
Easticsearch概述(ES、Lucene、Solr)一
ES是在Lucene的基础上实现的
1、Lucene全文检索
lucene是一个全文搜索框架,而不是应用产品。因此它并不像http://www.baidu.com/或goolge Destop 那么拿来就用,它只是提供了一种工具让你能实现这些产品
1、lucene能做什么呢
要回答这个问题,先要了解lucene的本质。实际上lucene的功能很单一,说到底,就是你给它若干个字符串,然后它为你提供一个全文搜索服务,告诉你你要搜索的关键词出现在哪里。知道了这个本质,你就可以发挥想象做任何符合这个条件的事情了,,你就可以吧站内新闻都索引了,做个资料库,你可以吧一个数据库表的若干个字段索引起来,那就不用担心因为“%like%”而锁表了;你也可以写个自己的搜索引。。
2、该不该选择lucene
下面给出一些测试数据,如果你觉得可以接受,那么可以接受
测试一:250万记录,300M左右文本,生成索引380M左右,800线程下平均处理时间300ms
测试二:37000记录,索引数据库中的两个varchar字段,索引文件2.6M,800线程下平均处理时间1.5ms
3、倒排索引
正排索引
我是中国人(1)
中国是全球人口最多的国家,中国人也最多
1、我, 是 , 中国 ,中国人
2、中国,是,全球。。。。
倒排索引
1、我 (1:1{0} #第一行出现一次,在第一行中偏移量0
2、中国 (1:1){2},(2:2){0,15} #第一行出现一次,偏移量2,第二行出现2次,偏移量0和15
文章数量和索引数量之间的关系?没关系
document:java instance
使用:
nutch爬虫
solr基于Lucene做的web项目,搜索引擎
数据存储:hadoop
数据计算:MapReduce
数据的随机存储:HBase
ElasticSearch介绍:
ElasticSearch是一个基于Lucene的实时的分布式搜索和分析引擎。设计用于云计算中,能够达到近实时搜索,稳定,可靠,快速,安装使用方便。基于RESTFUL接口
ElasticSearch VS Solr总结
1、ES基本是开箱即用,非常简单。solr安装比较哦复杂
2、Solr利用Zookeeper进行分布式管理,而ES自身带有分布式协调管理功能
3、Solr支持数据格式:JSON、XML、CSV,而ES仅支持json文件格式
4、Solr官方提供的功能很多,而ES本身更注重于狠心功能,高级功能多有第三方插件提供,例如图形化界面需要kibana友好支撑
5、Solr查询快,但更新索引时慢(即插入删除慢),用于电商等查询多的应用;ES建立索引快(即查询慢),即实时性查询快,用于facebook、GitHub、新浪等搜索
6、Solr是传统搜索应用的有力解决方案,但ES更适用于新兴的大数据实时搜索应用
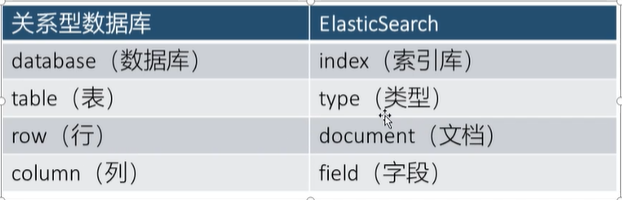
