mybatis源码学习:一级缓存和二级缓存分析
前文传送门:mybatis源码学习:从SqlSessionFactory到代理对象的生成
零、一级缓存和二级缓存的流程
以这里的查询语句为例。
一级缓存总结
-
以下两种情况会直接在一级缓存中查找数据
- 主配置文件或映射文件没有配置二级缓存开启。
- 二级缓存中不存在数据。
-
根据statetment,生成一个CacheKey。
-
判断是否需要清空本地缓存。
-
根据cachekey从localCache中获取数据。
-
如果缓存未命中,走接下来三步并向下
- 从数据库查询结果。
- 将cachekey:数据存入localcache中。
- 将数据返回。
-
如果缓存命中,直接从缓存中获取数据。
-
localCache的范围如果为statement,清空一级缓存。
二级缓存总结
-
判断主配置文件是否设置了enabledCache,默认是开启的,创建CachingExecutor。
-
根据statetment,生成一个CacheKey。
-
判断映射文件中是否有cache标签,如果没有则跳过以下针对二级缓存的操作,从一级缓存中查,查不到就从数据库中查。
-
否则即开启了二级缓存,获取cache。
-
判断是否需要清空二级缓存。
-
判断该语句是否需要使用二级缓存isUserCache。
-
如果二级缓存命中,则直接返回该数据。
-
如果二级缓存未命中,则将cachekey存入未命中set,然后进行一下的操作:
- 从一级缓存中查,如果命中就返回,没有命中就从数据库中查。
- 将查到的数据返回,并将cachekey和数据(对象的拷贝)存入待加入二级缓存的map中。
-
最后commit和close操作都会使二级缓存真正地更新。
一、缓存接口Cache及其实现类
缓存类的顶级接口Cache,里面定义了加入数据到缓存,从缓存中获取数据,清楚缓存等操作,通常mybatis会将namespace作为id,将CacheKey作为Map中的键,而map中的值也就是存储在缓存中的对象。
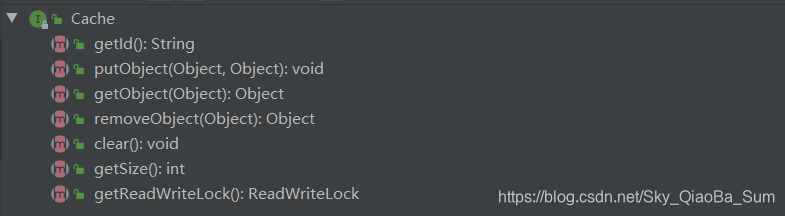
而通过装饰器设计模式,将Cache的功能进行加强,在它的实现类中有着明显的体现:
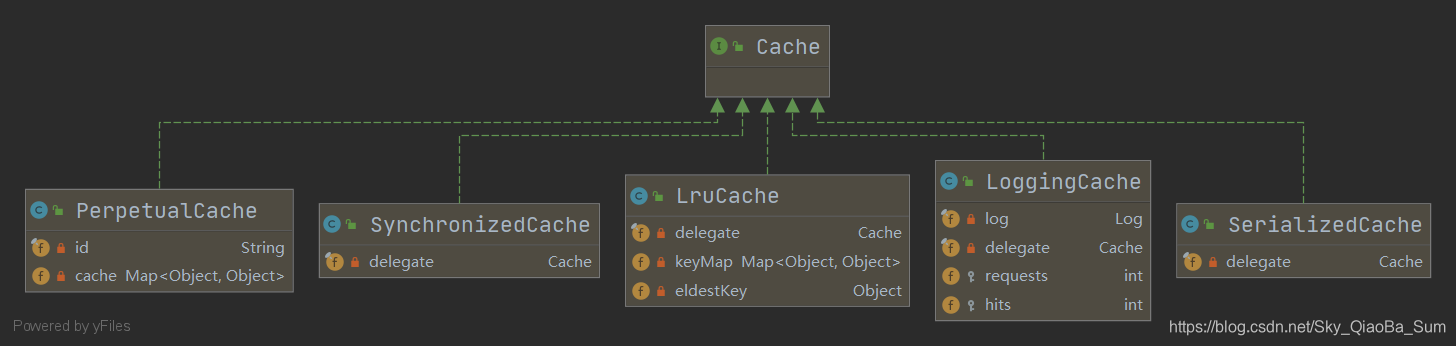
PerpetualCache:是最基础的缓存类,采用HashMap实现,同时一级缓存使用的localCache就是该类型。
LruCache:Lru(least recently used),采用Lru算法可以实现移除最长时间没有使用的key/value。
SerializedCache:提供了序列化功能,将值序列化后存入缓存,用于缓存返回一份实例的Copy,保证线程安全。
LoggingCache:提供日志功能,如果开启debugEnabled为true,则打印缓存命中日志。
SynchronizedCache:同步的Cache,用synchronized关键字修饰所有方法。
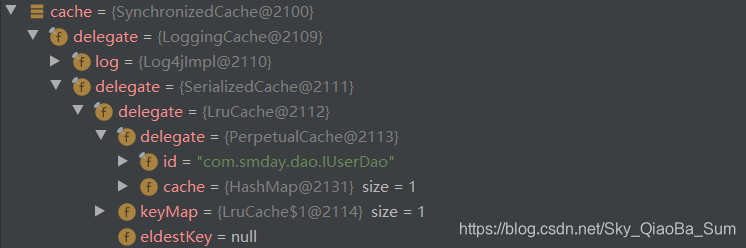
下图可以得知其执行链:SynchronizedCache -> LoggingCache -> SerializedCache -> LruCache -> PerpetualCache
二、cache标签解析源码
XMLMapperBuilder中的configurationElement负责解析mappers映射文件中的标签元素,其中有个cacheElement方法,负责解析cache标签。
private void cacheElement(XNode context) throws Exception {
if (context != null) {
//获取type属性,默认为perpetual
String type = context.getStringAttribute("type", "PERPETUAL");
//获取type类对象
Class<? extends Cache> typeClass = typeAliasRegistry.resolveAlias(type);
//获取eviction策略,默认为lru,即最近最少使用,移除最长时间不被使用的对象
String eviction = context.getStringAttribute("eviction", "LRU");
Class<? extends Cache> evictionClass = typeAliasRegistry.resolveAlias(eviction);
//获取flushInterval刷新间隔
Long flushInterval = context.getLongAttribute("flushInterval");
//获取size引用数目
Integer size = context.getIntAttribute("size");
//获取是否只读
boolean readWrite = !context.getBooleanAttribute("readOnly", false);
//获取是否blocking
boolean blocking = context.getBooleanAttribute("blocking", false);
//这一步是另外一种设置cache的方式,即cache子元素中用property,name,value定义
Properties props = context.getChildrenAsProperties();
builderAssistant.useNewCache(typeClass, evictionClass, flushInterval, size, readWrite, blocking, props);
}
}
getStringAttribute方法,这个方法的作用就是获取指定的属性值,如果没有设置的话,就采用默认的值:
public String getStringAttribute(String name, String def) {
//获取name参数对应的属性
String value = attributes.getProperty(name);
if (value == null) {
//如果没有设置,默认为def
return def;
} else {
return value;
}
}
resolveAlias方法,从源码中我们就可以猜测,我们之前通过</typeAliases>起别名其实也就是将里面的内容解析,并存入map之中,而每次处理类型的时候,都比较的是小写的形式,这也是我们起别名之后不用关心大小写的原因。
