文件取证之编码转换
进制转换
二进制\b:0,1
八进制\o:0-7
十进制\d:0-9
十六进制\x:0-F
python进制转换
int("FF", 16) ##十六进制转为十进制
int("77", 8) ##八进制转为十进制
int("11", 2) ##二进制转为十进制
hex(10) ##十进制转为十六进制
oct(10) ##十进制转为八进制
bin(10) ##十进制转为二进制
十六进制转为二进制:先把十六进制转为十进制,在把十进制转为二进制。
以此类推。
BUUCTF:另外一个世界
得到一个monster.jpg文件
十六进制编辑器HxD打开发现尾部存在一串二进制数据
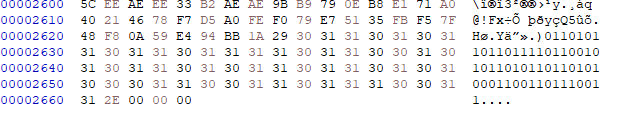
把二进制数据转为字符串
a = "01101011011011110110010101101011011010100011001101110011"
ls = [chr(int(a[i:i+8], 2)) for i in range(0, len(a), 8)] ##把二进制转为十进制,八位一个字节;再根据ASCII码转为字符
"".join(ls)
攻防世界:掀桌子
菜狗截获了一份报文如下c8e9aca0c6f2e5f3e8c4efe7a1a0d4e8e5a0e6ece1e7a0e9f3baa0e8eafae3f9e4eafae2eae4e3eaebfaebe3f5e7e9f3e4e3e8eaf9eaf3e2e4e6f2,生气地掀翻了桌子(╯°□°)╯︵ ┻━┻
把十六进制数据转为字符串
a = 'c8e9aca0c6f2e5f3e8c4efe7a1a0d4e8e5a0e6ece1e7a0e9f3baa0e8eafae3f9e4eafae2eae4e3eaebfaebe3f5e7e9f3e4e3e8eaf9eaf3e2e4e6f2'
ls = [chr(int(a[i:i+2], 16)-128) for i in range(0, len(a), 2)]
"".join(ls)
unicode编码
unicode字符集是全球文字统一编码,为世界上各种文字的每一个字符指定唯一数字。
unicode字符集映射的数字范围:U+0000 到 U+10FFFF
UTF-8 UTF-16 UTF-32是Unicode的具体实现(怎么存储在计算机)。
UTF-8,变长的编码设计。一个字符最多4个字节,最少1个字节。大部分中文字符占3个字节
一个字节表示的字符的取值(二进制) 0xxxxxxx (0-127,完全兼容ASCII)
两个字节表示的字符的取值(二进制) 110xxxxx 10xxxxxx
三个字节表示的字符的取值(二进制) 1110xxxx 10xxxxxx 10xxxxxx
四个字节表示的字符的取值(二进制) 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