ES和关系型数据库对比
ES的优点
1、分布式:ES的自动发现机制会识别新增的节点并重新平衡分配数据
2、全文检索:ES后台使用Lucene提供全文检索,自带多语言支持、强大的查询语言、地理位置支持、上下文感知的建议、自动完成和搜索片段
3、近实时搜索和分析:数据从进入ES到能够搜索到是近实时的,除了搜索,ES也可以进行聚合分析操作
4、高可用:ES会自动发现新的或失败的节点,重组和重新平衡数据,确保数据是安全和可访问的
5、模式自由:ES的动态Mapping机制可以自动检测数据的结构和类型,创建索引,并使数据可搜索
6、RESTFUL API:几乎任何操作都可以使用一个简单的Restful API,JSON基于HTTP请求来实现,客户端也可以使用多种编程语言
ES应用场景:
站内搜索:Facebook、新浪微博、论坛等的站内搜索
NoSQl数据库:ES读写性能优于MongoDB,同时也支持地理位置查询
日志分析:日志分析由实时日志分析平台ELK完成,能够对日志进行集中的收集、存储、搜索、分析、监控以及可视化
ES的单机模式架构原理图:
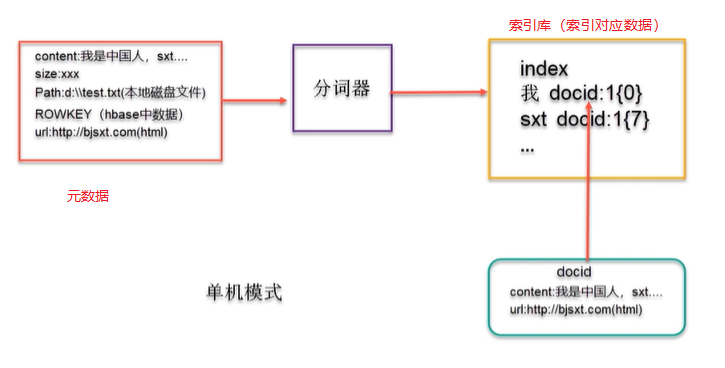
在单台ES服务器节点上,随着业务量的发张索引文件慢慢增多,会影响效率和内存存储问题等
可以采用ES集群,将单个索引的分片到多个不同分布式物理机器上存储,从而可以实现高可用、容错性等
ES集群中索引可能由多个分片构成,并且每个分片可以拥有多个副本,通过将一个单独的索引分为多个分片,我们可以处理不在一个单一的服务器上面运行的大型索引,简单的说就是索引的大小过大,导致效率问题。不能运行的原因可能是内存也可能是存储。由于每个分片可以有多个副本,通过将副本分配到多个服务器,可以提高查询的负载能力
ES集群架构图:
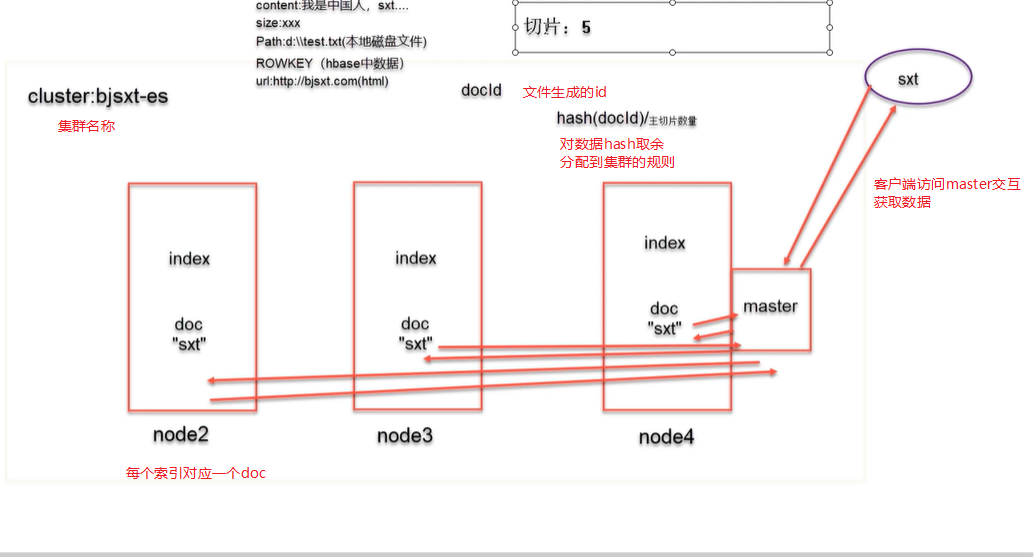
ES集群中的名词:
Cluster
代表一个集群,集群中有多个节点,其中有一个为主节点,这个主节点,这个结案是可以通过选举产生的,主从节点是对于集群内部来说。ES的一个概念就是去中心化,字面上理解就是务中心节点,这是对于集群外部来说的,因为从外部来看es集群,在逻辑上时个整体,你与任何一个节点的通信和与整个ES集群通信时等价的
Shards
代表索引分片,es可以吧一个完整的索引分成多个分片,这样的好处是可以吧一个大的索引分成多个,分布到不同的节点上。构成分布式搜索。分片的数量只能在索引创建前指定,并且索引创建后不能更改
replicas
代表索引副本,es可以设置多个索引的副本,副本的作用一是提高系统容错性,当某个节点某个分片损坏或丢失时可以从副本中恢复,二十提高es的查询效率,es会自动对索引请求进行负载均衡
Recovery
代表数据恢复或数据重新分布。es在有节点假如或退出时会根据机器的负载均衡对索引分片进行重新分配,挂掉的节点重新启动时也会进行数据恢复

