Power BI Desktop
三大数据结构
1、Table 表类型
//输入 =#table 可查看用法如:
=#table({"Name ","Age"},{{"苏沐",18}})
or
=#table(type table [Name = text, Age= number], {{"苏沐",18}, {"张三", 23}})

获取Table 中的指定值
//取列(列表)
// = 表名[列名]
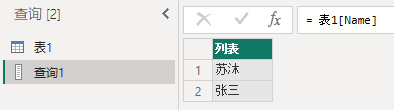
= 表1[Name]
//(拿第二条数据:= 表1[Name]{1} 输出为"张三")
//取行(记录)
// = 表名{下标} or = 表名{记录}
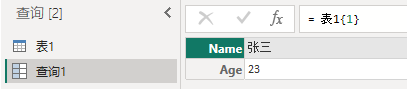
= 表1{1} or = 表1{[Name="张三"]}
2、Record 记录类型
//Record 就表示一行数据,需要通过[]来定义一条记录。记录的列名和值之间用 = 表示。
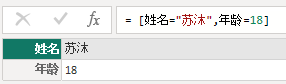
= [姓名= "苏沐",年龄= 18]
获取Record 中的指定值
//通过 [] 开获取指定字段的值。
= [姓名= "苏沐",年龄= 18][姓名]

3、List 列表类型
//List 代表一列数据,这里面的数据可以由不同的数据类型构成,在 M 语言里是通过 {} 来进行的创建。
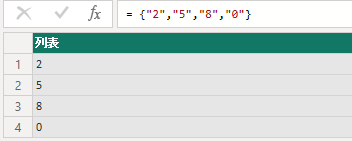
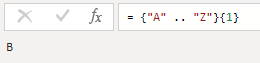
可通过 .. 来表示连续的元素 = {"A" .. "Z"}
//List 中的每一条记录也可以是 Record 类型。
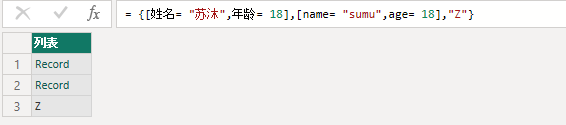
= {[姓名= "苏沐",年龄= 18],[name= "sumu",age= 18],"Z"}
获取List 中的指定值
//通过 {} 获取指定索引位置的值。
= {"A" .. "Z"}{1}
多个工作表的合并操作
方法一:进入到查询编辑器之后,选中一张表格,然后点击【主页】下方的【追加查询】,【将查询追加为新查询】。
方法二:Table.Combine({表1,表2,表3})
Table操作
//筛选
//这里的 【each】 表示每个记录都需要执行, each 后面的内容可以是值,也可以是 table , list 这些。
//语法:Table.SelectRows(table as table, condition as function) as table。第二个参数是筛选条件需要是函数类型。
= Table.SelectRows(表, each ([列名] = 值))
//删(互补)
//保留指定列
= Table.SelectColumns(表,{"列名1","列名2"})
//删除指定列
= Table.RemoveColumns(表,{"列名1","列名2"})
//展开
= Table.ExpandTableColumn(表, "待展开列", {"展开列1",..., "展开列n"}, {"新列名1",..., "新列名n"})
//排序
= Table.ReorderColumns(表,{"排序列1",..., "排序列n"})
//列数据类型转换
= Table.TransformColumnTypes(表,{{"列名1",Int64.Type},{"列名2",type text},{"列名3",type date}})
//将List 格式的数据转化为表
//第一个参数是要进行转化的 List;
//第二个参数 splitter 表示拆分方法;Splitter.SplitTextByDelimiter("-") 等同于 each Text.Split(_,"-") 按照 - 来拆分数据
//第三个参数 columns 是用来配置拆分后的表格列的信息。{"a","b"} 拆分后的 2 列设置为 a 和 b
//第四个参数 default 就是用来处理如果遇到空值时,应该怎么处理。默认值
//第五个参数 指的是当实际拆分结果,比我们指定的拆分列数更多的时候要如何处理这些多余的值。
//ExtraValues.Ignore 把多余的内容忽略;ExtraValues.List 把剩余的部分改为用 List 存储。
= Table.FromList(List, Splitter.SplitByNothing(), null, null, ExtraValues.Error)
//合并查询
//JoinKind.Inner(取相同值);JoinKind.LeftAnti(左反 取左表不同数值);JoinKind.RightAnti(右反 取右表不同数值);
//JoinKind.LeftOuter(左外联接,保留第一个表的所有数据和第二个表中的匹配数据)
//JoinKind.RightOuter(右外联接,保留第二个表中的所有数据和第一个表中的匹配数据)
//JoinKind.FullOuter(完全外部联接,保留两个表的所有数据)
= Table.NestedJoin(表1, {"表1Column1"}, 表2, {"表2Column1"}, "存储到新的一列名", JoinKind.LeftAnti)
//逆透视
1、指定列外的其他列变成键值对格式:
= Table.UnpivotOtherColumns(表,{"列名1","列名2","列名3"},"列名Key","列名Value")
2、指定列转化为键值对的形式:
= Table.Unpivot(表,{"列名1","列名2","列名3"},"列名Key","列名Value")
//分组(指定关键字对表进行分组,并对列值进行聚合运算)
//求和
= Table.Group(表, {"列名1","列名2"}, {{"自定义列名(总数)", each List.Sum([列名3]), type nullable number}})
//列分割
//第四个参数如果直接输入数字的话就会保留相应列的数量,否则按List显示
= Table.SplitColumn(表, "Column1", Splitter.SplitTextByDelimiter(";", QuoteStyle.None), {"Column1.1", "Column1.2"},"默认值")
如果源带 ""等特殊字符 如:展开的“Data” 需用 #"展开的“Data”" 代替
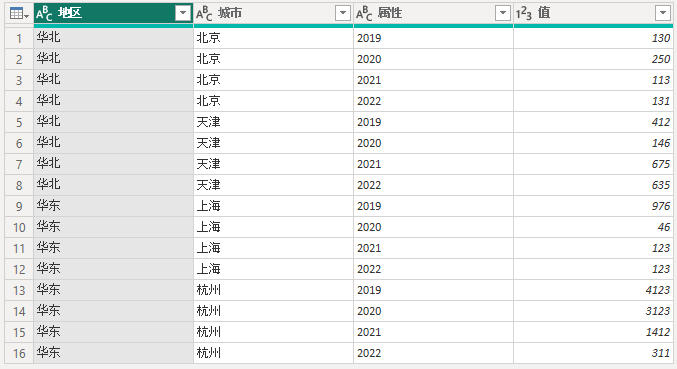
二维表转化为一维表

