

Prometheus+Alertmanager企业微信告警
目前环境:目前我们产线和测试环境使用的基于数人云+Mesos+marathon的PAAS平台,平台使用consul作为服务发现,cadvisor收集容器及虚拟机性能数据,prometheus+altermanager用来监控这套PAAS平台。
需求:prometheus+altermanager实现企业微信告警
问题点:目前由于数人云被收购,我们公司正在进行openshift poc,把数人云迁移到openshift平台(需要一年左右时间),而原数人云平台一些插件版本低,不满足我们的需求。altermanager从0.12版本开始支持企业微信告警,这次我们需要把altermanager从0.4.2迁移升级到0.20,以实现企业微信告警。
原数人云环境所有插件都是基于容器部署,这次还是基于容器部署altermanager0.20,而prometheus不动。
一、环境信息:
prometheus数据保存路径:/data/prometheus
prometheus配置文件保存路径:/data/config/prometheus
alertmanager配置文件保存路径:/data/config/alertmanager
~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
bd9e9ca66c16 offlineregistry.dataman-inc.com:5000/library/centos7-docker-prometheus:v1.1.2.2016091302 "/prometheus-1.1.2.li" 19 hours ago Up 15 hours dataman-monitor-prometheus
fe684f6a4340 offlineregistry.dataman-inc.com:5000/library/centos7-docker-alertmanager:v0.4.2.2016102502 "/alertmanager -stora" 7 days ago UP 7 days dataman-monitor-alertmanage
9d1f4d0d34a4 offlineregistry.dataman-inc.com:5000/library/centos7-docker-consul:v0.7.0.2016092302 "/consul agent -data-" 7 days ago Up 7 days dataman-consul-slave
4a64927b6814 offlineregistry.dataman-inc.com:5000/library/centos7-docker-consul-exporter:v0.2.0.2016112302 "/consul_exporter -co" 7 days ago Up 7 days dataman-monitor-consul-exporter
2bfaa5ee7da9 offlineregistry.dataman-inc.com:5000/library/centos7-docker-grafana:v3.1.1.2016112502 "/usr/sbin/grafana-se" 7 days ago Up 7 days dataman-monitor-grafana
61a1239d0715 offlineregistry.dataman-inc.com:5000/library/centos7-docker-cadvisor:v0.23.8.2016091302 "/cadvisor --port=501" 7 days ago Up 7 days dataman-cadvisor
二、docker部署prometheus
(1) Prometheus安装
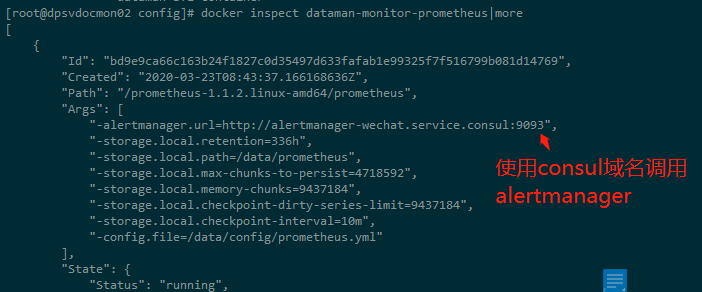
docker run -d \
--log-driver=json-file \
--name dataman-monitor-prometheus --net host --restart always \
-v /data/prometheus:/data/prometheus \
-v /data/config/prometheus:/data/config \
$DNS_OPS \ #三台consul master端
centos7-docker-prometheus:v1.1.2.2016091302 \
-alertmanager.url=http://alertmanager-wechat.service.consul:9093 \ #此处修改过,以防止和现有使用冲突,需要重新向consul注册,不然prometheus无法把告警发给alertmanager。
-storage.local.retention=336h \
-storage.local.path=/data/prometheus \
-storage.local.max-chunks-to-persist=4718592 \
-storage.local.memory-chunks=9437184 \
-storage.local.checkpoint-dirty-series-limit=9437184 \
-storage.local.checkpoint-interval=10m \
-config.file=/data/config/prometheus.yml
#向consul注册
~]# curl -L -X PUT -d '{"id":"alertmanager-vip-10.159.54.41" ,"name": "alertmanager-wechat", "tags": [""], "port": 9093,"check": {"http": "http://10.159.54.41:9093/api/v1/alerts", "interval": "10s","timeout": "1s"}}' 10.159.54.41:8500/v1/agent/service/register
~]# dig @10.159.52.22 alertmanager-wechat.service.consul
alertmanager-wechat.service.consul. 0 IN A 10.159.54.41
#10.158.52.22是consul master端
(2) 查看prometheus配置文件
~]# cat /data/config/prometheus/prometheus.yml
global:
scrape_interval: 15s # By default, scrape targets every 15 second.
