

机器学习知识点总结(1)
一、列举常用的最优化方法
梯度下降法
牛顿法,
拟牛顿法
坐标下降法
梯度下降法的改进型如AdaDelta,AdaGrad,Adam,NAG等。
2梯度下降法的关键点
梯度下降法沿着梯度的反方向进行搜索,利用了函数的一阶导数信息。梯度下降法的迭代公式为:

根据函数的一阶泰勒展开,在负梯度方向,函数值是下降的。只要学习率设置的足够小,并且没有到达梯度为0的点处,每次迭代时函数值一定会下降。需要设置学习率为一个非常小的正数的原因是要保证迭代之后的xk+1位于迭代之前的值xk的邻域内,从而可以忽略泰勒展开中的高次项,保证迭代时函数值下降。
梯度下降法只能保证找到梯度为0的点,不能保证找到极小值点。迭代终止的判定依据是梯度值充分接近于0,或者达到最大指定迭代次数。
梯度下降法在机器学习中应用广泛,尤其是在深度学习中。AdaDelta,AdaGrad,Adam,NAG等改进的梯度下降法都是用梯度构造更新项,区别在于更新项的构造方式不同。
3牛顿法的关键点
牛顿法利用了函数的一阶和二阶导数信息,直接寻找梯度为0的点。牛顿法的迭代公式为:
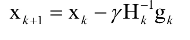
其中H为Hessian矩阵,g为梯度向量。牛顿法不能保证每次迭代时函数值下降,也不能保证收敛到极小值点。在实现时,也需要设置学习率,原因和梯度下降法相同,是为了能够忽略泰勒展开中的高阶项。学习率的设置通常采用直线搜索(line search)技术。
在实现时,一般不直接求Hessian矩阵的逆矩阵,而是求解下面的线性方程组:

其解d称为牛顿方向。迭代终止的判定依据是梯度值充分接近于0,或者达到最大指定迭代次数。
牛顿法比梯度下降法有更快的收敛速度,但每次迭代时需要计算Hessian矩阵,并求解一个线性方程组,运算量大。另外,如果Hessian矩阵不可逆,则这种方法失效。数学教材。机器学
4拉格朗日乘数法
拉格朗日乘数法是一个理论结果,用于求解带有等式约束的函数极值。对于如下问题:
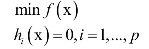
构造拉格朗日乘子函数:
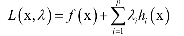
在最优点处对x和乘子变量的导数都必须为0:
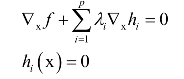

解这个方程即可得到最优解。对拉格朗日乘数法更详细的讲解可以阅读任何一本高等数学教材。机器学习中用到拉格朗日乘数法的地方有:
主成分分析
线性判别分析
流形学习中的拉普拉斯特征映射
隐马尔科夫模型
5凸优化
数值优化算法面临两个方面的问题:局部极值,鞍点。前者是梯度为0的点,也是极值点,但不是全局极小值;后者连局部极值都不是,在鞍点处Hessian矩阵不定,即既非正定,也非负定。
凸优化通过对目标函数,优化变量的可行域进行限定,可以保证不会遇到上面两个问题。凸优化是一类特殊的优化问题,它要求:
优化变量的可行域是一个凸集
目标函数是一个凸函数
凸优化最好的一个性质是:所有局部最优解一定是全局最优解。机器学习中典型的凸优化问题有:线性回归、岭回归、LASSO回归、Logistic回归、支持向量机、Softamx回归
6拉格朗日对偶
对偶是最优化方法里的一种方法,它将一个最优化问题转换成另外一个问题,二者是等价的。拉格朗日对偶是其中的典型例子。对于如下带等式约束和不等式约束的优化问题:
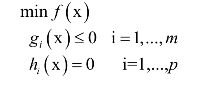
与拉格朗日乘数法类似,构造广义拉格朗日函数:
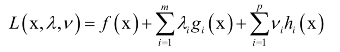
必须满足的约束。原问题为:
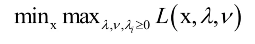
即先固定住x,调整拉格朗日乘子变量,让函数L取极大值;然后控制变量x,让目标函数取极小值。原问题与我们要优化的原始问题是等价的。
对偶问题为:
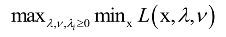
和原问题相反,这里是先控制变量x,让函数L取极小值;然后控制拉格朗日乘子变量,让函数取极大值。
一般情况下,原问题的最优解大于等于对偶问题的最优解,这称为弱对偶。在某些情况下,原问题的最优解和对偶问题的最优解相等,这称为强对偶。
强对偶成立的一种条件是Slater条件:一个凸优化问题如果存在一个候选x使得所有不等式约束都是严格满足的,即对于所有的i都有gi (x)<0,不等式不取等号,则强对偶成立,原问题与对偶问题等价。注意,Slater条件是强对偶成立的充分条件而非必要条件。
拉格朗日对偶在机器学习中的典型应用是支持向量机。
7
KKT条件
KKT条件是拉格朗日乘数法的推广,用于求解既带有等式约束,又带有不等式约束的函数极值。对于如下优化问题:
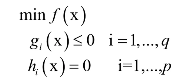
和拉格朗日对偶的做法类似,KKT条件构如下乘子函数:

