


Python基本算法实现及总结归纳
@
冒泡排序
这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端(升序或降序排列),就如同碳酸饮料中二氧化碳的气泡最终会上浮到顶端一样,故名“冒泡排序”。
原理:比较相邻的元素。如果第一个比第二个大(小),就交换他们的顺序。针对所有的元素重复以上的步骤,除了最后一个。最后的元素会是最大(小)的数。
步骤:
1、因为每轮都要交换,最后一组是第 len(arr)-1个和第 len(arr)个,最后一个后面没有再需要比较的,所以共交换 len(arr)-1轮。
2、而每次比较完,最大的数都会被推到最后面,所以每轮遍历可以减去1。
3、这里举例为升序,当i0(以下所以i+num,都代表索引为num)比i1大,就交换这两个数的位置,依次类推,最后一组是第 len(arr)-1个和第 len(arr)个。每次遍历一次,当前最大的已经被推到了最后,所以最后这个不需要再被比较了,需要被比较的遍历的 len(arr)-1个,最后一组是第 len(arr)-2个和第 len(arr)-1个
def bubble_sort(arr):
# i范围为1~n,j
for i in range(1, len(arr)):
for j in range(0, len(arr)-i):
if arr[j] > arr[j+1]:
arr[j], arr[j + 1] = arr[j + 1], arr[j]
return arr
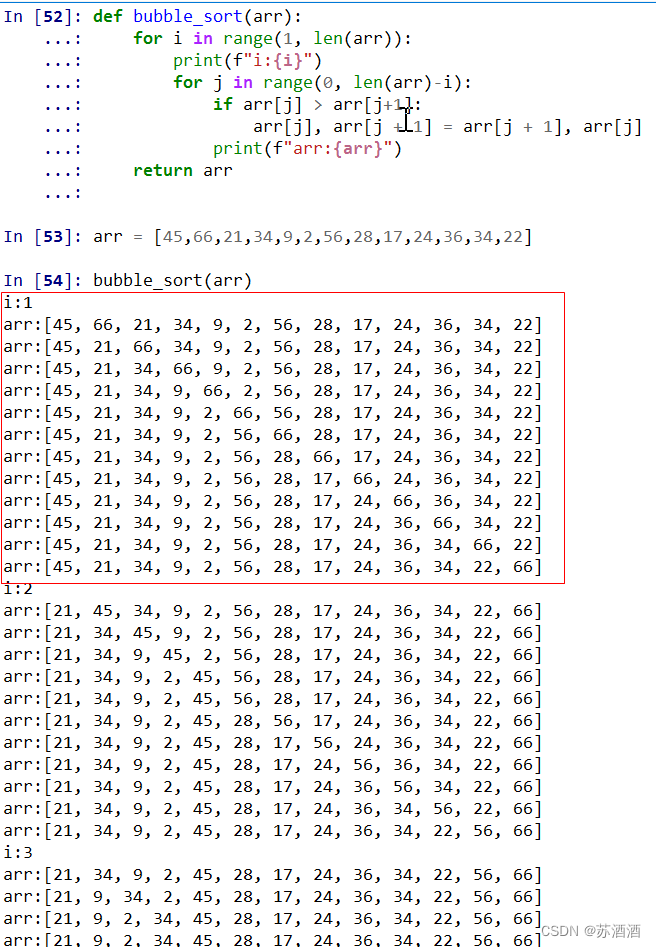
打印一下结果可以只看红框的部分,后面都是一个道理:
1、第一轮遍历,45和66比较跳过,66和21比较,66比21大所以调换位置,如此类推,一直到最后一个22被推到前面。
2、而原本在前面的66,因为是最大的数字已经被推到了最后,不需要再被比较,所以第二轮遍历的时候,遍历次数可以减1。以此类推,每一轮从头开始遍历的时候,遍历的次数又可以再减1。
为了更直观的显示过程,在代码里添加了几处print(),在输出字符串前加f,可以直接在{}里调用命令或变量,不必format和%s:
快速排序
快速排序使用分治法策略来把一个串行(list)分为两个子串行(sub-lists)。
本质上来看,快速排序应该算是在冒泡排序基础上的递归分治法。
虽然快速排序的最坏运行情况是 O(n²),比如说顺序数列的快排。但是在大多数情况下都比平均时间复杂度为 O(n logn) 的排序算法表现要更好,它的平摊期望时间是 O(nlogn),且 O(nlogn) 记号中隐含的常数因子很小,比复杂度稳定等于 O(nlogn) 的归并排序要小很多。
所以,对绝大多数顺序性较弱的随机数列而言,快速排序总是优于归并排序。
原理及步骤:
1、从数组中挑一个基准数pivot,一般选择第一个;
2、然后将所有数与pivot对比,比它大和比它小的分别放在两个新列表,然后通过把pivot放在中间重新组建成一个新列表;
3、根据递归依次重复1和2。
def qsort(seq):
if isinstance(seq, list) and not seq:
return seq
else:
pivot = seq[0]
