LSTM、RNN、GRU
RNN
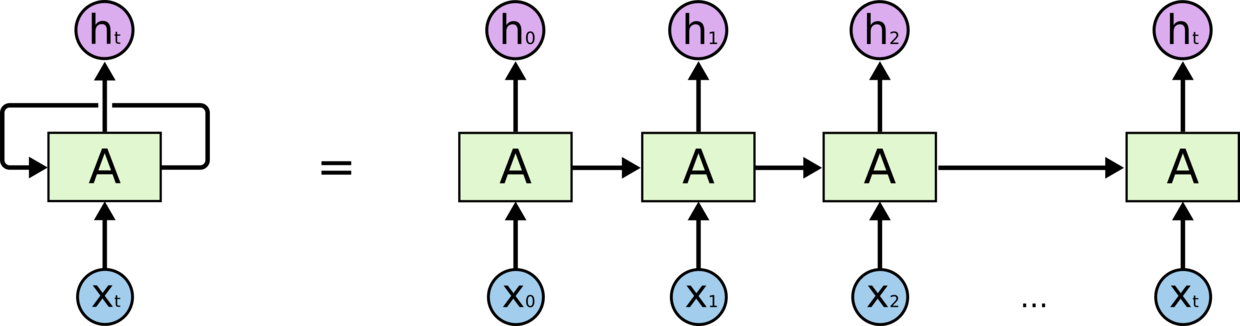
Recurrent Neural Networks,即循环神经网络,是一种时间上进行线性递归的神经网络。
它在每个时刻接收一个输入 xt 和上一时刻的隐藏状态 ht-1,计算得到 ht。
左侧是模型的基本结构,右侧就是它在时间上进行展开的示意图。
RNN 中常用的激活函数是 tanh。
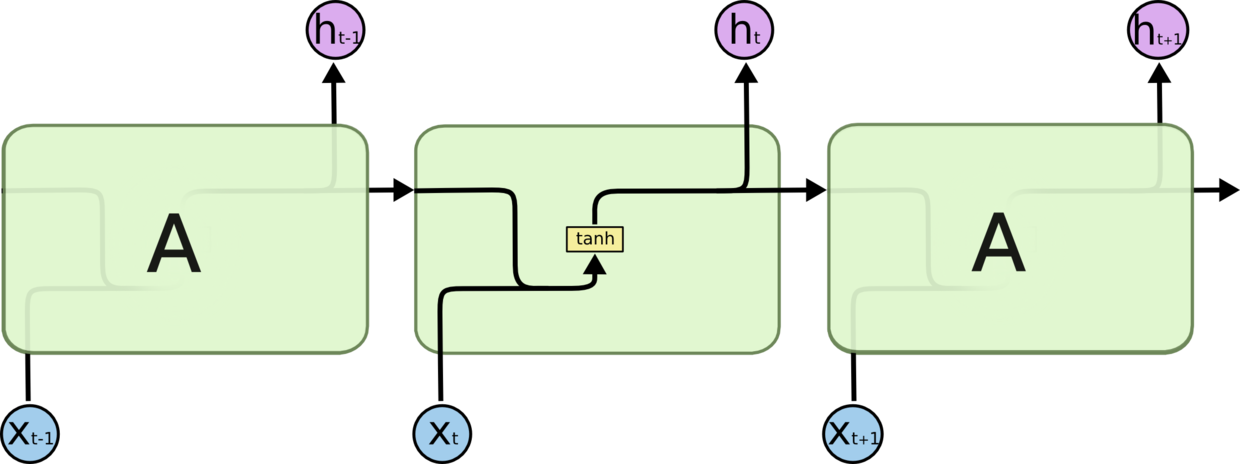
而RNN中的问题:
① t 时刻的激活函数导数会传播到 t-1,t-2,... ,1 时刻,这样就有了连乘的系数,会导致梯度消失和梯度爆炸。(求解梯度使用 BPTT 算法)
② 前向过程中,开始时刻的输入对后面时刻的影响越来越小,这就是长距离依赖问题。
LSTM
Long Short Term Memory 网络的神经元使用了三个门结构:输入门、输出门、遗忘门。整体上除了隐藏状态h在随时间流动,细胞状态C也在随时间流动,细胞状态C就代表着长期记忆。每个时刻 Ct = Ct-1 * 遗忘门 + 输入门,同时它经过 tanh 后又是输出门的因子之一。

(1)遗忘门:决定丢弃哪些信息。
ht-1 与 xt 通过 sigmoid 确定哪些信息保留或丢弃多少。
![]()
(2)输入门:决定给细胞状态添加哪些新的信息。
ht-1 与 xt 通过 sigmoid 确定要更新哪些地方以及更新多少。ht-1 与 xt 通过 tanh 得到要更新的信息。这两个值相乘得到更新的具体内容。
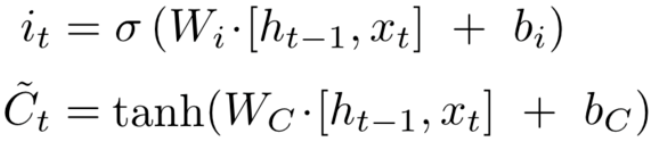
(3)遗忘门与输入门更新 C。
遗忘门得到的数值乘以 C,实现了遗忘。加上输入门得到的数值,把新内容加入 C 中,这样使用输入对 C 进行了更新。
![]()
(4)输出门:ht-1 与 xt 通过 sigmoid 确定输出哪些地方以及输出权重,C 通过 tanh 得到要输出的信息。相乘得到输出值。
