



Scrapy爬取网易云音乐和评论(四、关于API)
教程系列链接目录:
1、Scrapy爬取网易云音乐和评论(一、思路分析)
2、Scrapy爬取网易云音乐和评论(二、Scrapy框架每个模块的作用)
3、Scrapy爬取网易云音乐和评论(三、爬取歌手)
4、Scrapy爬取网易云音乐和评论(四、关于API)
5、Scrapy爬取网易云音乐和评论(五、评论)
项目GitHub地址:https://github.com/sujiujiu/WYYScrapy
前面有提到,API的参考链接,另外再放上几个,
1、http://moonlib.com/606.html(我用的这个)
2、http://blog.csdn.net/qujunjie/article/details/34422379
3、https://binaryify.github.io/NeteaseCloudMusicApi/#/?id=neteasecloudmusicapi(这个比较官方,我也不知道是不是官方,但是很全很全很全)
我们的顺序是:
1、歌手专辑
2、专辑信息(不包括评论)
3、歌曲信息(不包括评论)
4、歌词
5、专辑和歌曲评论(这个另起一章写)
我们拿一个来讲解,其他的类似:
比如,歌手专辑:
http://music.163.com/api/artist/albums/166009?id=166009&offset=0&total=true&limit=12
(经过测试,id前面那个id值可以不需要,有id就足够了)
*offset:偏移量,它其实算是比如歌手的专辑页每页有12首,第一页的offset就是0(一般是0开头),然后第二页offset就是12,第一页0~11刚好12位数,所以offset从12开头,以此类推。可以算作是second_offset = limit*(first_offset+1)
*limit:一页有多少,这个可以改,但是不同的网站有不同的规律,比如豆瓣,它这个limit的上限跟当页显示给你看的不同,比如一页默认给你显示20条数据,但是你给它改成50也会给你返回50条。但是网易云不一样,它显示是12条,它的limit可以往下,但不能往上,往上它返回也是12条,它这是固定的,那超过怎么办呢?假设36条,那么3页对吧,根据前面的offset,不停的改offset,这数字一看就有规律,很容易就能想到用遍历,如图,这是我写的一个歌手专辑信息的函数:
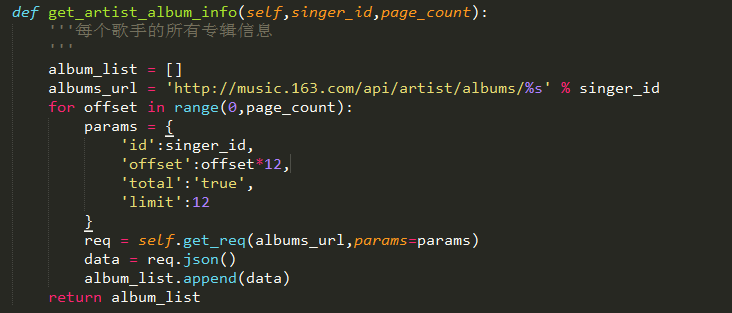
我的那个get_req()函数就是对requests.get做了些处理,中途肯定会遇到各种各样的状态码对吧,这个你们自己去思考。
这里我没有用response,因为不涉及到一个完整的传递链,它只是要存进数据库的某一个字段,如图,这个才是我要进行存储的的函数,其中调用了get_artist_album_info()这个函数,它只是作为一个字段存进了item。
这里的话获取hotAlbums的值应该要判断一下,因为有些页面404,该value值已经没有了。这里需要做处理,但是一直没时间弄,这里只能当个示例讲解,需要各位自己弄一下:
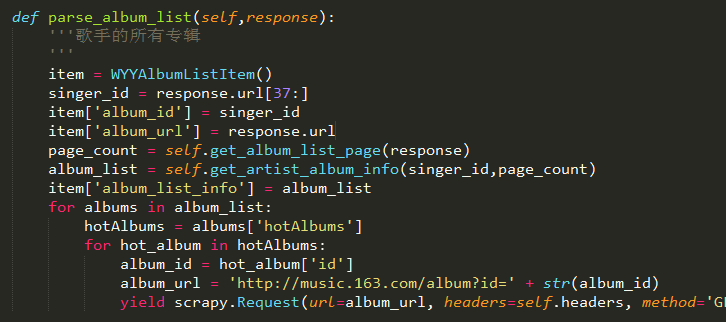
其中调用了get_artist_album_info()这个函数,它只是作为一个字段存进了item。
然后回到get_artist_album_info()函数,这里的建议就是,将固定的不变,会变的用params这个参数,requests.get它后面可以传各种参数,包括params,以及前面的headers。
这个params里有四个参数:
*** id:歌手的id,事实上,有它,albums_url里那个%s占位的地方可以不要,但是因为最开始参照的那个网站有,也是测试成功就没管了。(上面我提供的链接1和2的区别在这里,用哪个都行)
*** offset:这个首先看到我的page_count,就是指页数,比如3页,但其实网易云这个抓不到有多少页,其实应该是从第一页的json返回的专辑信息得到的总专辑数量有多少,然后进行处理的。但是因为写这个的时候我直接爬的页数,但是当时没测试,所以建议改成这样就可以了:
# album_count是一个歌手所有专辑的总数
# 获得的方法可以先爬第一页的json数据,或者别的你们自己找
for offset in range(0,album_count,12):
params = {
'id':singer_id,
'offset':offset,
'total':'true',
'limit':12
}
- total:这个参数的意义除了在评论有用,这里不确定到底有什么用,最开始我以为,改成TRUE能不需要offset,会返回所有数据,后来发现没什么区别,最大上限就是一页12,放着也没关系。
- limit:这里就是12
API
以此类推,其他到底都是这样了,这里把http://moonlib.com/606.html的API集中写一下,method都是GET,中括号代码可省,可写可不写:
1、歌手专辑:
# 歌手专辑:
# 三种写法,随意,推荐第三种,后面都是这样,具体param可以参考上面图片里的代码
1、http://music.163.com/api/artist/albums/[artist_id]/
2、http://music.163.com/api/artist/albums/[166009]/id=166009&offset=0&total=true&limit=5
3、url='http://music.163.com/api/artist/albums/166009'
params = {....}
2、专辑里的歌曲列表
# 专辑里的歌曲列表
http://music.163.com/api/album/2457012?ext=true&id=2457012&offset=0&total=true&limit=10
3、歌曲信息
# 歌曲信息
# 这里说明一下,%5B和%5D就是一对中括号[],最好改成[],像歌手专辑里第一种写法那个一样,因为%5B那种写法还要处理,且麻烦。
http://music.163.com/api/song/detail/?id=28377211&ids=%5B28377211%5D
4、歌词信息
# 这个跟其他都不一样,后面的lv、kv、tv是固定的,只要改id即可。
http://music.163.com/api/song/lyric?os=pc&id=93920&lv=-1&kv=-1&tv=-1
本文来自博客园,作者:苏酒酒,转载请注明原文链接:https://www.cnblogs.com/sujiujiu/p/15371841.html

