【Java并发编程】线程池相关知识点整理——新增
几种Executors创建的常见线程池总结
FixedThreadPool
可重用固定线程池数的线程池,任务队列使用的是无界的LinkedBlockingQueue。
FixedThreadPool运行示意图【图片来源《Java并发编程的艺术》】
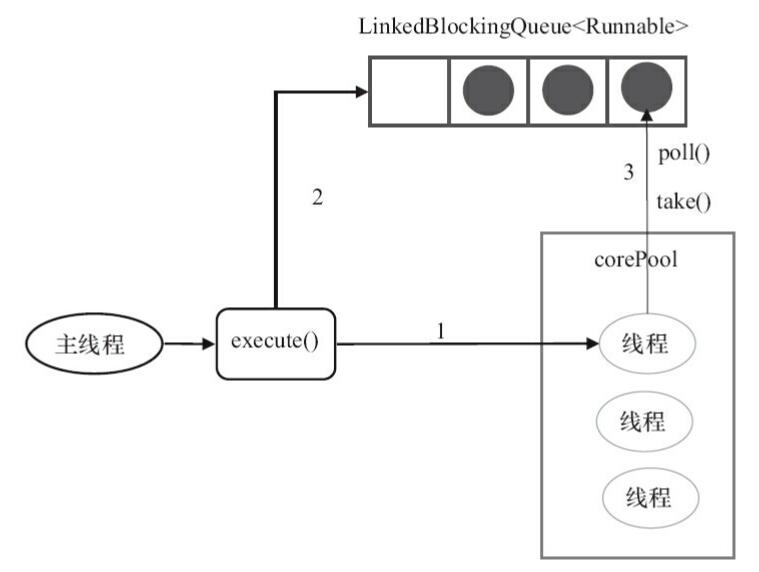
- 如果当前运行的线程数小于 corePoolSize, 如果再来新任务的话,就创建新的线程来执行任务;
- 当前运行的线程数等于 corePoolSize 后, 如果再来新任务的话,会将任务加入
LinkedBlockingQueue; - 线程池中的线程执行完 手头的任务后,会在循环中反复从
LinkedBlockingQueue中获取任务来执行;
不推荐使用FixedThreadPool的原因
SingleThreadExecutor
SingleThreadExecutor是只有一个线程的线程池。
SingleThreadExecutor运行示意图【图片来源《Java并发编程的艺术》】
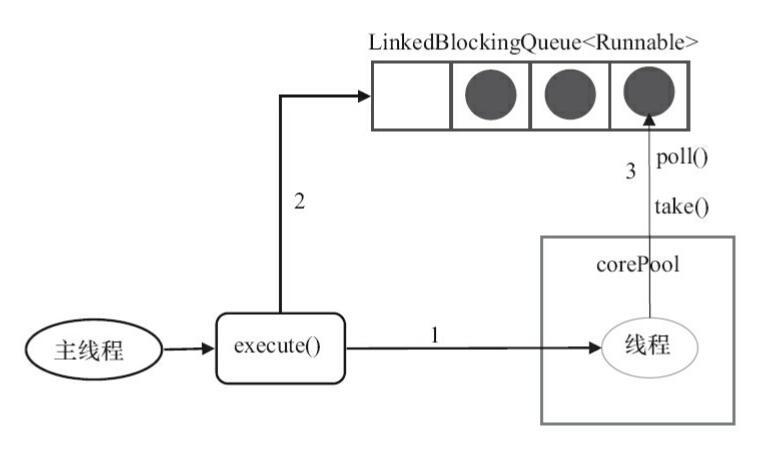
- 如果当前运行的线程数少于 corePoolSize,则创建一个新的线程执行任务;
- 当前线程池中有一个运行的线程后,将任务加入
LinkedBlockingQueue; - 线程执行完当前的任务后,会在循环中反复从
LinkedBlockingQueue中获取任务来执行;
不推荐使用SingleThreadPool的原因
同FixedThreadPool,任务很多时,可能会引发OOM。
CacheThreadPool
CachedThreadPool 是一个会根据需要创建新线程的线程池,使用的任务队列是:SynchronousQueue。
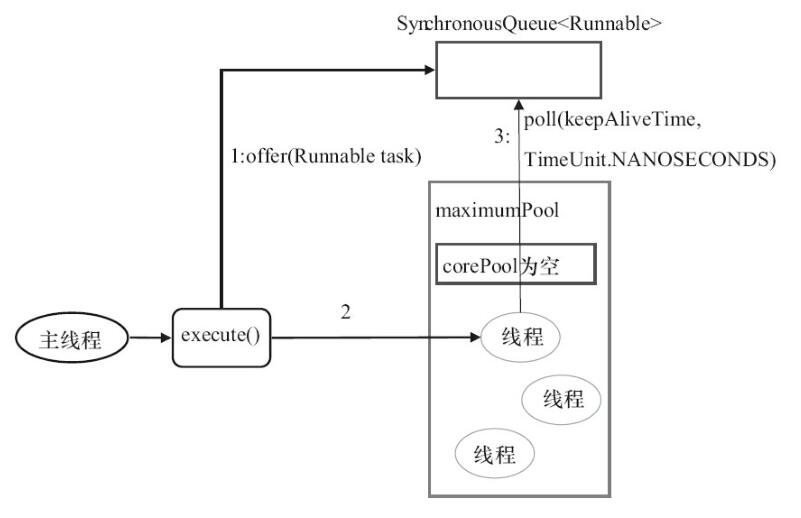
- 首先执行
SynchronousQueue.offer(Runnable task)提交任务到任务队列。如果当前maximumPool中有线程正在执行SynchronousQueue.poll(keepAliveTime,TimeUnit.NANOSECONDS),那么主线程执行 offer 操作与空闲线程执行的poll操作配对成功,主线程把任务交给空闲线程执行,execute()方法执行完成,否则执行下面的步骤 2; - 当初始
