



Scrapy爬取网易云音乐和评论(一、思路分析)
教程系列链接目录:
1、Scrapy爬取网易云音乐和评论(一、思路分析)
2、Scrapy爬取网易云音乐和评论(二、Scrapy框架每个模块的作用)
3、Scrapy爬取网易云音乐和评论(三、爬取歌手)
4、Scrapy爬取网易云音乐和评论(四、关于API)
5、Scrapy爬取网易云音乐和评论(五、评论)
项目GitHub地址:https://github.com/sujiujiu/WYYScrapy
很尴尬,csdn不允许发爬取类的文章然后都屏蔽了,然后重新发到博客园这边了。
前提:
scrapy这个框架很多人用过,网上教程也很多,但大多就是爬爬小说这种比较简单且有规律的,网易云音乐也有很多人写过,也有API,不过大多是爬取了热门歌曲,或是从歌单下手,但是考虑到歌单会有很多重复的。当然,从歌手页的话,如果有多个歌手合唱,那每个歌手页也都会有这首歌,但他们的链接是一样的,也是会有重复的,但是相对来说就比较少,所以就从歌手下手。
在GitHub上也有很多优秀的例子,但没有文档,我这里写一个整站的。
项目GitHub地址:https://github.com/sujiujiu/WYYScrapy
因为种种原因,我后来还是没有用框架又写了一遍。这一块运行成功了,但是我没有去关注数量就中断了,就只能拿出来当教程吧。
- 开发环境:WIN7+Anaconda+py2.7+scrapy
- 数据库:MongoDB
- 文章的顺序:先分析思路,再分析scrapy框架每个模块的作用,最后写代码和分析API,只有5篇。
之前有小伙伴问我为什么在已经出到3.x后期了我还要用2.7,其实是我当时学的时候在折腾2.7,就是懒。而且当时scrapy对py3很不友好,文档也很有限,当然是后来才知道Anaconda这个好东西的。Anaconda2和3都有了,3能不能装scrapy我不知道,还没试过。如果你不想用2.7,可以先尝试下Anaconda3装一装scrapy看看能不能装成功,是哪个版本的。
一、我们先爬歌手,有两种方法:
方法一:遍历id
第一种是遍历,id数大概十一二万的样子,大多id是相隔不远的。
- 优点:遍历比较方便,比较全。有个别歌手有主页,但是没有申请音乐人,只能通过自己搜索访问id,用这种方式比较完整。
- 缺点:但是这种方式会有很多404,就需要你去处理。
但我最开始用的是下面这种,我们也拿这个来分析:
方法二:从分类获取所有入驻的歌手的id
优缺点与方法一刚好相反。
- 优点:不用去做404处理。
- 缺点:获取歌手不完全。分类里只有已经入驻的歌手,你仔细搜搜就会发现很多歌手的主页只有一个收藏的标签,却没有个人主页的标签。没有个人主页的都是没有入驻、没有签约,或是歌是被别人上传的,被归类到该主页下的。
1、从这个页面,爬取所有歌手的id:http://music.163.com/#/discover/artist
这里要说一下,网易云的所有网址,要去掉中间那个#号才是真正的url,带#的查看源代码是获取不到真正的信息的。所以正的url其实是:http://music.163.com/discover/artist 。
我们看这个页面左侧栏:

2、因为当时我写的时候,参考到这篇,https://github.com/runningRobin/music163/blob/master/music163/spiders/spider.py
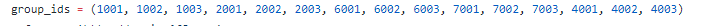
这个group_ids里的就是左侧每个项对应所有的页面了(不包括最上方的推荐歌手和入驻歌手,因为包含在其他里面了)
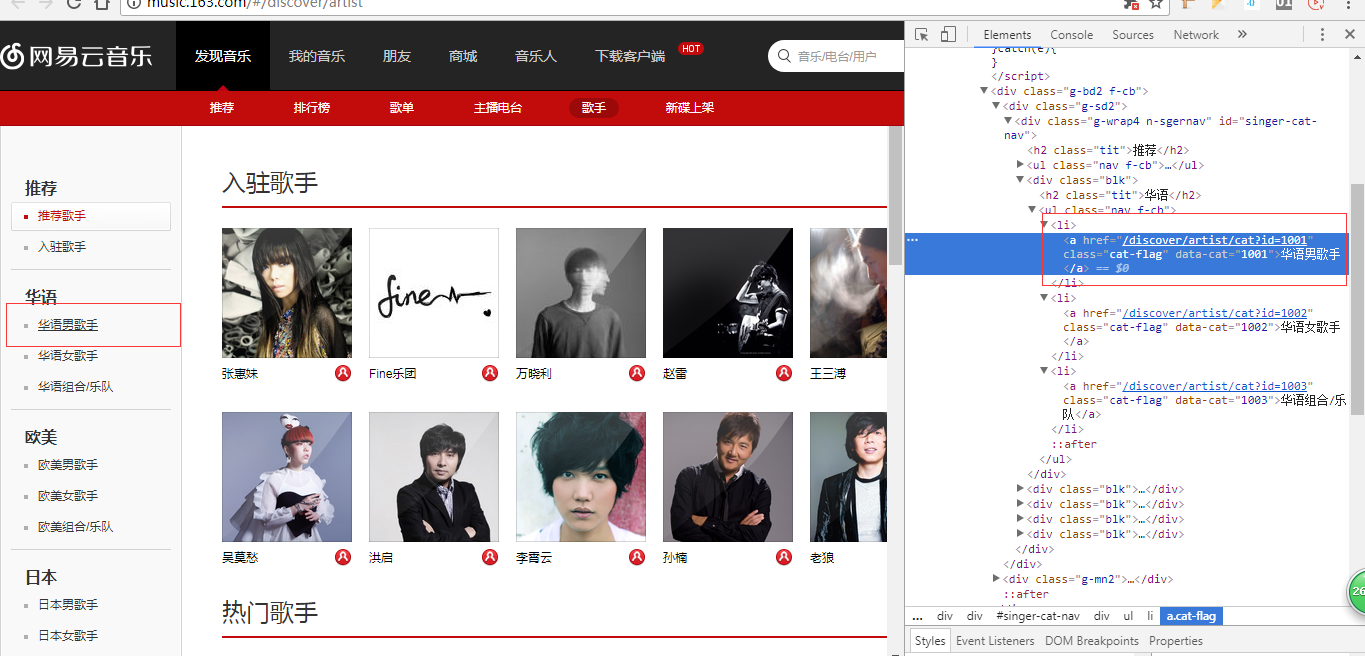
3、我们按F12或右键检查,如图,每个对应的url是:http://music.163.com/discover/artist/cat?id=xxx:
4、然后我们再点进去:
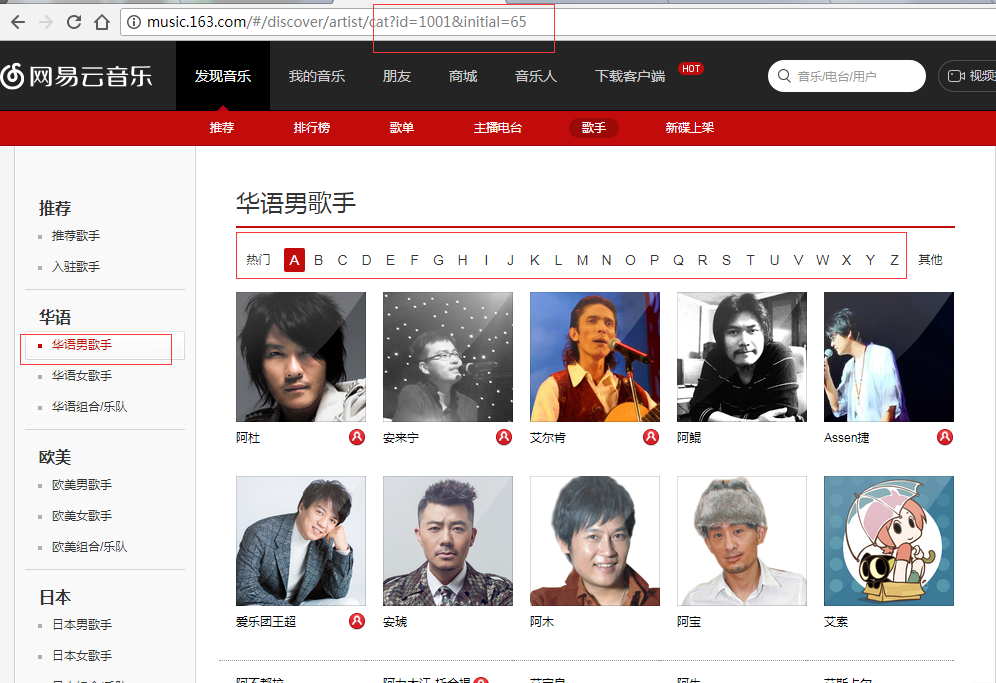
url的id就是上面这个id了,而后面的initial是什么呢?initial是首字母的意思,你看下面我们选中的是A,然后它是65,是不是想到ASCII码,在ASCII码中A就是从65开始的,Z是90,后面以此类推,最后有个其他,是0,我们将它弄成一个列表:
# 男女、国家分类id
group_ids = (1001, 1002, 1003, 2001, 2002, 2003, 6001, 6002, 6003, 7001, 7002, 7003, 4001, 4002, 4003)
# 歌手姓名首字母id
initials = [i for i in range(65,91)] + [0]
二、歌手页
1、点进来之后我们来到歌手页,http://music.163.com/#/artist?id=6452 ,同样,去掉#
2、我们会发现下面有好几个块,

我们获取的这个url对应的是热门50首,如果你只需要热门歌曲你可以获取它所有链接:

这个代码被我分为两块,第一块是热门50首的url,也只有url。