lesser = qsort([x for x in seq[1:] if x < pivot])
greater = qsort([x for x in seq[1:] if x >= pivot])
return lesser + [pivot] + greater
- 用+的方式连接,当非递归时确实比extend慢,但递归时,+比较快
结果如下
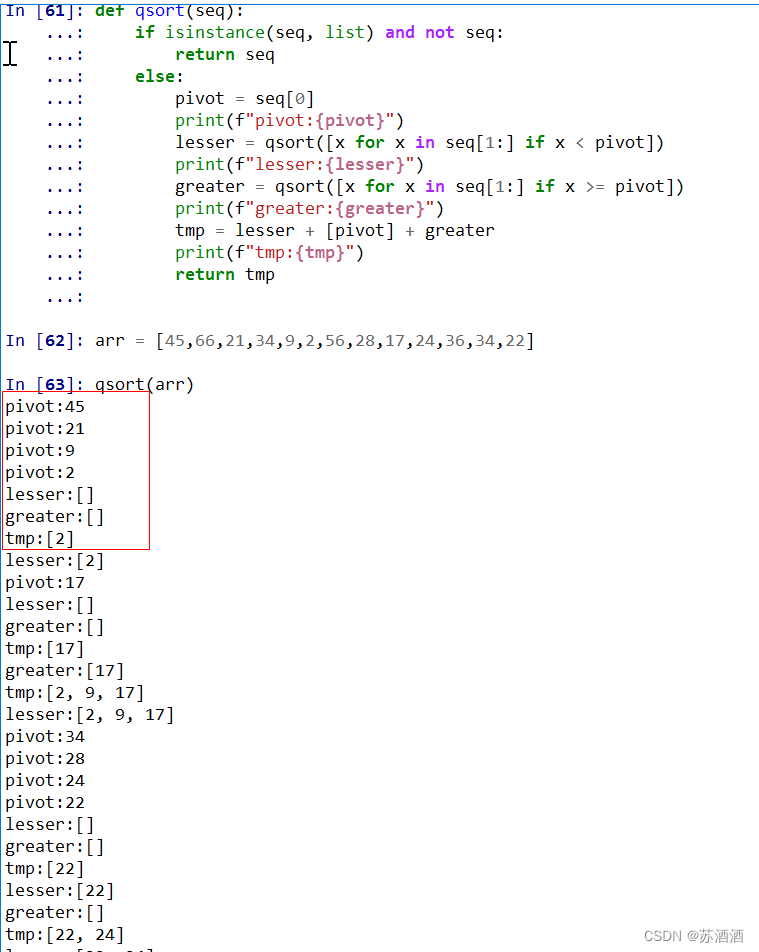
乍一看这个结果好像云里雾里的,解释一下:
1、首先,第一个pivot是45,比它大的lesser本应该为[21,34,9,2,28,17,24,36,34,22],比它大的greater本来为[66,56]。然后注意lesser和这里greater都递归了自身qsort,没有结束,所以一开始没有返回结果。
2、这时对lesser里的21和其他数字又进行了一轮比较,此时得到新的lesser为[9,2,17],新的greater为[34,28,24,36,34,22],仍旧不输出。
3、然后这里又进入新的递归,lesser为[2],greater为[17]。
4、所以每一轮递归pivot都是新的lesser的第一个数,分别为45,21,9,2。
5、而17和2同级,所以处理完lesser的[2]就会处理为greater的[17]。
同理,根据这个逻辑看结果就很清晰了。
插入排序
原理:把整个数组拆分为有序区间和未排序区间,有序一开始只有一个,就是第一个元素,其他则为未排序区间。
对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
在从后向前扫描过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供插入空间。
举例(i表索引,数字为下标,i1不必考虑):
1、比如从小到大排序, 将i3先与i2相比,如果i2比i3大,就把i2插入到i3后,其实就是i2和i3交换位置;
2、再将i3与i1相比,i1如果比i3大,就把i1插入到i3后; 如果相等,则将待插入元素插入到相等元素的后面。(至于相等的情况,在Python里仅单个数字而言,相同的数字意义几乎完全相同,虽说有说放在相同数字后面,我们不考虑这个)
优缺点:
缺点:插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位;
优点:插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率,但已经排好的,又何须还要算法再去排序,所以这个优点就几乎可以当没有了;
对此,后面有个希尔排序,是针对插入排序的一个优化排序。
- while版本代码:
def insert_sort(arr):
# 从数列的第二个元素开始,依次取出,与它的前面的元素值作比较
for i in range(1, len(arr)):
# arr[i]为当前值,arr[i-1]为其前一个值,将二者相比,若后者比前者大,则交换位置
while i >= 1 and arr[i] < arr[i-1]:
arr[i-1], arr[i] = arr[i], arr[i-1]