// throws class cast exception as well if types cannot be assigned
public <T> Class<T> resolveAlias(String string) {
try {
if (string == null) {
return null;
}
//首先将传入的参数转换为小写形式
String key = string.toLowerCase(Locale.ENGLISH);
Class<T> value;
//到TypeAliasRegistry维护的Map,TYPE_ALIASES中找有无对应的键
if (TYPE_ALIASES.containsKey(key)) {
//找到就直接返回:class类对象
value = (Class<T>) TYPE_ALIASES.get(key);
} else {
//找不到就通过反射获取一个
value = (Class<T>) Resources.classForName(string);
}
return value;
} catch (ClassNotFoundException e) {
throw new TypeException("Could not resolve type alias '" + string + "'. Cause: " + e, e);
}
}
根据获取的属性,通过装饰器模式,层层装饰,最后创建了一个SynchronizedCache,并添加到configuration中。因此我们可以知道,一旦我们在映射文件中设置了<cache>,就会创建一个SynchronizedCache缓存对象。
public Cache useNewCache(Class<? extends Cache> typeClass,
Class<? extends Cache> evictionClass,
Long flushInterval,
Integer size,
boolean readWrite,
boolean blocking,
Properties props) {
//把当前的namespace当作缓存的id
Cache cache = new CacheBuilder(currentNamespace)
.implementation(valueOrDefault(typeClass, PerpetualCache.class))
.addDecorator(valueOrDefault(evictionClass, LruCache.class))
.clearInterval(flushInterval)
.size(size)
.readWrite(readWrite)
.blocking(blocking)
.properties(props)
.build();
//将cache加入configuration
configuration.addCache(cache);
currentCache = cache;
return cache;
}
三、CacheKey缓存项的key
默认情况下,enabledCache的全局设置是开启的,所以Executor会创建一个CachingExecutor,以查询为例,当执行Executor实现类的时候,会获取boundsql,并根据当前信息创建缓存项的key。
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
//从MappedStatement中获取boundsql
BoundSql boundSql = ms.getBoundSql(parameterObject);
//Cachekey类表示缓存项的key
CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
每一个SqlSession中持有了自己的Executor,每一个Executor中有一个Local Cache。当用户发起查询时,Mybatis会根据当前执行的MappedStatement生成一个key,去Local Cache中查询,如果缓存命中的话,返回。如果缓存没有命中的话,则写入Local Cache,最后返回结果给用户。
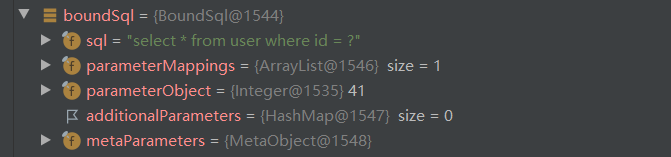
boundsql对象的详细信息:
CacheKey对象的CreateKey操作:
- 首先创建一个cachekey,默认hashcode=17,multiplier=37,count=0,updateList初始化。
- update操作:count++,对checksum,hashcode进行赋值,最后将参数添加到updatelist中。
//根据传入信息,创建chachekey
@Override
public CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) {
//执行器关闭就抛出异常
if (closed) {
throw new ExecutorException("Executor was closed.");
}
//创建一个cachekey,默认hashcode=17,multiplier=37,count=0,updateList初始化
CacheKey cacheKey = new CacheKey();
//添加操作:sql的id,逻辑分页偏移量,逻辑分页起始量,sql语句。
cacheKey.update(ms.getId());
cacheKey.update(rowBounds.getOffset());
cacheKey.update(rowBounds.getLimit());
cacheKey.update(boundSql.getSql());
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
TypeHandlerRegistry typeHandlerRegistry = ms.getConfiguration().getTypeHandlerRegistry();
// mimic DefaultParameterHandler logic
for (ParameterMapping parameterMapping : parameterMappings) {
if (parameterMapping.getMode() != ParameterMode.OUT) {
Object value;
//参数名
String propertyName = parameterMapping.getProperty();
//根据参数名获取值