//1、转置表(行和列互相转换)
= Table.Transpose(表)
//2、向下填充(自动将单元格中的空值填充为上面有内容的值)
= Table.FillDown(转置表,{"Column1"})
//3、将第一行用作标题
= Table.PromoteHeaders(向下填充)
//4、将指定的列重命名为其他名称
= Table.RenameColumns(更改的类型1,{{"年度", "地区"}, {"Column2", "城市"}})
//5、逆透视(进行键值对转换)
= Table.UnpivotOtherColumns(重命名的列, {"地区", "城市"}, "属性", "值")
条件判断划分等级
= Table.AddColumn(表, "新列名", each if [列] >= 4000 then "优" else if [列] >= 3000 then "良" else "差")
DAX 函数
1、聚合函数(返回一个值)
SUM, MAX, MIN ,AVERAGE(求和,计算最大值,最小值,平均数)
2、日期和时间函数(对日期和时间进行计算)
YEAR, MONTH ,DAY
3、逻辑函数(条件运算)
IF , AND, OR, SWITCH
4、信息函数(判断某个值的具体类型)
ISBLANK , ISNUMBER , ISTEXT
5、文本函数(主要用于文本的运算)
FIND , SEARCH, REPLACE(查找、搜索、替换)
6、筛选器函数
CALCULATE
7、关系函数(主要作用是管理和使用数据模型中的关系)
RELATED
8、表操作函数(返回表或者操作表)
FILTER , SELECTCOLUMNS
9、日期智能函数(生成和比较时间段的计算)
DATEADD , DATESMTED
10、其他函数
财务函数,统计函数,数学和三角函数
//SUMX 和 FILTER 公式的配合
//第一个参数是要进行筛选的表,第二个参数是筛选的条件。
度量值 = SUMX(FILTER('表','表'[字段] = 值),'表'[字段])
//CALCULATE 和 SUM 公式的配合
//第一个参数是用来计算的表达式,第二个参数筛选条件。
度量值 = CALCULATE(SUM('表'[字段]),'表'[字段] = 值)
//ALL 函数配合切片器来给可视化效果进行筛选(没用ALL函数会发生筛选)
//返回的表中只带有这些列(ALLEXCEPT 则相反)
表1 = ALL(表[字段1],表[字段2],...)
//DIVIDE 函数(安全除法)
度量值 = DIVIDE(表[字段1],表[字段2])
本文来自博客园,作者:苏沐~,转载请注明原文链接:https://www.cnblogs.com/sumu80/p/18232875

 浙公网安备 33010602011771号
浙公网安备 33010602011771号