# 获取再前面的值的索引下标,实现当前值与其前面的值的循环比较
i -= 1
return arr
- 使用for循环的实现
def insert_sort(arr):
for i in range(1, len(arr)):
for j in range(i, 0, -1):
if arr[j] < arr[j - 1]:
arr[j-1], arr[j]=arr[j], arr[j-1]
return arr
得益于Python的两个变量的值可以直接交换而不必借助第三方变量,许多算法里的实现都很类似,比如这里for循环的代码和冒泡特别像,不同的是这里内层循环是倒序。

1、i为1的时候,因为66比45大,所以没有变化。
2、i为2的时候,21先和66比小交换位置,再和45比也小再交换,注意看j。
选择排序
原理:
根据升序或降序,
1、首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置。
2、再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。
3、 重复第二步,直到所有元素均排序完毕。
代码实现的时候,找到的最小元素后,所谓“存放到排序序列的起始位置”不是真正意义上实现insert之类操作的存放到起始位置。只是每轮遍历都借用一个临时存放最小数值索引的标志,然后找到一个比它更小的,然后跟它交换位置。
代码实现步骤(示例:升序):
1、首先遍历找到最小的元素,第一个成为这个元素的是最先被遍历到的第0位,将它赋给一个变量比如min_index,作为一个标记,此时min_index=0。
2、然后再从第二位元素开始遍历,直到找到比min_index更小的值,使它取代之前的成为新的min_index,最后将这两位数进行交换。
3、第二轮遍历开始的时候,将第二位数的索引作为min_index,然后从第三位数之后开始遍历。如此每次交换之后,最前面都是以排好的序列,每次交换的新的min_index都被添加到了上一个min_index的末尾。以此类推,共len(arr)-1轮。
def select_sort(arr):
if len(arr) < 2:
return arr
for i in range(len(arr)-1):
min_index = i
for j in range(i + 1, n):
if arr[j] < arr[min_index]:
min_index = j
if min_index != i:
arr[i], arr[min_index] = arr[min_index], arr[i]
return arr
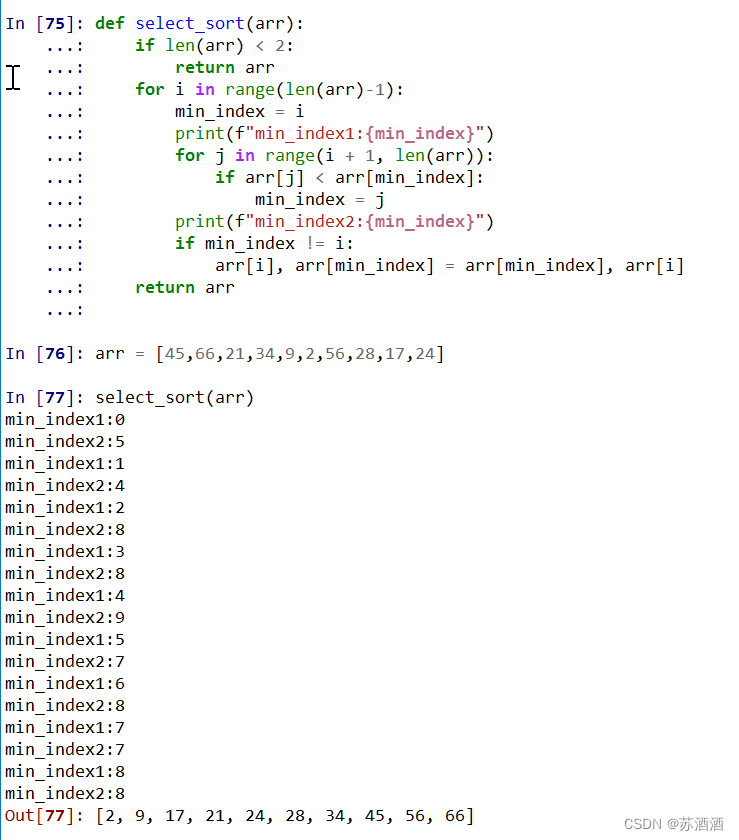
1、第一轮第一个45的min_index 索引为0,继续遍历直到找到2比45小,2的索引为5,然后交换他们的位置,此时列表为[2,66,21,34,9,45,56,28,17,24];
2、进行第二轮遍历,第一位已经是最小的不必再遍历,所以从第二位66开始,默认min_index每次都是遍历最开始的这位,所以是1,直到找到除2以外最小的是9,此时的min_index为4。以此类推。
希尔排序