if (boundSql.hasAdditionalParameter(propertyName)) {
value = boundSql.getAdditionalParameter(propertyName);
} else if (parameterObject == null) {
value = null;
} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
value = parameterObject;
} else {
MetaObject metaObject = configuration.newMetaObject(parameterObject);
value = metaObject.getValue(propertyName);
}
//添加参数值
cacheKey.update(value);
}
}
//添加environment的id名,如果它不为空的话
if (configuration.getEnvironment() != null) {
// issue #176
cacheKey.update(configuration.getEnvironment().getId());
}
//返回cachekey
return cacheKey;
}
所以缓存项的key最后表示为:hashcode:checknum:遍历updateList,以:间隔。
2020122321:657338105:com.smday.dao.IUserDao.findById:0:2147483647:select * from user where id = ?:41:mysql。
接着,调用同类中的query方法,针对是否开启二级缓存做不同的决断。(需要注意的是,这一部分是建立在cacheEnabled设置为true的前提下,当然默认是true。如果为false,Executor将会创建BaseExecutor,并不会判断mappers映射文件中二级缓存是否存在,而是直接执行delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql))
//主配置文件已经开启二级缓存
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
Cache cache = ms.getCache();
//映射文件配置已经开启二级缓存
if (cache != null) {
//如果cache不为空,且需要清缓存的话(insert|update|delete),执行tcm.clear(cache);
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, parameterObject, boundSql);
@SuppressWarnings("unchecked")
//从缓存中获取
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
//缓存中没有就执行查询,BaseExecutor的query
list = delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
//存入缓存
tcm.putObject(cache, key, list); // issue #578 and #116
}
//如果缓存中有,就直接返回
return list;
}
}
//映射文件没有开启二级缓存,需要进行查询,delegate其实还是Executor对象
return delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
除了select操作之外,其他的的操作都会清空二级缓存。XMLStatementBuilder中配置属性的时候:
boolean flushCache = context.getBooleanAttribute("flushCache", !isSelect);
private void flushCacheIfRequired(MappedStatement ms) {
Cache cache = ms.getCache();
if (cache != null && ms.isFlushCacheRequired()) {
//tcm后面会总结,清空二级缓存
tcm.clear(cache);
}
}
四、二级缓存TransactionCache
这里学习一下二级缓存涉及的缓存类:TransactionCache,同样也是基于装饰者设计模式,对传入的Cache进行装饰,构建二级缓存事务缓冲区:

CachingExecutor维护了一个TransactionCacheManager,即tcm,而这个tcm其实维护的就是一个key为Cache,value为TransactionCache包装过的Cache。而tcm.getObject(cache, key)的意思我们可以通过以下源码得知:
public Object getObject(Cache cache, CacheKey key) {
//将传入的cache包装为TransactionalCache,并根据key获取值
return getTransactionalCache(cache).getObject(key);
}
需要注意的是,getObject方法中将会把获取值的职责一路向后传递,直到最基础的perpetualCache,根据cachekey获取。

最终获取到的值,如果为null,就需要把key加入未命中条目的缓存。
@Override
public Object getObject(Object key) {
//根据职责一路向后传递
Object object = delegate.getObject(key);
if (object == null) {
//没找到值就将key存入未命中的set
entriesMissedInCache.add(key);
}
// issue #146
if (clearOnCommit) {
return null;
} else {
return object;
}
}
如果缓存中没有找到,将会从数据库中查找,查询到之后,将会进行添加操作,也就是:tcm.putObject(cache, key, list);。我们可以发现,其实它并没有直接将数据加入缓存,而是将数据添加进待提交的map中。
@Override
public void putObject(Object key, Object object) {
entriesToAddOnCommit.put(key, object);
}
也就是说,一定需要某种手段才能让他真正地存入缓存,没错了,commit是可以的:
//CachingExecutor.java
@Override
public void commit(boolean required) throws SQLException {
//清除本地缓存
delegate.commit(required);
//调用tcm.commit
tcm.commit();
}
最终调用的是TransactionCache的commit方法:
public void commit() {
if (clearOnCommit) {
delegate.clear();
}
flushPendingEntries();
reset();
}
最后的最后,我们可以看到将刚才的未命中和待提交的数据都进行了相应的处理,这才是最终影响二级缓存中数据的操作,当然这中间也存在着职责链,就不赘述了。

当然,除了commit,close也是一样的,因为最终调用的其实都是commit方法,同样也会操作缓存。
五、二级缓存测试
<!-- 开启全局配置 -->
<settings>
<!--全局开启缓存配置,是默认开启的-->
<setting name="cacheEnabled" value="true"/>
</settings>
<!-- 映射配置文件 -->
<!--开启user支持二级缓存-->
<cache></cache>
<select id="findById" resultType="user" useCache="true" >
select * from user where id = #{id}
</select>
/**
* 测试二级缓存
*/
@Test
public void testFirstLevelCache2(){
SqlSession sqlSession1 = factory.openSession();
IUserDao userDao1 = sqlSession1.getMapper(IUserDao.class);
User user1 = userDao1.findById(41);
System.out.printf("==> %s\n", user1);
sqlSession1.commit();
//sqlSession1.close();
SqlSession sqlSession2 = factory.openSession();
IUserDao userDao2 = sqlSession2.getMapper(IUserDao.class);
User user2 = userDao2.findById(41);
System.out.printf("==> %s\n", user2);
sqlSession2.close();
System.out.println("user1 == user2:"+(user1 == user2));
SqlSession sqlSession3 = factory.openSession();
IUserDao userDao3 = sqlSession3.getMapper(IUserDao.class);
User user3 = userDao3.findById(41);
System.out.printf("==> %s\n", user3);
sqlSession2.close();
System.out.println("user2 == user3:"+(user2 == user3));
}

二级缓存实现了SqlSession之间缓存数据的共享,是mapper映射级别的缓存。
有时缓存也会带来数据读取正确性的问题,如果数据更新频繁,会导致从缓存中读取到的数据并不是最新的,可以关闭二级缓存。
六、一级缓存源码解析
主配置文件或映射文件没有配置二级缓存开启,或者二级缓存中不存在数据,最终都会执行BaseExecutor的query方法,如果queryStack为空或者不是select语句,就会先清空本地的缓存。
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
查看本地缓存(一级缓存)是否有数据,如果有直接返回,如果没有,则调用queryFromDatabase从数据库中查询。
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
//处理存储过程
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
//从数据库中查询
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
判断本地缓存的级别是否为STATEMENT级别,如果是的话,清空缓存,因此STATEMENT级别的一级缓存无法共享localCache。
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
七、测试一级缓存
/**
* 测试一级缓存
*/
@Test
public void testFirstLevelCache1(){
SqlSession sqlSession1 = factory.openSession();
IUserDao userDao1 = sqlSession1.getMapper(IUserDao.class);
User user1 = userDao1.findById(41);
System.out.printf("==> %s\n", user1);
IUserDao userDao2 = sqlSession1.getMapper(IUserDao.class);
User user2 = userDao2.findById(41);
System.out.printf("==> %s\n", user2);
sqlSession1.close();
System.out.println("user1 == user2:"+(user1 == user2));
}

一级缓存默认是sqlSession级别地缓存,insert|delete|update|commit()和close()的操作的执行都会清空一级缓存。
怎么说呢,分析源码的过程让我对Mybatis有了更加深刻的认识,可能有些理解还是没有很到位,或许是经验不足,很多东西还是浮于表面,但一翻debug下来,看到自己之前一个又一个的迷惑被非常确切地解开,真的爽!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号