

操作系统实验一
2019-04-14 21:11 陆许 阅读(953) 评论(0) 编辑 收藏 举报一、实验目的
(1)加深对处理机调度的作用和工作原理的理解。
(2)进一步认识并发执行的实质。
二、实验要求:
本实验要求用高级语言,模拟在单处理器情况下,采用多个调度算法,对N个进程进行进程调度。语言自选。
并完成实验报告。
三、实验内容:
在采用多道程序设计的系统中,往往有若干个进程同时处于就绪状态。
当就绪状态进程个数大于处理器数时,就必须依照某种策略来决定哪些进程优先占用处理器。
- 进程及进程队列的表示。
- 处理器调度算法:FCFS,SJF,RR,HRRN,MLFQ等
- 跟踪进程状态的转化
- 输出:系统中进程的调度次序,计算CPU利用率,平均周转时间和平均带权周转时间
四、实验过程与结果
- 算法思想与设计
- 算法实现代码
- 运行结果
示例:
进程定义:
进程队列:
调度算法:
1.RR:
1.1 算法思想:
- CPU时间划分为时间片,例如100ms
- 时间片调度:调度程序每次把CPU分配给就绪队列首进程使用一个时间片,就绪队列中的每个进程轮流地运行一个时间片。当这个时间片结束时,强迫一个进程让出处理器,让它排列到就绪队列的尾部,等候下一轮调度
1.2 算法设计:(采用描述或程序流程图)
Ø进程排序
Ø队列不为空时循环:
Ø到达?
Ø剩余服务时间>时间片
Ø运行时间
Ø剩余服务时间
Ø剩余服务时间<=时间片
Ø运行时间
Ø剩余服务时间、完成时间、周转时间、加权周转时间
Ø保存
Ø从队列删除进程
1.3 算法实现代码
class Process: def __init__(self, name, arrive_time, serve_time): self.name = name # 进程名 self.arrive_time = arrive_time # 到达时间 self.serve_time = serve_time # 需要服务时间 self.left_serve_time = serve_time # 剩余需要服务时间 self.finish_time = 0 # 完成时间 self.cycling_time = 0 # 周转时间 self.w_cycling_time = 0 # 带权周转时间 class RR: def __init__(self, process_list, q): self.process_list = process_list self.q = q def scheduling(self): process_list = self.process_list process_list.sort(key=lambda x: x.arrive_time) pf = [] q = self.q index = int(0) running_time = int(0) print("\nscheduling:") while len(process_list) > 0: p = process_list[index] if p.arrive_time > running_time: running_time = p.arrive_time if p.left_serve_time > q: print(p.name, q) running_time += q p.left_serve_time -= q else: print(p.name, p.left_serve_time) running_time += p.left_serve_time p.left_serve_time = 0 p.finish_time = running_time p.cycling_time = p.finish_time - p.arrive_time p.w_cycling_time = p.cycling_time / p.serve_time print('--', p.name, p.arrive_time, p.serve_time, p.left_serve_time, p.finish_time, p.cycling_time, p.w_cycling_time) pf.append(p) process_list.remove(p) index -= 1 index += 1 if index >= len(process_list): index = 0 return pf def getProcess(): process_list = [] processA = Process('A', 0, 4) processB = Process('B', 1, 3) processC = Process('C', 2, 4) processD = Process('D', 3, 