

redis的使用场景和优缺点
使用场景和优缺点:
2 Redis用来做什么?
通常局限点来说,Redis也以消息队列的形式存在,作为内嵌的List存在,满足实时的高并发需求。而通常在一个电商类型的数据处理过程之中,有关商品,热销,推荐排序的队列,通常存放在Redis之中,期间也包扩Storm对于Redis列表的读取和更新。
Redis的优点
性能极高 – Redis能支持超过 100K+ 每秒的读写频率。
丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hash, Sets 及 Ordered Sets 数据类型操作。
原子 – Redis的所有操作都是原子性的,同时Redis还支持对几个操作全并后的原子性执行。
丰富的特性 – Redis还支持 publish/subscribe, 通知, key 过期等等特性。
redis的缺点
是数据库容量受到物理内存的限制,不能用作海量数据的高性能读写,因此Redis适合的场景主要局限在较小数据量的高性能操作和运算上。
总结: Redis受限于特定的场景,专注于特定的领域之下,速度相当之快,目前还未找到能替代使用产品
一、前言
在我们日常的开发中,无不都是使用数据库来进行数据的存储,由于一般的系统任务中通常不会存在高并发的情况,所以这样看起来并没有什么问题,可是一旦涉及大数据量的需求,比如一些商品抢购的情景,或者是主页访问量瞬间较大的时候,单一使用数据库来保存数据的系统会因为面向磁盘,磁盘读/写速度比较慢的问题而存在严重的性能弊端,一瞬间成千上万的请求到来,需要系统在极短的时间内完成成千上万次的读/写操作,这个时候往往不是数据库能够承受的,极其容易造成数据库系统瘫痪,最终导致服务宕机的严重生产问题。
为了克服上述的问题,项目通常会引入NoSQL技术,这是一种基于内存的数据库,并且提供一定的持久化功能。
redis技术就是NoSQL技术中的一种,但是引入redis又有可能出现缓存穿透,缓存击穿,缓存雪崩等问题。本文就对这三种问题进行较深入剖析。
二、初认识
缓存穿透:key对应的数据在数据源并不存在,每次针对此key的请求从缓存获取不到,请求都会到数据源,从而可能压垮数据源,比如对一个不存在的用户id获取用户信息,不论缓存还是数据库都没有,若黑客利用此漏洞进行攻击可能压垮数据库
缓存击穿:key对应的数据存在,但是redis中过期,此时若大量并发请求过来,这些请求缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮
缓存雪崩:当缓存服务器重启或者大量缓存集中在某一个时间段失效,这样在失效的时候,也会对后端系统带来很大压力
三、缓存穿透解决方案
有很多种方法可以有效地解决缓存穿透问题,最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被 这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。另外也有一个更为简单粗暴的方法(我们采用的就是这种),如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。

//伪代码 public object GetProductListNew() { int cacheTime = 30; String cacheKey = "product_list"; String cacheValue = CacheHelper.Get(cacheKey); if (cacheValue != null) { return cacheValue; } cacheValue = CacheHelper.Get(cacheKey); if (cacheValue != null) { return cacheValue; } else { //数据库查询不到,为空 cacheValue = GetProductListFromDB(); if (cacheValue == null) { //如果发现为空,设置个默认值,也缓存起来 cacheValue = string.Empty; } CacheHelper.Add(cacheKey, cacheValue, cacheTime); return cacheValue; } }
四、缓存击穿解决方案
key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑一个问题:缓存被“击穿”的问题。
使用互斥锁(mutex key)
业界比较常用的做法,是使用mutex。简单地来说,就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db,而是先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX或者Memcache的ADD)去set一个mutex key,当操作返回成功时,再进行load db的操作并回设缓存;否则,就重试整个get缓存的方法。
public String get(key) { String value = redis.get(key); if (value == null) { //代表缓存值过期 //设置3min的超时,防止del操作失败的时候,下次缓存过期一直不能load db if (redis.setnx(key_mutex, 1, 3 * 60) == 1) { //代表设置成功 value = db.get(key); redis.set(key, value, expire_secs); redis.del(key_mutex); } else { //这个时候代表同时候的其他线程已经load db并回设到缓存了,这时候重试获取缓存值即可 sleep(50); get(key); //重试 } } else { return value; } }
五、缓存雪崩解决方案
与缓存击穿的区别在于这里针对很多key缓存,前者则是某一个key。
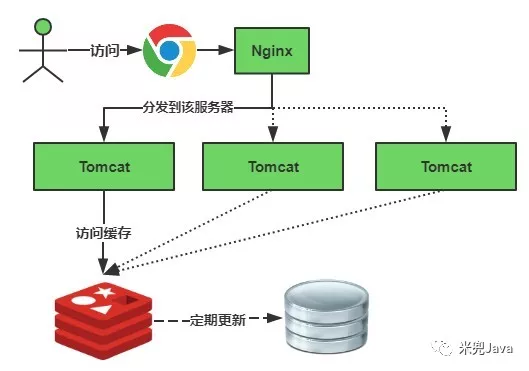
缓存正常从Redis中获取,示意图如下:
缓存失效瞬间示意图如下:
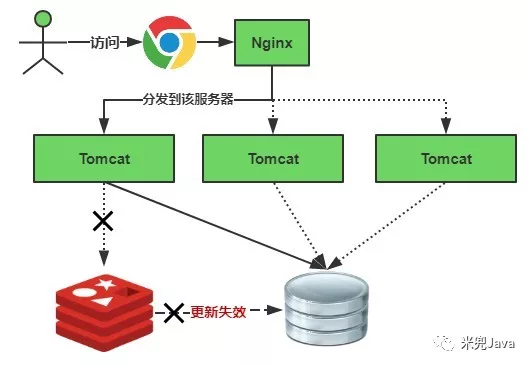
缓存失效时的雪崩效应对底层系统的冲击非常可怕!大多数系统设计者考虑用加锁或者队列的方式保证来保证不会有大量的线程对数据库一次性进行读写,从而避免失效时大量的并发请求落到底层存储系统上。还有一个简单方案就时讲缓存失效时间分散开,比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
关于缓存崩溃的解决方法,这里提出了三种方案:使用锁或队列、设置过期标志更新缓存、为key设置不同的缓存失效时间,还有一种被称为“二级缓存”的解决方法。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix