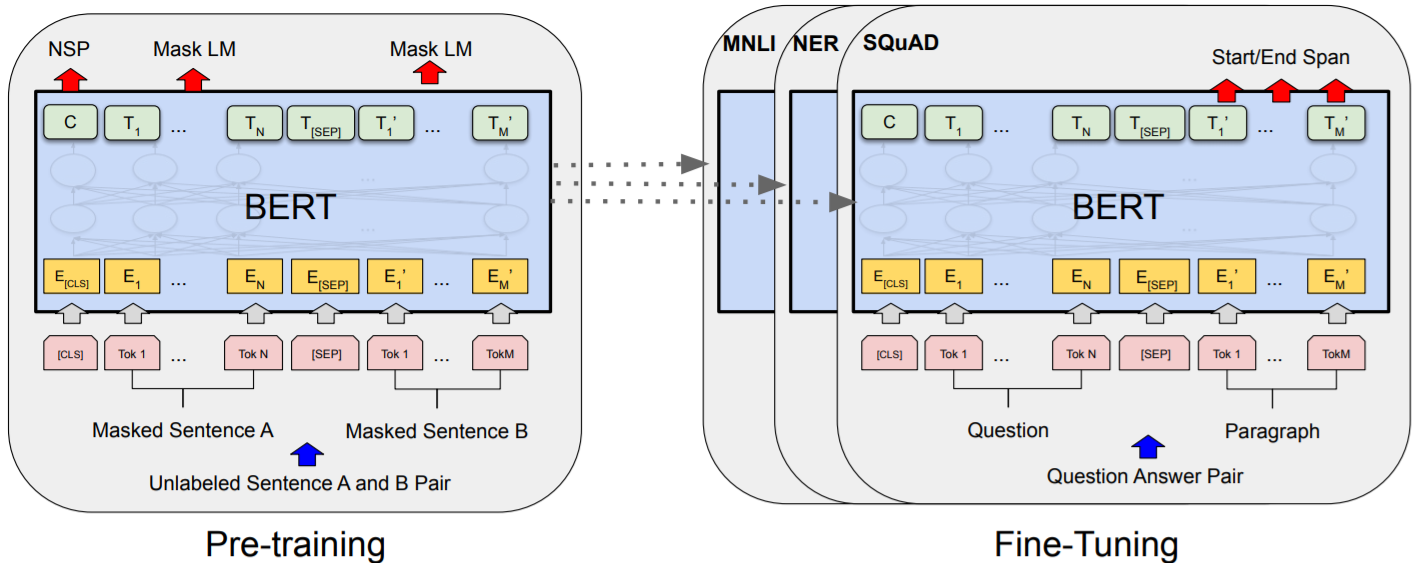
整体分为两个过程:
1. pre-train(预训练)过程是一个 multi-task learning,迁移学习的任务,目的是学习输入句子的向量。
2. fine-tuning(微调)微调参数(改变预训练模型参数)或者特征抽取(不改变预训练模型参数,只是把预训练模型的输出作为特征输入到下游任务)两种方式。
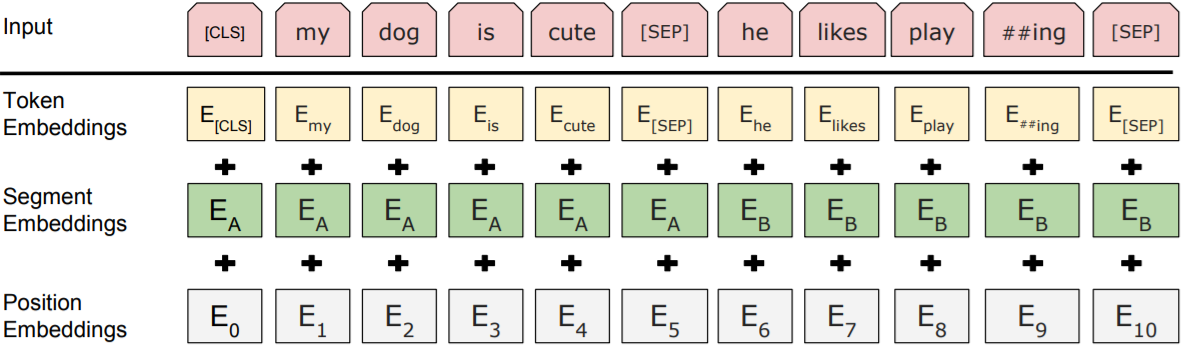
(1)输入
BERT 对输入做了更宽泛的定义,输入表示既可以是一个句子也可以一对句子(比如问答)。
Token Embeddings 是词向量,每个输入的第一个位置放 CLS 标注(CLS 就是 class 简写),每个句子结尾用 SEP 标注。
Segment Embeddings 用来区别两种句子,因为预训练不光做 LM,还要做以两个句子为输入的分类任务(区分是否噪声)。对于句对来说,EA 和 EB 分别代表左句子和右句子;对于句子来说,只有 EA。
Position Embeddings 和之前文章中的 Transformer 不一样,不是三角函数而是学习出来的。
这三个向量都是训练得到的。
(2)pre-train:Masked 语言模型(Masked LM)
Masked 语言模型是为了训练深度双向语言表示向量。 模型使用 n(论文中 n = 12 或 24)层 Transformer 的 encoder 层。
训练方法为:作者随机遮住 15% 的单词。
① 其中 80% 用 [mask] 来代替。
② 10% 用随机的一个词来替换。
③ 10% 保持这个词不变。
输入为完整的句子,模型根据句子预测这句话中的每一个词,最后只计算 [mask] 词的损失。
encoder 不知道它将被要求预测哪些单词或哪些单词已被随机单词替换,因此它被迫保持每个输入token的分布式上下文表示。
10% 的随机替换是因为,如果 [mask] 只会出现在构造句子中,Fine-tunning 中不会出现 [mask] ,就会造成了预训练和微调之间的不匹配。
此外,因为随机替换只发生在所有token的 1.5%(即15%的10%),对模型的语言理解能力的损害可以忽略不计。