和称为KKT乘子。在最优解处应该满足如下条件:
等式约束
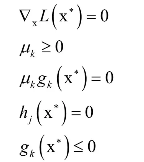
和不等式约束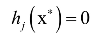
是本身应该满足的约束,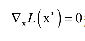 和之前的拉格朗日乘数法一样。唯一多了关于gi (x)的条件:
和之前的拉格朗日乘数法一样。唯一多了关于gi (x)的条件:
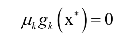
KKT条件只是取得极值的必要条件而不是充分条件。
8特征值与特征向量
对于一个n阶矩阵A,如果存在一个数和一个非0向量X,满足: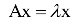
则称为矩阵A的特征值,X为该特征值对应的特征向量。根据上面的定义有下面线性方程组成立:
根据线性方程组的理论,要让齐次方程有非0解,系数矩阵的行列式必须为0,即: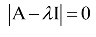
上式左边的多项式称为矩阵的特征多项式。矩阵的迹定义为主对角线元素之和: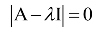
根据韦达定理,矩阵所有特征值的和为矩阵的迹: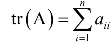
同样可以证明,矩阵所有特征值的积为矩阵的行列式: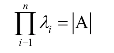
利用特征值和特征向量,可以将矩阵对角化,即用正交变换将矩阵化为对角阵。实对称矩阵一定可以对角化,半正定矩阵的特征值都大于等于0,在机器学习中,很多矩阵都满足这些条件。特征值和特征向量在机器学习中的应用包括:正态贝叶斯分类器、主成分分析,流形学习,线性判别分析,谱聚类等。
9奇异值的分解
矩阵对角化只适用于方阵,如果不是方阵也可以进行类似的分解,这就是奇异值分解,简称SVD。假设A是一个m x n的矩阵,则存在如下分解: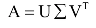
其中U为m x m的正交矩阵,其列称为矩阵A的左奇异向量;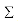 为m x n的对角矩阵,除了主对角线
为m x n的对角矩阵,除了主对角线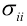
以外,其他元素都是0;V为n x n的正交矩阵,其行称为矩阵A的右奇异向量。U的列为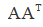 的特征向量,V的列为
的特征向量,V的列为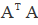 的特征向量。
的特征向量。
10最大似然估计
有些应用中已知样本服从的概率分布,但是要估计分布函数的参数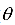 ,确定这些参数常用的一种方法是最大似然估计。
,确定这些参数常用的一种方法是最大似然估计。
最大似然估计构造一个似然函数,通过让似然函数最大化,求解出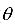 。最大似然估计的直观解释是,寻求一组参数,使得给定的样本集出现的概率最大。
。最大似然估计的直观解释是,寻求一组参数,使得给定的样本集出现的概率最大。
假设样本服从的概率密度函数为,其中X为随机变量,为要估计的参数。给定一组样本xi,i =1,...,l,它们都服从这种分布,并且相互独立。最大似然估计构造如下似然函数:

其中xi是已知量,这是一个关于的函数,我们要让该函数的值最大化,这样做的依据是这组样本发生了,因此应该最大化它们发生的概率,即似然函数。这就是求解如下最优化问题:
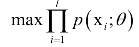
乘积求导不易处理,因此我们对该函数取对数,得到对数似然函数:
最后要求解的问题为:
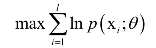
最大似然估计在机器学习中的典型应用包括logistic回归,贝叶斯分类器,隐马尔科夫模型等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号