正则笔记
一 定义方式(记录文本规则的代码)
1.构造函数
var regEx = new RegExp(/\d/);
2.字面量
var regEx = /\d/;
3.test方法
regEx.test(“a”) 判断a是否符合regEx的标准
二 正则表达中符号的使用
| 或 /foot|boot/ 整体
() 分组,提高权重 /(f|b)oot/
{} 量词,字符出现的次数 /foot{x}/ 只取t,t出现X次
[] 字符的位置,一个[]只表示一个字符位置 /[abc]/
三 字符类型
1.简单类
/abc/ test 检测时,只能多不能少
/[abc]/ test 检测时,只要包含其中一个就为true
2.负向类
/[^abc]/ 取反 test 检测时,只要有不包含abc的字符就为true ^只能写在[ ]里
3.范围类
/[a-z]/ 取值为所有小写字母中的一个字符
4.组合类
/[a-zA-Z0-9]/ 取值为所有小写字母,大写字母,数组 范围可自定义
四 预定义
\d 数字
\w 字母
\s 空白字符
大写字母取反
. 除了回车换行外所有字符(一个字符)
.* 贪婪匹配,最大化返回值 如a.*b a和b之间有多少都可以
五 边界
^ 限制开头 ^X 以X开始
$ 限制结尾 X$ 以X结束
一般正则表达式都有边界 /^ $/
六 量词
* x>=0
+ x>=1
? X=1 || x= 0
a{x} a出现x次
a{x,} a出现x次以上
a{x,y} a出现x到y之间的次数
七 trim函数封装
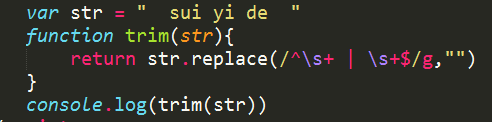
console.log(trim(str)) ---->“sui yi de”
去掉了两边的空格(正则中最好不要加空格)
八 表单验证

不让输入汉字
/^[^\u4e00-\u9fa5]{0,}$/
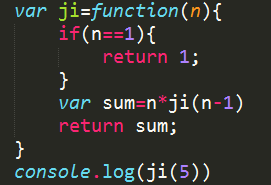
九 递归
求和

求积
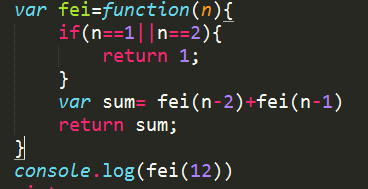
斐波那契数列
十 提取
1.提取第一个数据
正则表达式对象.exec(字符串)----->封装成数组

 浙公网安备 33010602011771号
浙公网安备 33010602011771号