maximumPool为空,或者maximumPool中没有空闲线程时,将没有线程执行SynchronousQueue.poll(keepAliveTime,TimeUnit.NANOSECONDS)。这种情况下,步骤 1 将失败,此时CachedThreadPool会创建新线程执行任务,execute 方法执行完成;
不推荐使用CachedThreadPool的原因
CachedThreadPool允许创建的线程数量为 Integer.MAX_VALUE ,可能会创建大量线程,从而导致 OOM。
ScheduledThreadPoolExecutor
使用的是DelayedWorkQueue,ScheduledThreadPoolExecutor会把待调度的任务 (ScheduledFutureTask)放到一个DelayQueue中。
DelayQueue封装了一个PriorityQueue,这个PriorityQueue会对队列中的Scheduled-FutureTask进行排序。排序时,time小的排在前面(时间早的任务将被先执行)。如果两个ScheduledFutureTask的time相同,就比较sequenceNumber,sequenceNumber小的排在前面(也就是说,如果两个任务的执行时间相同,那么先提交的任务将被先执行)。
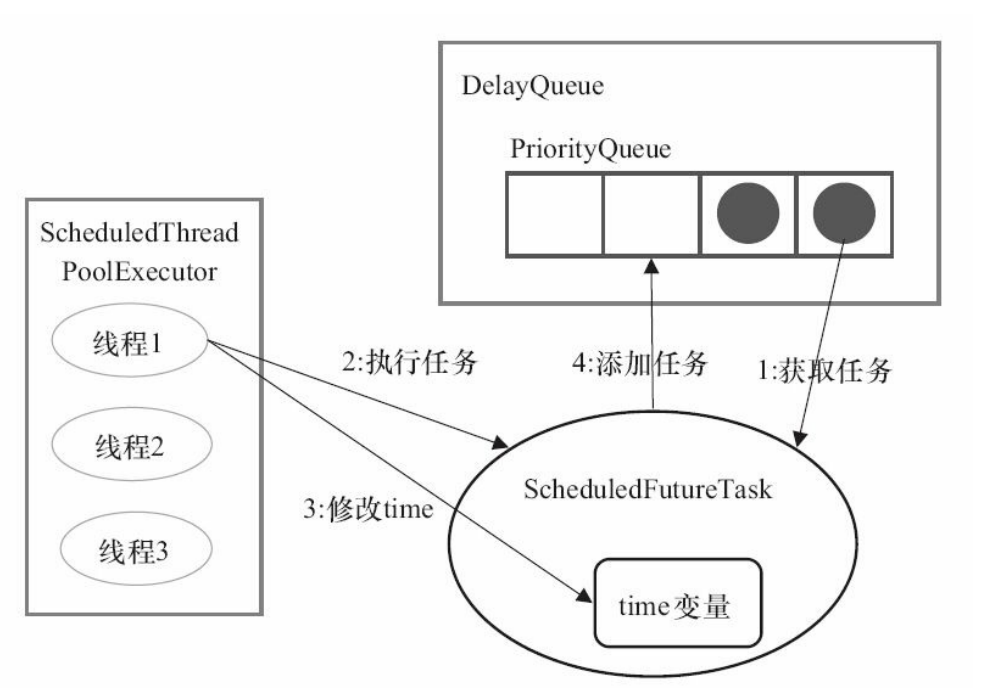
- 线程1从DelayQueue中获取已到期的ScheduledFutureTask(DelayQueue.take())。 到期任务是指ScheduledFutureTask的time大于等于当前时间。
- 线程1执行这个ScheduledFutureTask。
- 线程1修改ScheduledFutureTask的time变量为下次将要被执行的时间。
- 线程1把这个修改time之后的ScheduledFutureTask放回DelayQueue中(DelayQueue.add())。
WorkStealingPool
创建一个含有足够多线程的线程池,能够调用闲置的CPU去处理其他的任务,使用ForkJoinPool实现,jdk8新增。
LinkedBlockingQueue与ArrayBlockingQueue
线程池的阻塞队列为什么都用LinkedBlockingQueue,而不用ArrayBlockingQueue