evaluation_interval: 15s # By default, scrape targets every 15 seconds.
# scrape_timeout is set to the global default (10s).
# Attach these extra labels to all time-series collected by this Prometheus instance.
labels:
monitor: 'dataman-monitor'
# A scrape configuration containing exactly one endpoint to scrape:
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
# Dataman
- job_name: 'cadvisor'
# Override the global default and scrape targets from this job every 5 seconds.
scrape_interval: 15s
scrape_timeout: 5s
consul_sd_configs:
- server: 'consul.service.consul:8500'
services: ['cadvisor']
relabel_configs:
- source_labels: ["__meta_consul_node"]
regex: "(^dpsvdoc|dpsvebf).*"
action: keep
- job_name: 'prometheus'
# Override the global default and scrape targets from this job every 5 seconds.
scrape_interval: 10s
scrape_timeout: 5s
consul_sd_configs:
- server: 'consul.service.consul:8500'
services: ['prometheus']
- job_name: 'alertmanager'
# Override the global default and scrape targets from this job every 5 seconds.
scrape_interval: 10s
scrape_timeout: 5s
consul_sd_configs:
- server: 'consul.service.consul:8500'
services: ['alertmanager']
- job_name: 'app_layer_metrics'
scrape_interval: 15s
scrape_timeout: 5s
metrics_path: /prometheus
consul_sd_configs:
- server: 'consul.service.consul:8500'
services: ['stage-sephora-myaccount-service','stage-sephora-product-service']
relabel_configs:
- source_labels: ["__meta_consul_service"]
target_label: "app_name"
- job_name: 'consul' #单独使用consul-export监控
# Override the global default and scrape targets from this job every 5 seconds.
scrape_interval: 10s
scrape_timeout: 5s
static_configs:
- targets: ['10.159.54.41:9107']
- job_name: 'ebf_redis_exporter'
scrape_interval: 15s
scrape_timeout: 5s
static_configs:
- targets: ['10.159.54.248:9121']
labels: {'alias': '10.159.54.248'}
- targets: ['10.159.54.44:9121']
labels: {'alias': '10.159.54.44'}
- job_name: 'ceph_exporter'
scrape_interval: 15s
scrape_timeout: 10s
static_configs:
- targets: ['10.159.54.134:9128']
rule_files:
- '/data/config/alert.rules'
- '/data/config/prometheus.rules'
~]# cat /data/config/prometheus/prometheus.rules
#cpu
job_cadvisor:docker_by_cpu:container_cpu_usage_seconds_total:avg_rate1m = avg(rate(container_cpu_usage_seconds_total{id=~"/docker/.*"}[1m])) by (name,instance) *100
job_cadvisor:system_by_cpu:container_cpu_usage_seconds_total:sum_rate1m = sum(rate(container_cpu_usage_seconds_total{id="/"}[1m])) by (instance,cpu) *100
job_cadvisor:system_by_cpu_all:container_cpu_usage_seconds_total:avg_rate1m = avg(job_cadvisor:system_by_cpu:container_cpu_usage_seconds_total:sum_rate1m) by (instance)