编码器不知道哪些词需要预测的,哪些词是错误的,因此被迫需要学习每一个 token 的表示向量。
(3)pre-train:Next Sentence Prediction
训练一个二分类的模型,来学习句子之间的关系。
选择一些句子对 A 与 B,其中 50% 的数据 B 是 A 的下一条,剩余 50% 的 B 是语料库中随机选择的。输入这两个句子,模型预测 B 是不是 A 的下一句。
pre-train 的两部分,MLM 完成语义的大部分的学习,NSP 学习句子级别的特征。两部分的输组合在前面图里的 pre-train,就是 NSP 的输出放在首位,MLM 的输出放在后面。
(4)Fine-tuning
BERT 将传统大量在下游具体 NLP 任务中做的操作转移到预训练词向量中,BERT 预训练模型的输出结果,无非就是一个或多个向量。下游任务可以通过精调(改变预训练模型参数)或者特征抽取(不改变预训练模型参数,只是把预训练模型的输出作为特征输入到下游任务)两种方式进行使用。
一般加上 FFNN(分类再加个 softmax)就好了。
论文中主要出现的四种任务如下图所示。
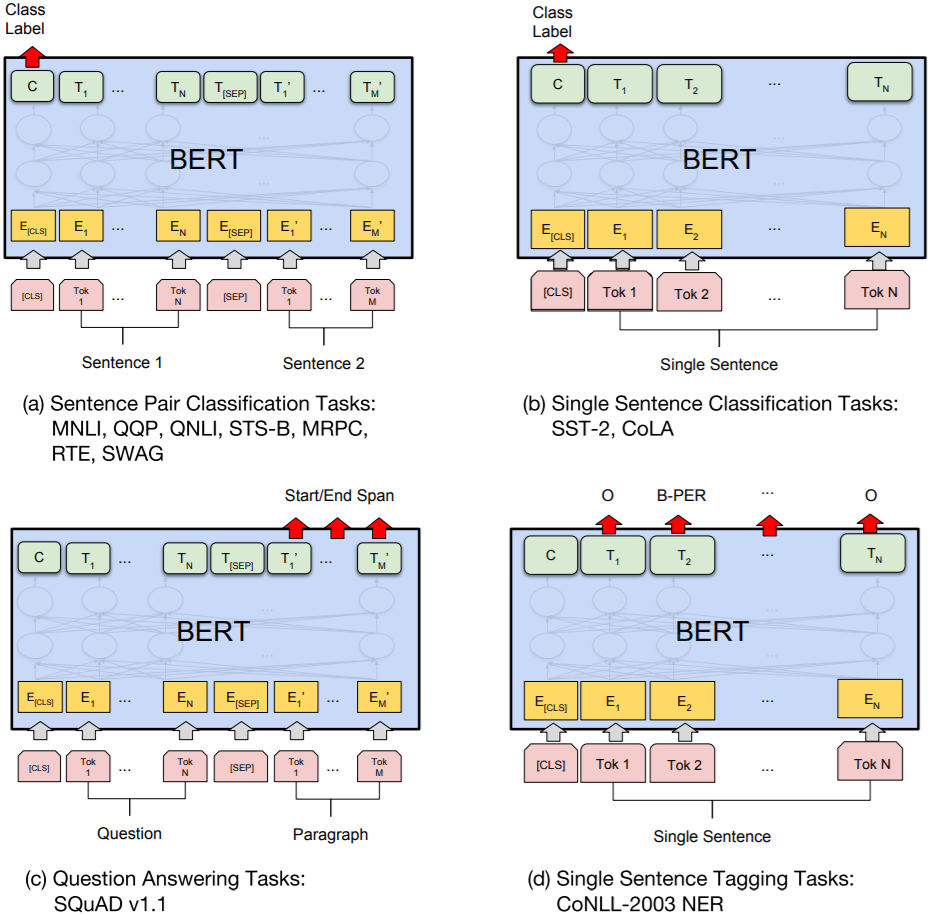
(a)句子关系判断(句对匹配)
输出的第一个位置为类别标签。
(b)单句分类任务(情感分类等)
输出首位置为类别标签。单句分类就不需要 [SEP] 符号了。
(c)问答任务(问答、翻译等)
加感知机。句子对变成问题和文章,输出 span 的起点和终点。
(d)单句标注(命名实体识别等)
每个输入对应一个输出。
总结:
预训练使用了 MLM,使用双向 LM 做模型预训练。预训练使用了 NSP,它可以学习句子与句子间的关系。
为下游任务引入了很通用的求解框架,不再为任务做模型定制。
优点:
Transformer Encoder 因为有 Self-attention 机制,因此BERT自带双向功能。
BERT 加入了 NSP 来和 MLM 一起做联合训练,获取比词更高级别的句子级别的语义表征。
BERT 设计了更通用的输入层和输出层,适配多任务下的迁移学习。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号