

JDK1.7 hashMap并发扩容死循环原理
JDK 1.7扩容的实现代码
void resize(int newCapacity) { Entry[] oldTable = table; int oldCapacity = oldTable.length; ... Entry[] newTable = new Entry[newCapacity]; ... transfer(newTable, rehash); table = newTable; ----线程2如果设置table将丢失C threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1); }
即创建一个更大的数组,通过transfer方法,移动元素
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next; ----线程B执行到这里挂起(未执行)
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
遍历数组中每个位置的链表,对每个元素进行重新hash(rehash = true时,但实际上这玩意都是false,hash= old hash),在新的newTable以头插法的方式插入。
假设有一个hashMap数组(正常是2的N次长度,这里方便举例), 节点3上存有abc元素,此时发生扩容
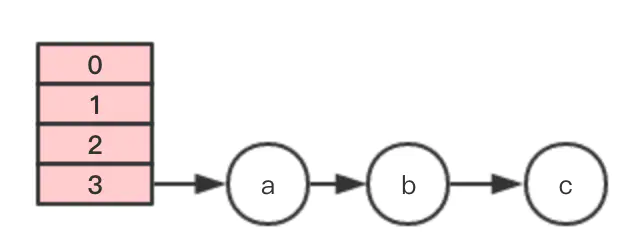
此时假设有两个线程
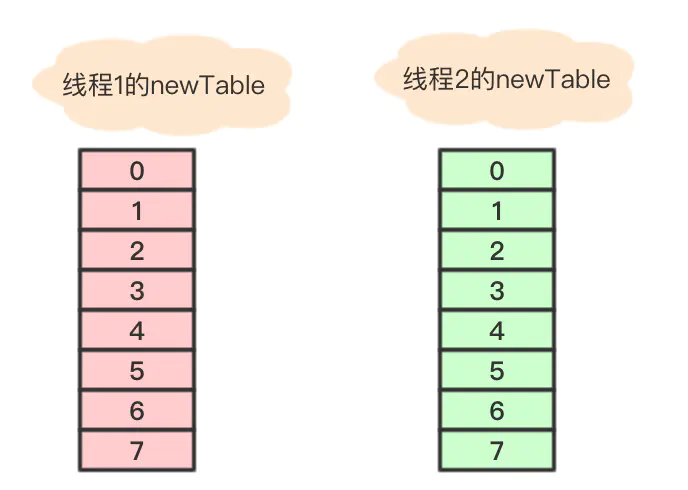
线程B在执行到Entry<K,V> next = e.next;后挂起,此时e指向元素a,e.next指向元素b
到线程A在new table的数组7位置依次用头插法插入3个元素后
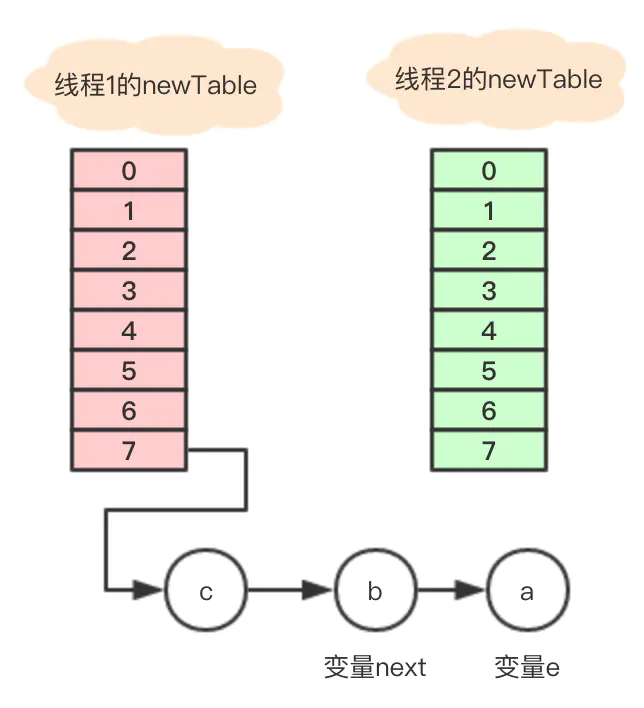
此时线程B继续执行以下代码
Entry<K,V> next = e.next; //next = b e.next = newTable[i]; //将数组7的地址赋予变量e.nextnewTable[i] = e; //将a放到数组7的位置e = next; // e = next = b
执行结束的关系如图
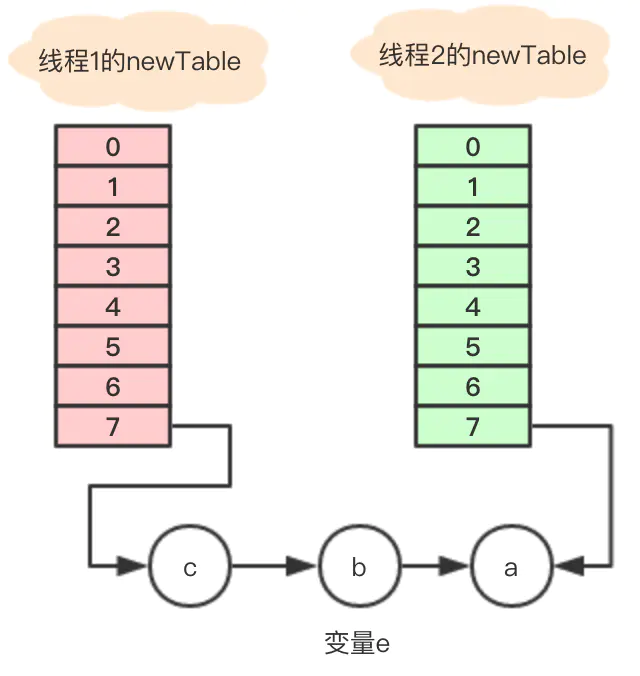
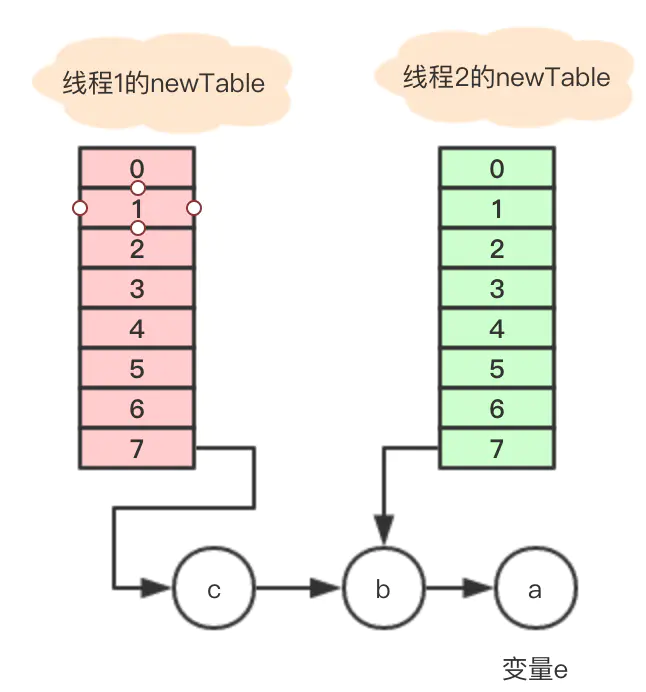
变量e = b不是null,循环继续执行,
Entry<K,V> next = e.next; // next = a e.next = newTable[i]; //数组7地址指向e.next
newTable[i] = e; //将b放到数组7的位置
e = next; //e =next = a执行后引用关系图
此时变量e = a仍旧不为空,继续循环。。
Entry<K,V> next = e.next; // 变量a没有next,所以next = null e.next = newTable[i]; // 因为newTable[i]存的是b,这一步相当于将a的next指向了b,于是问题出现了
newTable[i] = e; //将变量a放到数组7的位置
e = next; // e= next = null
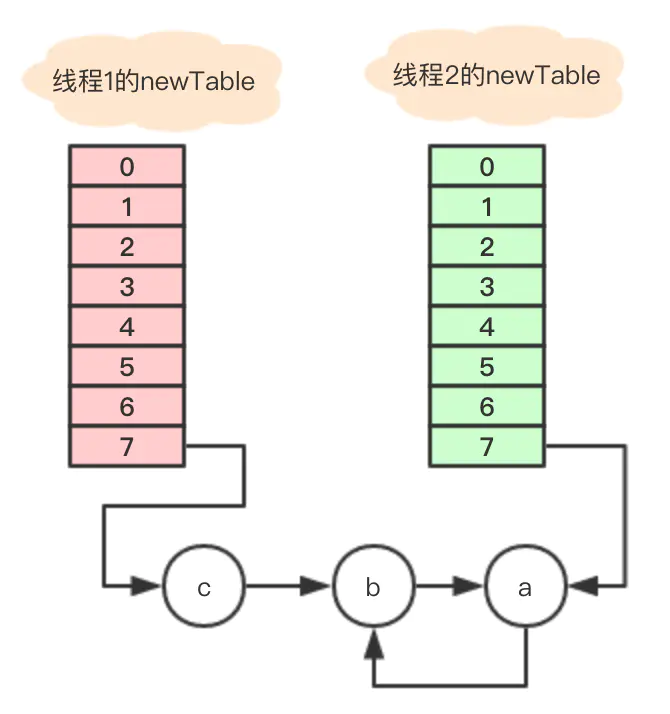
当在数组7遍历节点寻找对应的key时, 节点a和b就发生了死循环, 直到cpu被完全耗尽。
另外,如果最终线程2执行了table = newTable;那元素C就发生了数据丢失问题
该问题在JDK1.8修复了(尾插法),并发还是用concurrent hashmap吧