希尔排序是基于插入排序的改进,不同的是希尔排序先通过分组进行排序,直到分组增量为1 。
图片原理可以参考这张,我觉得特别清楚:https://www.dandelioncloud.cn/article/details/1515512897961775106
原理:
1、将待排序数组按照步长gap进行分组,然后将每组的元素利用直接插入排序的方法进行排序;
2、每次将gap折半减小,循环上述操作;当gap=1时,利用直接插入,完成排序。
示例步骤:
1、比如一个列表长度为10,则每次gap=len(arr)//2,此时gap为5;
2、然后将i0与i5比较大小,按照顺序将其对调位置;然后是i1与i6,以此类推,一直到i4与i9,该轮比较结束。
3、步骤2结束后,再将gap=gap//2,此时5//2得2,再将第一轮即步骤2排序后得到的列表,再按2的间隔比较大小,如i0与i2这样;
5、一直到gap为1结束。
def hill_shell(arr):
# 前面说过,希尔排序是插入排序的优化,自然也是
# 初始化gap值
gap = int(len(arr) // 2)
# 第一层循环:一次改变gap的值对列表进行分组
while gap >= 1:
# 从gap开始
for i in range(gap, len(arr)):
# 从i-gap 开始与选定元素开始倒序比较,每个比较元素之间间隔gap
# i为5~9,j的i-gap为0~4,
for j in range(i - gap, -1, -gap):
if arr[j] > arr[j + gap]:
arr[j], arr[j + gap] = arr[j + gap], arr[j]
gap = int(gap // 2)
归并排序
归并排序,是创建在归并操作上的一种有效的排序算法,效率为 O(n/ log n)。
该算法是采用分治法的一个非常典型的应用,且各层分治递归可以同时进行。分治法:
- 分割:递归地把当前序列平均分割成两半。
- 集成:在保持元素顺序的同时将上一步得到的子序列集成到一起(归并)。
归并排序将两个或两个以上(一般是两个)有序的列表合并成一个新的有序列表。
待排序列表是无序的,使用二分法递归地将列表最终拆分成只有一个元素的子表, 只有一个元素的列表一定是有序的,此时递归往回合并,即可依次将待排序列表拆分然后合并成一个有序的列表。
这是我在其他地方看到的原理:
1、申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列。
2、设定两个指针,最初位置分别为两个已经排序序列的起始位置。
3、比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置。
4、使用递归重复步骤3直到某一指针到达序列尾。
5、将另一序列剩下的所有元素直接复制到合并序列尾。
在Python中并不需要自己去申请空间和指针,所以简化一下:
1、把长度为n的输入序列分成两个长度为n/2的子序列;
2、对这两个子序列分别采用归并排序(递归调用,每次长度除2一直到有出现1个元素的时候,将这个长度为1的子列表和另外一个长度为1的子列表进行元素比较;然后每次向上整合的时候将子列表再进入递归去比较,直到回到最外层全部整合完毕,最后合并成一个最终的排序序列,具体可以看下面的示例分析);