job_cadvisor:system_by_cup_system:container_cpu_system_seconds_total:sum_rate1m:machine_cpu_cores = sum(rate(container_cpu_system_seconds_total{id="/"}[1m]) / on(instance) group_left machine_cpu_cores) by (instance) *100
job_cadvisor:system_by_cpu_user:container_cpu_user_seconds_total:sum_rate1m:machine_cpu_cores = sum(rate(container_cpu_user_seconds_total{id="/"}[1m]) / on(instance) group_left machine_cpu_cores) by (instance) *100
#mem
job_cadvisor:dataman_memory_usage_percent:container_memory_usage_bytes:sum:machine_memory_bytes = sum(container_memory_usage_bytes{id=~"/docker/.*", name=~"dataman.*"} / on(instance) group_left machine_memory_bytes) by (name,instance)*100
job_cadvisor:system_memory_usage_percent:container_memory_usage_byte:sum:machine_memory_bytes = sum(container_memory_usage_bytes{id="/"} / on(instance) group_left machine_memory_bytes) by (instance) *100
#fs
job_cadvisor:system_fs_usage_percent:container_fs_usage_bytes:sum:container_fs_limit_bytes = sum (container_fs_usage_bytes{image="",device!="overlay"}/container_fs_limit_bytes{image="",device!="overlay"}) by (instance,device) *100
#network
job_cadvisor:system_network:container_network_receive_bytes_total:sum_rate1m = sum(rate(container_network_receive_bytes_total{id="/"}[1m])) by (interface,instance)*8
job_cadvisor:system_network:container_network_transmit_bytes_total:sum_rate1m = sum(rate(container_network_transmit_bytes_total{id="/"}[1m])) by (interface,instance)*8
job_cadvisor:system_network:container_network_receive_packets_total:sum_rate1m = sum(rate(container_network_receive_packets_total{id="/"}[1m])) by (interface,instance)
job_cadvisor:system_network:container_network_transmit_packets_total:sum_rate1m = sum(rate(container_network_transmit_packets_total{id="/"}[1m])) by (interface,instance)
~]# cat /data/config/prometheus/alert.rules
ALERT DatamanServiceDown
IF consul_catalog_service_node_healthy{service!="mysql-vip",service!="alertmanager-vip", service!~"qa1.*", service!~"qa2.*", service!~"ebf.*"} == 0
FOR 1m
LABELS { severity = "Critical", owner="infra_team"}
ANNOTATIONS {
summary = "DatamanService {{ $labels.service }} down",
description = "{{ $labels.service }} of node {{ $labels.node }} has been down for more than 1 minutes.",
}
ALERT ConsulAgentDown
IF consul_agent_check == 0
FOR 1m
LABELS { severity = "Critical", owner="infra_team"}
ANNOTATIONS {
summary = "ConsulAgent {{ $labels.node }} down",
description = "{{ $labels.node }} of job {{ $labels.job }} has been down for more than 1 minutes.",