2) processE = Process('E', 4, 4) process_list.append(processA) process_list.append(processB) process_list.append(processC) process_list.append(processD) process_list.append(processE) print("\nProcess:") for p in process_list: print(p.name, p.arrive_time, p.serve_time) return process_list process_list=getProcess() rr=RR(process_list,2) pf=rr.scheduling() print("\nResult:") for p in pf: print(p.name, p.arrive_time, p.serve_time, p.left_serve_time, p.finish_time, p.cycling_time, p.w_cycling_time)
1.4 运行结果
A 0 4
B 1 3
C 2 4
D 3 2
E 4 4
A 2
B 2
C 2
D 2
-- D 3 2 0 8 5 2.5
E 2
A 2
-- A 0 4 0 12 12 3.0
B 1
-- B 1 3 0 13 12 4.0
C 2
-- C 2 4 0 15 13 3.25
E 2
-- E 4 4 0 17 13 3.25
D 3 2 0 8 5 2.5
A 0 4 0 12 12 3.0
B 1 3 0 13 12 4.0
C 2 4 0 15 13 3.25
E 4 4 0 17 13 3.25
2.FCFS:
2.1 算法思想:
按照作业进入系统后备队列的先后次序来挑选作业。
2.2 算法设计:(采用描述或程序流程图)
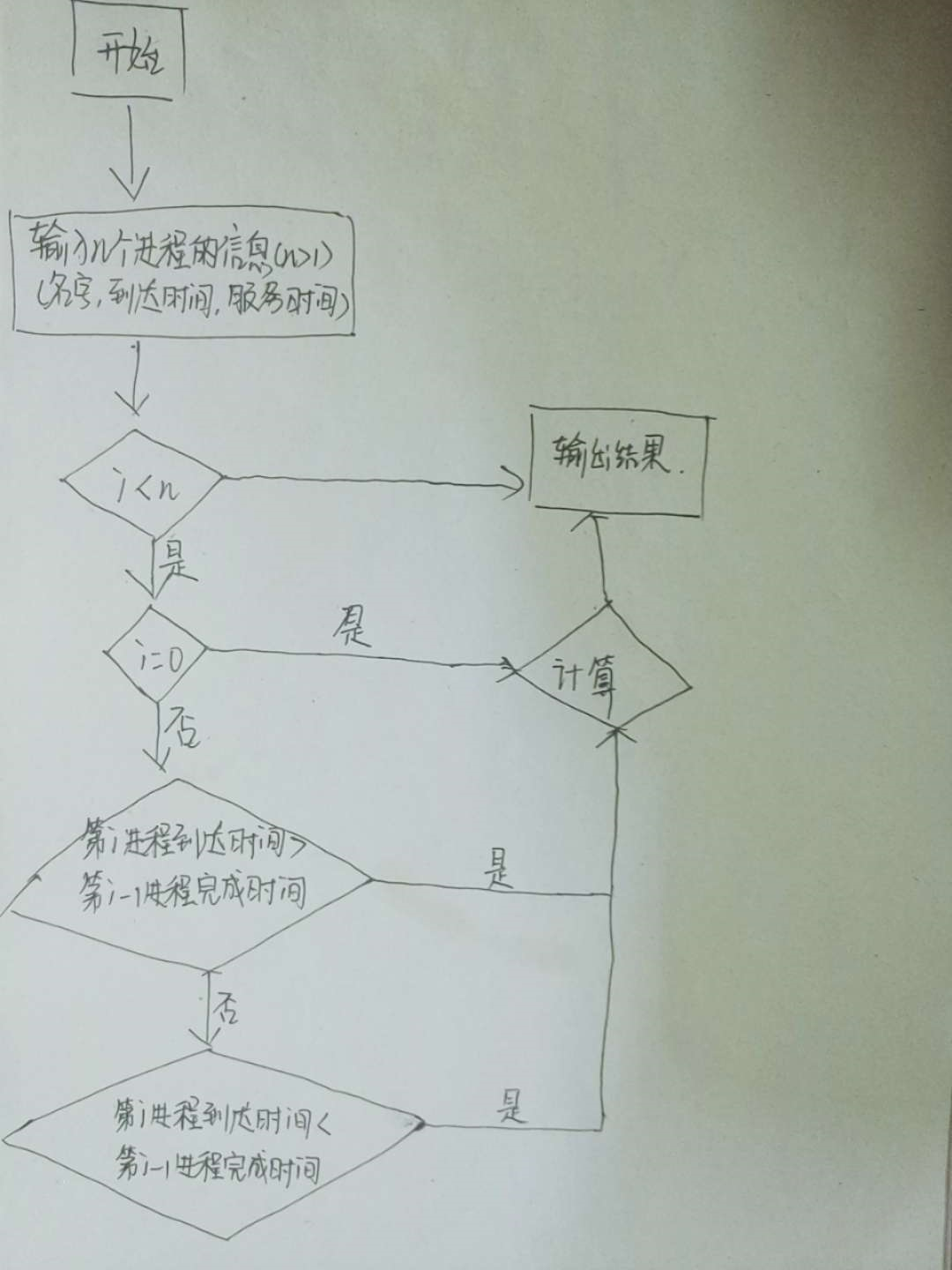
2.3 算法实现代码
pf = [] n = int(input("输入进程数:")) def inpf(): i=0 while (i < n): name = input("输入第%d个进程名:" % (i + 1)) arrivetime = int(input("输入到达时间:")) servetime = int(input("输入服务时间:")) pf.append([name, arrivetime, servetime, 0, 0, 0, 0]) # 进程名,到达时间,服务时间,开始时间,完成时间,周转时间,带权周转时间 i += 1 print('--', name, arrivetime, servetime) def FCFS(): #对列表按照到达时间进行升序排序 x:x[1]为依照到达时间进行排序 pf.sort(key=lambda x: x[1], reverse=False) for i in range(n): if (i == 0): start_time = int(pf[i][1]) # 开始时间=到达时间 pf[i][3] = start_time pf[i][4] = start_time + int(pf[i][2]) # 完成时间=开始时间+服务时间 if (i > 0 and int(pf[i - 1][4]) < int(pf[i][1])): # 第i-1进程完成时间<第i进程到达时间 start_time = int(pf[i][1]) pf[i][3] = start_time pf[i][4] = start_time + int(pf[i][2]) else: start_time = pf[i - 1][4] # 开始时间=上一个进程的完成时间 pf[i][3] = start_time pf[i][4] = start_time + int(pf[i][2]) i += 1 for i in range(n): pf[i][5] = float(pf[i][4] - int(pf[i][1])) # 周转时间=完成时间-到达时间 pf[i][6] = float(pf[i][5] / int(pf[i][2])) # 带权周转时间=周转时间/服务时间 i += 1 for i in range(n): print(pf[i][0], int(pf[i][1]), int(pf[i][2]), int(pf[i][3]), int(pf[i][4]), \ float(pf[i][5]), float(pf[i][6])) # 输出每个进程的进程名,到达时间,服务时间,开始时间,完成时间, 周转时间。带权周转时间 i += 1 if __name__ == '__main__': inpf() FCFS()