而第二块textarea里是json,是这些歌曲的完整的信息,我获取的是json信息,只不过,这些信息通过lxml.etree或者BeautifulSoup用text的方式获取下来会是字符串,我们需要用json将它格式化,但是极个别在爬取的过程中,死活获取不到。
3、上面那个是歌手的热门歌曲,我们要获取全站,就得从歌手的专辑下手,获取专辑里所有的歌手才行。因为scrapy本身的束缚,其实说是全站,并不是那么方便,比如这四个板块,我们只能选一个,一直往下,单曲或MV就得另写。
4、我们在专辑页会发现,有些是有很多页的,后来搜的时候发现了API,所以接下来的东西,我们就不通过页面的方式了。
API我是通过这个网站发现的:http://moonlib.com/606.html ,因为最开始我的目的是爬评论,来看到评论的API很多变了,我以为这些都变了,一开始还搁置了没用,傻傻的去写lxml,但是它的翻页的序号是爬不到的,后来随手测试了一下API,发现都有用。
我们用到的是2到6(不包括5,没用到歌单),第7条接口是MV的,不过不幸没有发现像专辑一样的列表页信息,它只有单曲的MV的API。
不过这里我们用不上,后面会专门分析API。
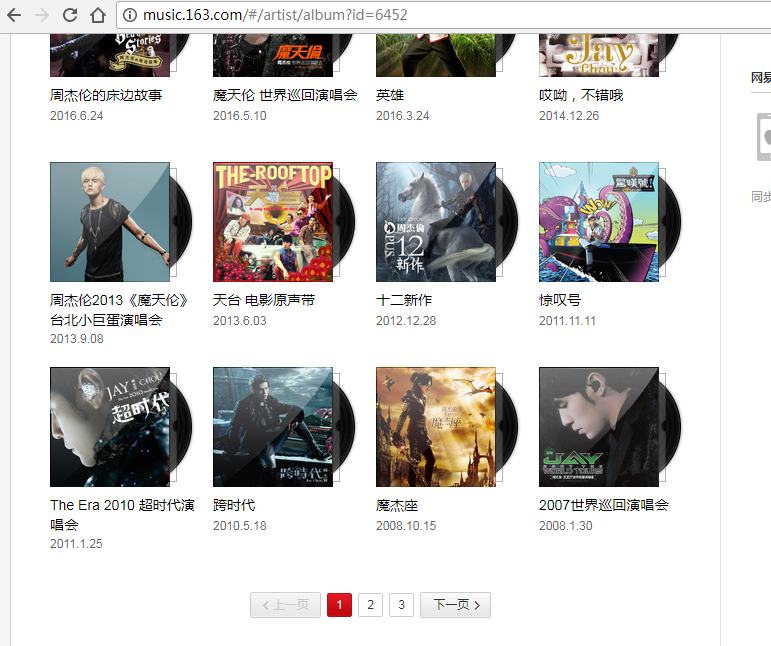
5、接下来就是每个专辑的所有歌曲还有专辑、歌手的一些信息,专辑下也有评论
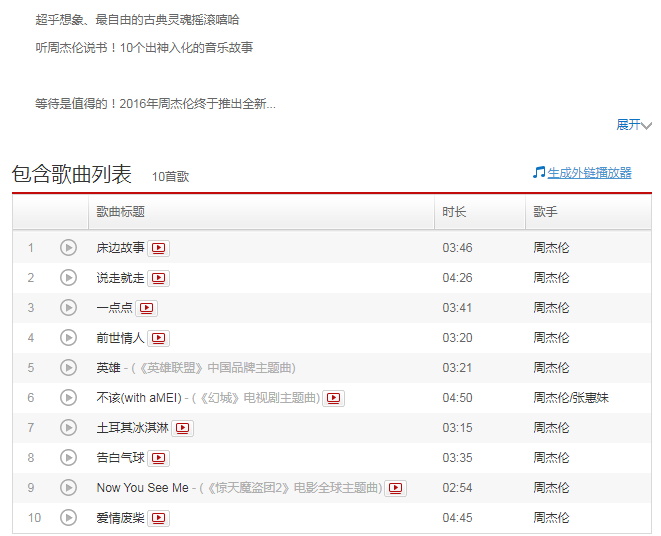
6、最后就是歌曲页了
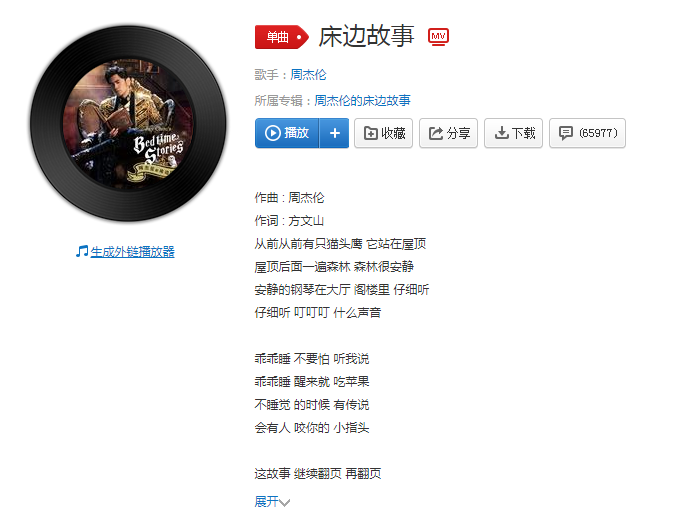
好,思路就是这样,接下来我们分析Scrapy这个框架。
本文来自博客园,作者:苏酒酒,转载请注明原文链接:https://www.cnblogs.com/sujiujiu/p/15371824.html