LinkedBlockingQueue 使用单向链表实现,在声明的时候,可以不指定队列长度,长度为Integer.MAX_VALUE, 并且新建了一个Node对象,Node对象具有item,next变量,item用于存储元素,next指向链表下一个Node对象,在刚开始的时候链表的head,last都指向该Node对象,item、next都为null,新元素放在链表的尾部,并从头部取元素。取元素的时候只是一些指针的变化,LinkedBlockingQueue给put(放入元素),take(取元素)都声明了一把锁,放入和取互不影响,效率更高。
ArrayBlockingQueue 使用数组实现,在声明的时候必须指定长度,如果长度太大,造成内存浪费,长度太小,并发性能不高,如果数组满了,就无法放入元素,除非有其他线程取出元素,放入和取出都使用同一把锁,因此存在竞争,效率比LinkedBlockingQueue低
线程池不使用的时候,需要关闭吗?
- 线程池的作用确实是为了减少频繁创建线程,以达到线程复用的目的。
- 但是如果不使用线程池的时候,线程池中的核心线程依然会一直存在,导致资源浪费,因此,在不使用线程池的时候可以通过shutdown方法关闭线程池。
如何合理配置Java线程池
线程数量太小,可能导致大量任务在队列中排队等待执行,最终OOM,CPU无法得到充分利用。
线程数量太大,大量线程可能会同时争取CPU的资源,导致大量的上下文切换。
计算公式
- CPU 密集型任务(N+1): 这种任务消耗的主要是 CPU 资源,可以将线程数设置为 N(CPU 核心数)+1,比 CPU 核心数多出来的一个线程是为了防止线程偶发的缺页中断,或者其它原因导致的任务暂停而带来的影响。一旦任务暂停,CPU 就会处于空闲状态,而在这种情况下多出来的一个线程就可以充分利用 CPU 的空闲时间。
- I/O 密集型任务(2N): 这种任务应用起来,系统会用大部分的时间来处理 I/O 交互,而线程在处理 I/O 的时间段内不会占用 CPU 来处理,这时就可以将 CPU 交出给其它线程使用。因此在 I/O 密集型任务的应用中,我们可以多配置一些线程,具体的计算方法是 2N。
如何判断是 CPU 密集任务还是 IO 密集任务?
CPU 密集型简单理解就是利用 CPU 计算能力的任务比如你在内存中对大量数据进行排序。但凡涉及到网络读取,文件读取这类都是 IO 密集型,这类任务的特点是 CPU 计算耗费时间相比于等待 IO 操作完成的时间来说很少,大部分时间都花在了等待 IO 操作完成上。
参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号