2.4 运行结果
输入进程数:4
输入第1个进程名:A
输入到达时间:2
输入服务时间:2
-- A 2 2
输入第2个进程名:B
输入到达时间:1
输入服务时间:3
-- B 1 3
输入第3个进程名:C
输入到达时间:0
输入服务时间:3
-- C 0 3
输入第4个进程名:D
输入到达时间:3
输入服务时间:5
-- D 3 5
C 0 3 0 3 3.0 1.0
B 1 3 3 6 5.0 1.6666666666666667
A 2 2 6 8 6.0 3.0
D 3 5 8 13 10.0 2.0
3.SJF:
3.1 算法思想:
总是选取预计计算时间最短的作业投入运行。
3.2 算法设计:(采用描述或程序流程图)

3.3 算法实现代码
3.4 运行结果
4.MLFQ算法
4.1 算法思想:
较高优先级队列的进程/线程分配给较短时间片,较低优先级队列的进程线程分配较长时间片,最后一个队列进程/线程按FCFS算法进行调度。同一队列中的进程/线程按FCFS原则排队。
4.2 算法设计:(采用描述或程序流程图)
4.3 算法实现代码
class Process: def __init__(self, name, arrive_time, serve_time): self.name = name # 进程名 self.arrive_time = arrive_time # 到达时间 self.serve_time = serve_time # 需要服务时间 self.left_serve_time = serve_time # 剩余需要服务时间 self.finish_time = 0 # 完成时间 self.cycling_time = 0 # 周转时间 self.w_cycling_time = 0 # 带权周转时间 class RR: def __init__(self, process_list, q): self.process_list = process_list self.q = q def scheduling(self): process_list = self.process_list process_list.sort(key=lambda x: x.arrive_time) pf = [] q = self.q index = int(0) running_time = int(0) while len(process_list) > 0: p = process_list[index] if p.arrive_time > running_time: running_time = p.arrive_time if p.left_serve_time > q: print(p.name, q) running_time += q p.left_serve_time -= q else: print(p.name, p.left_serve_time) running_time += p.left_serve_time p.left_serve_time = 0 p.finish_time = running_time p.cycling_time = p.finish_time - p.arrive_time p.w_cycling_time = p.cycling_time / p.serve_time print('--', p.name, p.arrive_time, p.serve_time, p.left_serve_time, p.finish_time, p.cycling_time, p.w_cycling_time) pf.append(p) process_list.remove(p) index -= 1 index += 1 if index >= len(process_list): index = 0 return pf # 定义队列类 class Queue: def __init__(self, level, process_list, q): self.level = level self.process_list = process_list self.q = q def size(self): return len(self.process_list) def get(self, index): return self.process_list[index] def add(self, process): self.process_list.append(process) def delete(self, index): self.process_list.remove(self.process_list[index]) class MulitlevedFeesbackQueue(): def __init__(self, queue_list): self.queue_list=queue_list def scheduling(self): q_list = self.queue_list for i in range(len(q_list)): if i==len(q_list)-1: print("=======对最后一个队列执行RR算法=====") #最后一个队列重新设置到达时间 for t in range(len(q_list[i].process_list)): q_list[i].process_list[t].arrive_time = t rr_last_queue = RR(q_list[i].process_list, q_list[i].q) rr_last_queue.scheduling() else: currentQueue = q_list[i] index=int(0) while(True): if currentQueue.get(index).left_serve_time>q_list[i].q: currentQueue.get(index).left_serve_time-=q_list[i].q print("第%d队列时间片:%d"%(i,q_list[i].q)) print("进程没有执行完毕,需要添加至下一队列末尾:进程名称:%s" % (currentQueue.get(index).name)) q_list[i+1].add(currentQueue.get(index)) index+=1 else: print('服务时间并弹出:',currentQueue.get(index).name) currentQueue.get(index).left_serve_time=0 currentQueue.delete(index) if index==currentQueue.size(): break processA=Process('A',0,16) processB=Process('B',1,3) processC=Process('C',2,4) processD=Process('D',3,2) processE=Process('E',4,4) process_list0,process_list1,process_list2=[],[],[] process_list0.append(processA) process_list0.append(processB) process_list1.append(processC) process_list1.append(processD) process_list2.append(processE) queue0=Queue(0,process_list0,2) queue1=Queue(1,process_list1,4) queue2=Queue(2,process_list2,8) queue_list=[] queue_list.append(queue0) queue_list.append(queue1) queue_list.append(queue2) for i in range(3): print(queue_list[i].level,queue_list[i].process_list,queue_list[i].q) mlfq=MulitlevedFeesbackQueue(queue_list) mlfq.scheduling()
4.4 运行结果
0 [<__main__.Process object at 0x00000000027D5160>, <__main__.Process object at 0x00000000027D5198>] 2
1 [<__main__.Process object at 0x00000000027D51D0>, <__main__.Process object at 0x00000000027D5208>] 4
2 [<__main__.Process object at 0x00000000027D5240>] 8
第0队列时间片:2
进程没有执行完毕,需要添加至下一队列末尾:进程名称:A
第0队列时间片:2
进程没有执行完毕,需要添加至下一队列末尾:进程名称:B
服务时间并弹出: C
服务时间并弹出: D
第1队列时间片:4
进程没有执行完毕,需要添加至下一队列末尾:进程名称:A
服务时间并弹出: B
=======对最后一个队列执行RR算法=====
E 4
-- E 0 4 0 4 4 1.0
A 8
A 2
-- A 1 16 0 14 13 0.8125