图片参考:
https://img2020.cnblogs.com/blog/163625/202110/163625-20211025135024379-780850807.png
如上面链接的图所示,对列表里的数字一直对半,比如8个,分成2个4位数字为一组,然后每个4位一组的再细分为两个2位为一组,8-(4,4)-((2,2),(2,2)), 一直分到只有两个数字相互比较,排好顺序后回到上一层合并,合并的同时重新对这层数字比较再回到上层。
merge()里面也看到有例子用了pop方法,就不用i,j了,但是pop的效率一向不高,不建议使用,而且也省不了几行代码。
def merge(left, right):
# 合并两个有序列表
res = []
# i,j是用于两个列表循环计数
i, j = 0, 0
while i < len(left) and j < len(right):
if left[i] <= right[j]:
res.append(left[i])
i += 1
else:
res.append(right[j])
j += 1
# 由于条件是and,只要其中一个不符合就没得继续比较,就会跳出循环
# 所以剩下的需要额外添加
res += right[j:] if i == len(left) else left[i:]
return res
def mergeSort(arr):
# 归并函数递归
n = len(arr)
if n < 2:
return arr
middle = n // 2
# 将列表对半,并分别递归调用归并函数后合并
# 奇数时,总是right比left多1
left, right = arr[:middle], arr[middle:]
return merge(mergeSort(left), mergeSort(right))
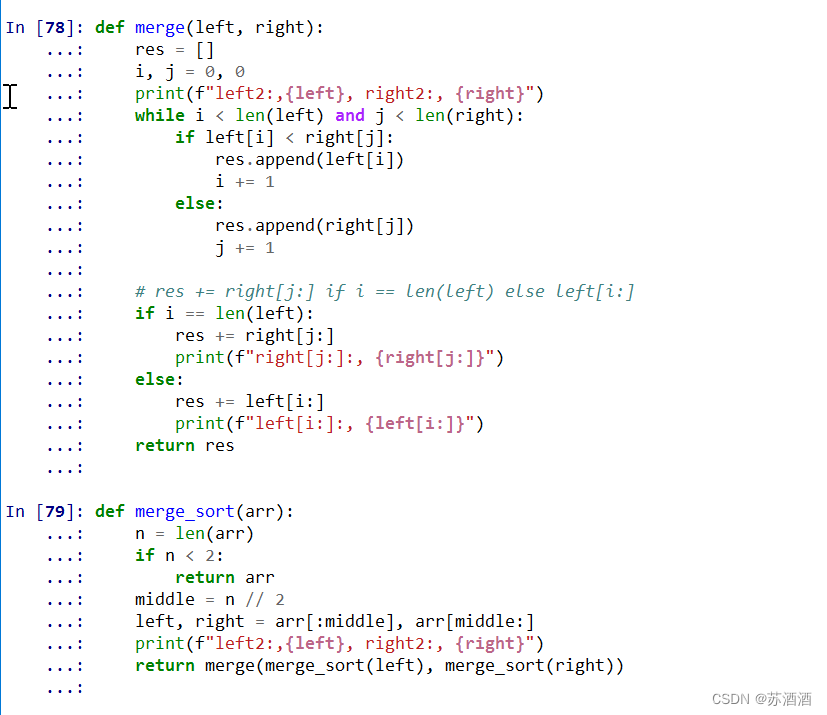
打印结果如下:
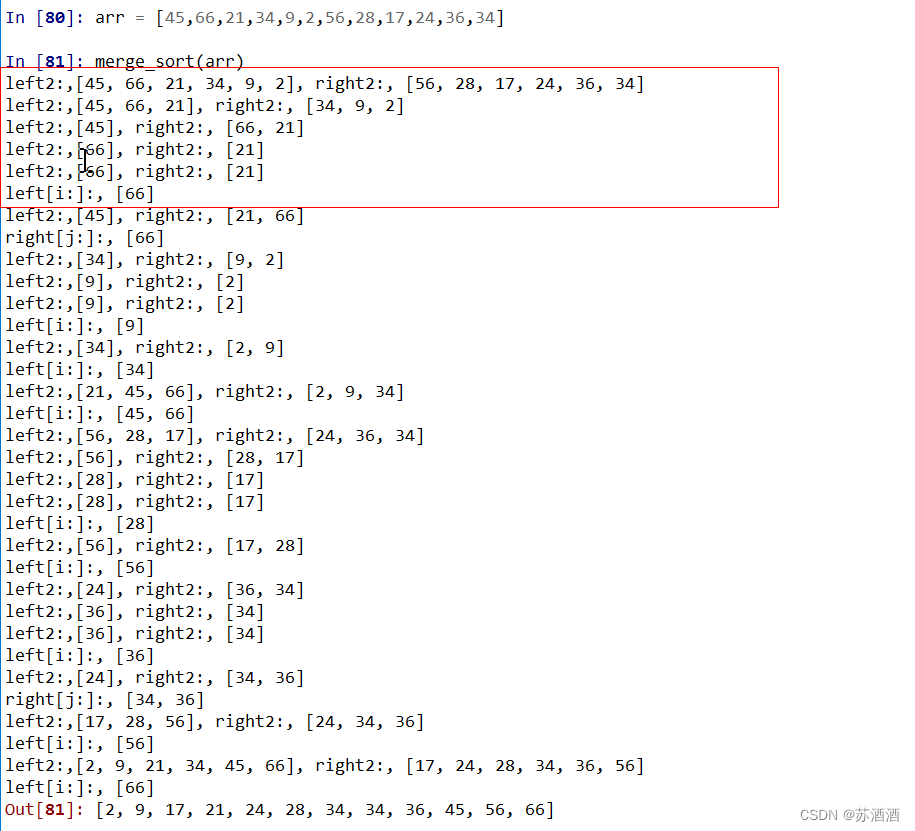
解析如下:
1、假设未排序列表为
[45,66,21,34,9,2,56,28,17,24,36,34],列表长度为12。且由于代码我们的写法,当列表长度为奇数时,多的那个都会在右边。
2、如红框这段过程所示,我们可以得知,在不断对折后,长度变化为
12-(6,6),((3,3),(3,3)),((1,(1,1)),(1,(1,1)))。
3、当走到两个列表长度为1和2时,即
[45],[66,21],会继续对更大的那个长度为2的[66,21]进行比较,所以这里比较完返回的就是[21,66]。
4、然后比较完会回到上一层,即长度为1和2时的
[45],[21,66]。
5、进入while循环,45先和21比较大小,更小的21被append到res里,然后45又和66比,res加入45,最后加入66。而不是45先和66比,再和21比。
6、所以,根据规律,
[45, 66, 21, 34, 9, 2]分成[45, 66, 21]和[34, 9, 2],做完排序分别得到[21, 45, 66]和[2, 9, 34]。
7、