比如一个表情的unicode编码为U+1F62D,使用四个字节表示,因此将1F62D所表示的二进制数11111011000101101从低位到高位依次把二进制数填入‘x’中,剩余的‘x’为0
UTF-32,固定长度的编码,每个字符长度为4个字节
字符的取值范围为 00000000 - FFFFFFFF
UTF-16
unicode字符集中,000000-00FFFF表示的字符,UTF-16编码长度为2字节
unicode字符集中,010000-10FFFF表示的字符,UTF-16编码长度为4字节
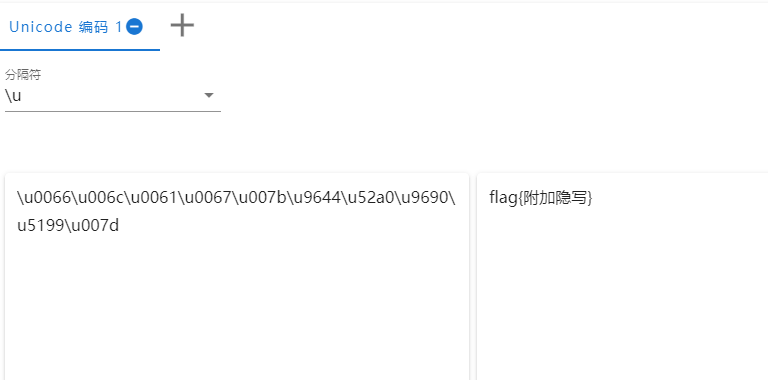
例如:“0066006c00610067007b964452a096905199007d"
写python脚本,四个字节为一个unicode编码单位
a = '0066006c00610067007b964452a096905199007d' s = '' for i in range(0, len(a), 4): s += ('\\u' + a[i:i+4]) print(s)
执行,得到unicode字符集:\u0066\u006c\u0061\u0067\u007b\u9644\u52a0\u9690\u5199\u007d
使用CaptfEncoder进行unicode解码
Base64编码
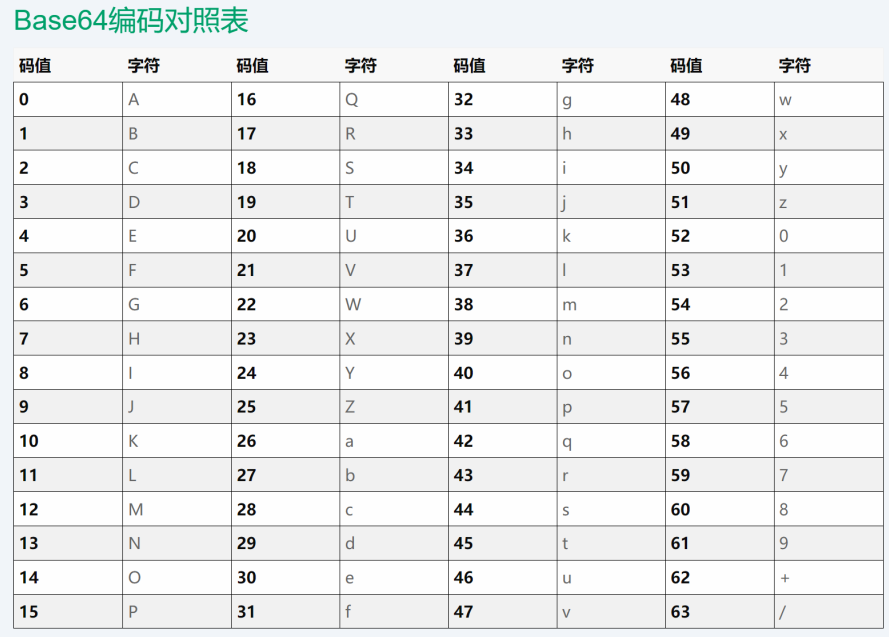
经过base64编码后的字符串包含A-Za-z0-9+/共64个字符,还有=填充字符。
base64编码过程中,如果一个字符串的二进制位数不是6(26=64)的整数倍,则需要在二进制值后添加0,使之变成6的整数倍。每6个二进制数据对应的ascii字符,就是base64编码后的字符。base64编码后每个字符占6位。
如图所示,“Tr0”的二进制位数3×8=24,可以分为6×4,编码后字符数变成了4个。

Base64编码后的字符数一般是4的倍数,如果不足4的倍数,就用等号“=”来补齐
brainfuck
一种简单的、可以用最小的编译器来实现的、符合图灵完全思想的编程语言。
由八种运算符构成,分别是<>+-.,[]

jsfuck
使用六个字符来混淆JavaScript代码的编码,六个字符分别是 []()!+

Escape编码
数字、字母及一些标点符号不进行编码,特殊字符的unicode编码采用UTF-16BE形式存储,然后在前面加上“%u”

shellcode编码
shellcode是利用软件漏洞的代码片段。汇编指令对应的十六进制的机器码即为shellcode。shellcode的名称来源于它可以获得系统的shell。
shellcode编码在字符ASCII的16进制前添加\x



 浙公网安备 33010602011771号
浙公网安备 33010602011771号