


Scrapy爬取网易云音乐和评论(二、Scrapy框架每个模块的作用)
教程系列链接目录:
1、Scrapy爬取网易云音乐和评论(一、思路分析)
2、Scrapy爬取网易云音乐和评论(二、Scrapy框架每个模块的作用)
3、Scrapy爬取网易云音乐和评论(三、爬取歌手)
4、Scrapy爬取网易云音乐和评论(四、关于API)
5、Scrapy爬取网易云音乐和评论(五、评论)
项目GitHub地址:https://github.com/sujiujiu/WYYScrapy
关于如何建立一个scrapy程序,可以参考这两篇文章:
1、http://cuiqingcai.com/3472.html(创建的时候推荐)
2、http://www.cnblogs.com/wuxl360/p/5567631.html
关于使用mongodb,可以参考:http://www.jianshu.com/p/30408d8ad1c0
另外,这篇原来是发在CSDN上的,后来不允许写爬取类的东西,修改的时候被屏蔽了,这里是迁移过来的,要复制代码可以去我GitHub。
一、建立的命令:
scrapy startproject + 你的项目名
第一篇文章有提到两个比较特别且有用的地方:
1、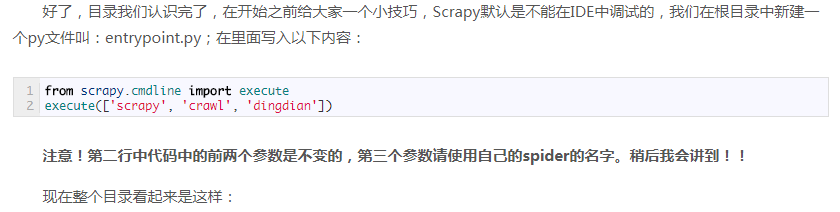
解释一下:execute里面的三个字符串连起来它其实就是最后执行scrapy程序的命令。这个文件的好处是,倘若你在使用编辑器,比如sublime,是可以在配置后直接执行的,而不用打开DOS窗口,如果你在sublime里直接执行scrapy本身的任何一个文件,它都不会执行成功,而只能执行这个entrypoint.py,名字应该随意吧,无所谓。
另一点请参考以下的第三部分
二、框架结构
现在整个框架的结构是这样的:
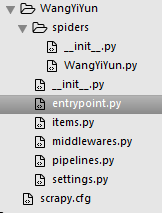
当然,这个spiders文件夹下的WangYiYun.py并不是自动生成的,这个需要我们自己建立,这个文件就是主爬虫程序。另外,这个脚本的名字建议不要取和项目名同名,否则后面可能会踩坑。以下简称WYY.py,大家最好将这个文件名改成这个,省得出错,我因为已经生成了,改了出错。解决办法是:在代码除编码外的首行加上:
from __future__ import absolute_import
- entrypoint.py:执行程序,就想象是run/python xx.py
- items.py:如果你学过orm的话,会很好的理解它,它相当于数据库的字段。
- middlewares.py:这个是个中间件,起初我也不知道它是做什么的,因为并没有用到。且很多例子上显示的结构没有它,基本上我们也不会改到它。很久之后无意在B站看到一个Scrapy的教学视频,才了解到如果需要用到代理池,可以在里面做处理。
- pipelines.py:这个就是定义存储的文件,比如连接,使用哪个数据库存储。
- settings.py:一看就知道,是配置文件。
三、关于setting配置:
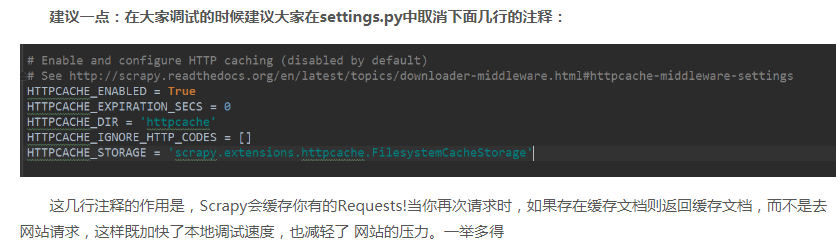
1、关于调试
上面的原因和配置解释的很清楚,参考http://cuiqingcai.com/3472.html:
2、关于spidername和robots.txt

BOT_NAME很重要,在WYY.py文件里写脚本的时候,继承自scrapy.Spider的这个类,它需要有一个name,而这两者必须同名。

最下面那行的ROBOTSTXT_OBEY,大家知道爬虫绕不开robots.txt这个文件,每个网站都会有这个网站,是必须遵守的一个守则吧,就是有些不让你爬,有些又允许你爬。默认是True,如果失败了,可以尝试将其注释,然后复制一行,改为False。
settings.py文件里大多都是写好的,你只要将它复制,取消注释,然后修改即可,最好不要不复制直接在原文上改,万一改到了什么出了错,还能有个参照物。
3、关于headers
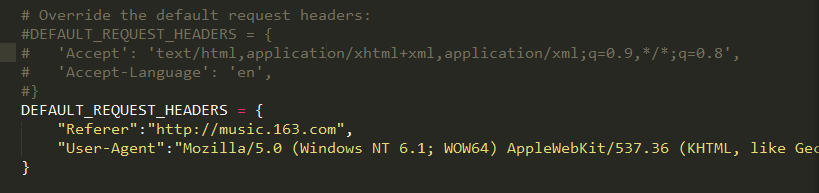
重要的一般就是Referer、User-Agent(这个必须要有)、Accept(可选,但是涉及到xhr,即json文件,就要修改了)。
这里将它注释,改成自己的,你也可以写在主爬虫WYY.py文件里另写,比较自由,写在这里算是一个基本配置吧。
4、关于ITEM_PIPELINES
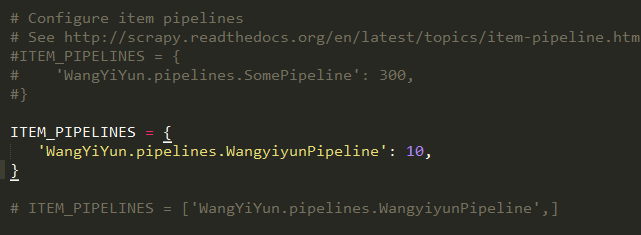
这个是启用一个Item Pipeline组件,数字代表优先级,越小越优先,没有注释的那行是我的,而下面还有一行,是我之前在网上看过的一种写法,但是并不能成功,它应当是一个字典,列表不行
5、关于mongodb配置
随便写在哪,我们就写在刚刚ITEM_PIPELINES的后面
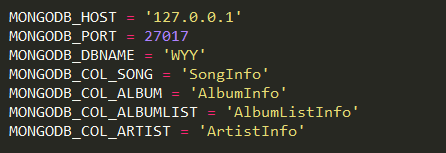
这里顺便建议,常量都用大写。
HOST是本地,PORT是端口,DBNAME是数据库,WYY。
接下来四个是集合了,相当于table,这个顺序是倒序。
1、MONGODB_COL_ARTIST - > ArtistInfo -> 所有的歌手列表
2、MONGODB_COL_ALBUMLIST - >AlbumListInfo - > 每个歌手的所有专辑列表
3、MONGODB_COL_ALBUM - >AlbumInfo - > 每张专辑内的所有歌曲列表
4、MONGODB_COL_SONG - > SongInfo -> 每首歌曲的信息
四、关于items.py
它就相当于SQL/MySQL里的字段,它没有什么特别的字段类型,反正所有都是scrapy.Field()就可以了,
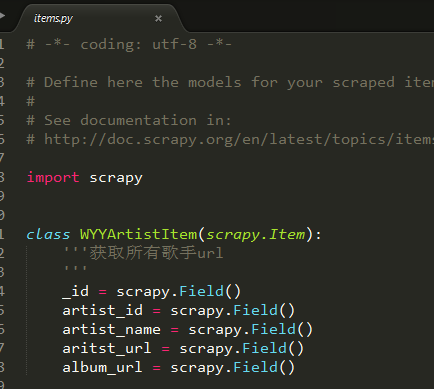
另外三个集合同样,每个单独写个类,依照你们自己的需求定字段即可。
五、关于pinelines.py
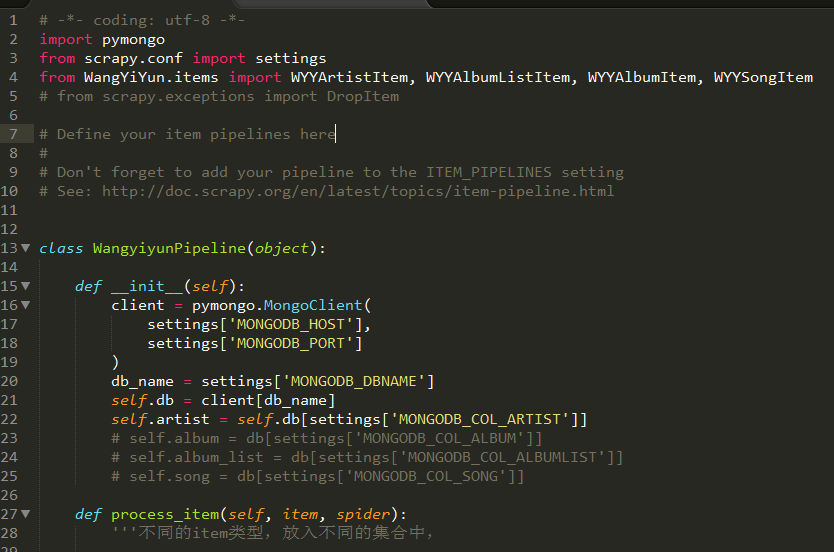
切记,要记得导入items里的那几个你定义的字段的类,我之前忘了导入,然后一切程序正常,就死活存不进去,也不报错,差点掉坑里走不出来
然后这个WangyiyunPipeline基本就两块,一个初始化__init__(),一个process_item(),前者是用来连接的,后者是用来存储的。
可以看到我有一些注释,这里说明一下,因为涉及到多个集合存储,一开始真不知道怎么弄,一开始我以为把每个都扔__init__就成了,然后通过self调用,后来发现不行,在__init__定义一个集合就可以了。process_item()还是参考刚刚那个GitHub那个项目,才知道通过isinstance判断。
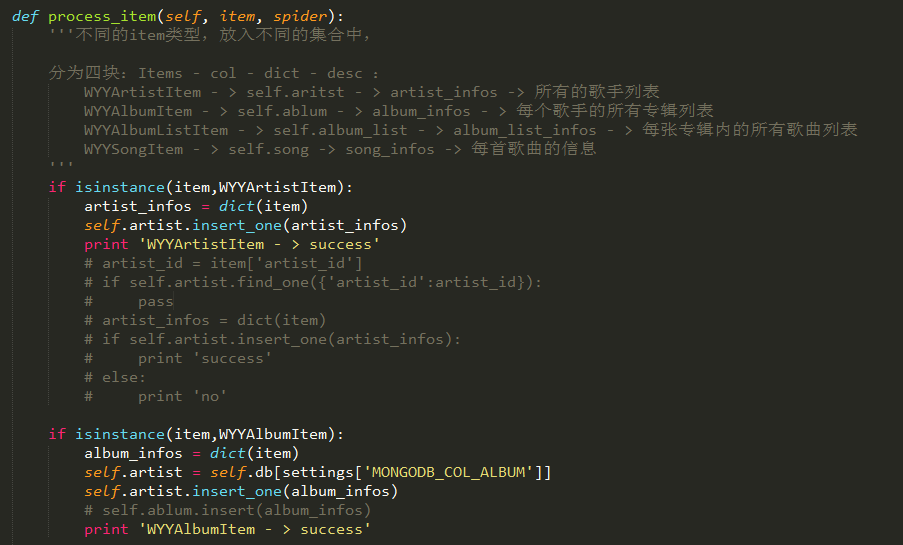
isinstance大家知道什么意思吧,然后每个item对应的什么在注释我也写了。另外,我下面还有一些被注释掉的代码部分,这里就是我在最开头说的,想要跳过一些重复的地方,但是跳过之后不知道做什么处理。
在不用框架的时候,我们存Mongodb。是先定义一个空字典,然后赋值,最后insert,这里也是一样的,只不过,我们是将传入的item给dict化。
而后面,在不使用默认的集合时,重新赋一个取代之前的artist即可。
接下来我们开始正式写代码了。
本文来自博客园,作者:苏酒酒,转载请注明原文链接:https://www.cnblogs.com/sujiujiu/p/15371832.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号