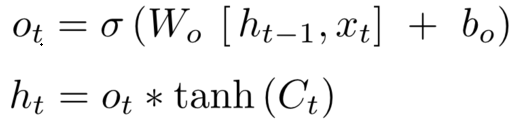
LSTM 能避免梯度消失;而梯度爆炸不是个严重的问题,一般靠裁剪后的优化算法即可解决,比如 gradient clipping(如果梯度的范数大于某个给定值,将梯度同比收缩)。
为何 LSTM 能避免梯度消失。前面说到 RNN 梯度被表示为连成积,所以导致很快逼近 0。而 LSTM 使用累加的形式计算状态,所以导数也是累加的,就不会出现梯度消失了。
GRU
GRU(Gate Recurrent Unit)是 RNN 的一种。GRU 是 LSTM 的一个变体,在保持了 LSTM 的效果同时又使结构更加简单。GRU 更容易进行训练,能够很大程度上提高训练效率。
GRU模型中只有两个门:更新门、重置门。
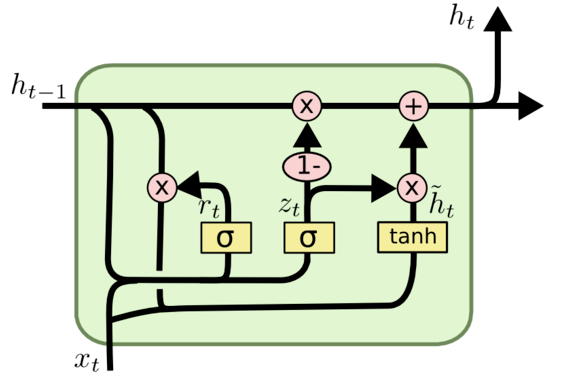
(1)更新门:用于控制过去信息与当前信息的比例。
[ht-1, xt] 乘参数 Wz,然后通过 sigmoid 确定 zt。
更新门得到的值 zt 可以同时进行遗忘和记忆。
![]()
(2)重置门:用于控制忽略前一时刻的状态信息的程度。
[ht-1, xt] 乘参数 Wr,然后通过 sigmoid 确定 rt。
![]()
(3)使用重置门控来得到“重置”之后的数据。
ht-1 乘 rt 得到重置的数据。重置后的数据与 xt 拼接,通过一个 tanh 将数据放缩到 -1~1 的范围内,得到 h~t。
![]()
(4)(1-zt) * ht-1 用来选择忽略之前的信息,zt * h~t 用来保留新的数据。
![]()
GRU 使用了一个门控 z 就同时可以进行遗忘和选择记忆,简化了计算。对于过去的信息,遗忘了 z 大小的部分,使用当前信息的相应大小来弥补。
训练时,参数 Wr、Wz、Wh。是拼接的,所以在训练的过程中需要将他们分割出来。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号