[21, 45, 66]和[2, 9, 34]这两组向上整合,又会进入到while循环,21和2比较完后,依次跟9、34比较,2和9先被添加到res里,直到34比21大,21被添加到res里。45才和34开始比较,依次类推,重新整最后合成[2, 9, 21, 34, 45, 66]。
8、同6、7,另外一半的
[56, 28, 17, 24, 36, 34, 22]同理得到[17, 28, 56],和[22, 24, 34, 36],最后整合得到[17, 22, 24, 28, 34, 36, 56]。
8、最后
[2, 9, 21, 34, 45, 66]和[17, 22, 24, 28, 34, 36, 56]向上整合后同6、7、8步,得到[2, 9, 17, 21, 22, 24, 28, 34, 34, 36, 45, 56, 66]。
各个算法的时间复杂度
已经有人根据算法不同情况做了表格:https://img2020.cnblogs.com/blog/1671325/202003/1671325-20200324112634522-1413571134.png
根据时间复杂度粗略看有哪些算法:
| 时间复杂度 | 意义 | 算法 |
|---|---|---|
| O(1) | 常数阶 | 哈希 |
| O(log n) | 对数阶 | 二分查找 |
| O(n) | 线性阶 | for循环 |
| O(nlog n) | 线性对数阶 | 快速排序、归并排序、希尔排序 、堆排序 |
| O(n^2) | 平方阶 | 冒泡排序、插入排序、选择排序 |
=
这是我在另外一篇文章里总结的关于不同时间复杂度的内容:

附:二分法
刚刚的表里提到了二分法,虽然它不是一种排序算法,甚至是基于已排序好的序列,来进行查找的一种算法。这里也附上一个:
原理是每次取列表中间值mid,用来与需要判断的数做比较,如果search_num不等于mid,则mid就是下次查找的列表里的start或end。每次都可以去掉一半的结果。
def binary_search(arr, search_num):
low, high = 0, len(arr) - 1
while low < high:
print(low, high)
mid = (low + high) // 2
if arr[mid] > search_num:
high = mid
elif arr[mid] < search_num:
low = mid + 1
else:
return mid
return low if arr[low] == search_num else False
参考链接:
1、希尔排序(这篇是所有Python实现希尔算法的里写的最清楚的,图片更一目了然,文章里的图片也来源于这篇):https://www.dandelioncloud.cn/article/details/1515512897961775106
2、归并排序:https://blog.csdn.net/A496608119/article/details/123213879
本文来自博客园,作者:苏酒酒,转载请注明原文链接:https://www.cnblogs.com/sujiujiu/p/16746666.html