}
ALERT ConsulClusterConnectionFailed
IF consul_up == 0
FOR 1m
LABELS { severity = "Critical", owner="infra_team" }
ANNOTATIONS {
summary = "ConsulExporter {{ $labels.instance }} Connection ConsulCluster Failed",
description = "{{ $labels.instance }} of job {{ $labels.job }} has been connection consulcluster failed for more than 1 minutes.",
}
ALERT LogKeyword
IF ceil(increase(log_keyword{id=~'.*'}[2m])) > 3
FOR 1m
LABELS { severity = "Warning", owner="infra_team"}
ANNOTATIONS {
summary = "Application {{ $labels.appid }} taskid {{ $labels.taskid }} Log key word filter {{ $labels.keyword }} trigger times {{ $value }}",
description = "Application {{ $labels.appid }} taskid {{ $labels.taskid }} Log keyword filter {{ $labels.keyword }} trigger times {{ $value }}",
}
######## sephora rules #########
ALERT sephora_rabbitmq_service_down
IF rabbitmq_up == 0
LABELS { severity = "Critical", service = "rabbitmq", owner="middleware_team"}
ANNOTATIONS {
summary = "Rabbitmq service is down",
description = "Rabbitmq is down on host {{$labels.alias}}, please check ASAP",
}
ALERT ceph_space_usage
IF ceil((ceph_cluster_used_bytes / ceph_cluster_capacity_bytes)*100) > 80
FOR 15s
LABELS { severity = "Critical", service = "ceph", owner="infra_team" }
ANNOTATIONS {
summary = "Ceph集群空间不足",
description = "Ceph当前空间使用率为{{ $value }}",
}
浏览器访问http://ip:9090端口测试
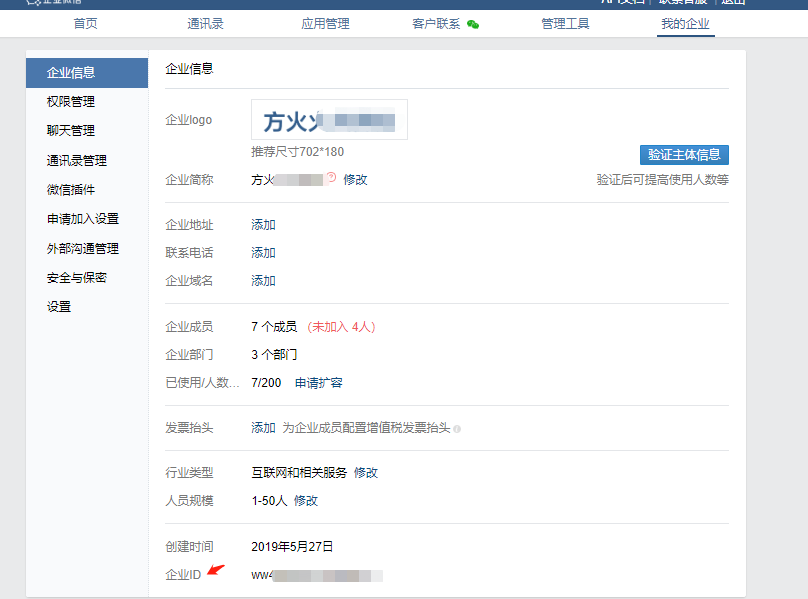
二、准备企业微信:
(1) 企业微信创建自定义应用
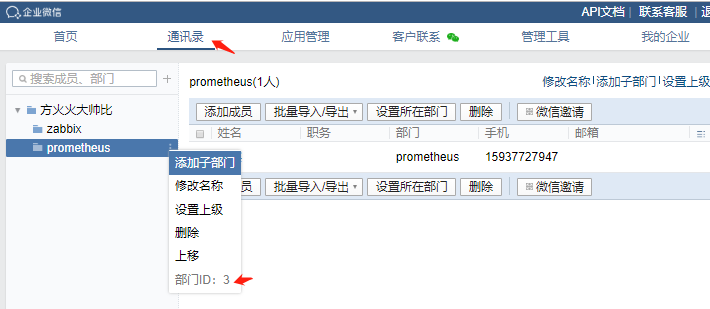
(2) 获取相关信息

三、迁移alertmanager
- 停掉当前altermanager
~]# docker stop dataman-monitor-alertmanager
~]# rm -rf /data/alertmanager/*
2.部署alertmanager 0.20版本
~]# docker login docker.io
~]# docker pull prom/alertmanager:latest
~]# cat /data/config/alertmanager/alertmanager.yml
global:
smtp_smarthost: '10.159.54.*:25'
smtp_from: 'soa_stage_alert@sephora.cn'
resolve_timeout: 5m
route:
group_by: ['alertname']
group_wait: 30s
group_interval: 1m
repeat_interval: 10m
receiver: 'infra_team'
routes:
- match_re:
alertname: sephora_.*
receiver: infra_team
- match_re:
container_label_APP_ID: ^$
receiver: infra_team
inhibit_rules:
- source_match:
severity: 'Critical'
target_match:
severity: 'Warning'
equal: ['instance']
templates:
- '/data/config/wechat.message'
receivers:
- name: 'infra_team'
email_configs:
- to: 'rluo@ext.sephora.cn'
require_tls: false
wechat_configs:
- corp_id: 'ww4b5a8c6c18be6610' #企业ID
to_party: '1' #部门ID
agent_id: '1000001' #agentID
api_secret: 'OJFbZWQvVMHIvWxMkWqA_16MpPpVNsoSBpnm5HCbbfc' #Api证书
send_resolved: true #告警恢复是是否通知
~]# cat /data/config/alertmanager/wechat.message
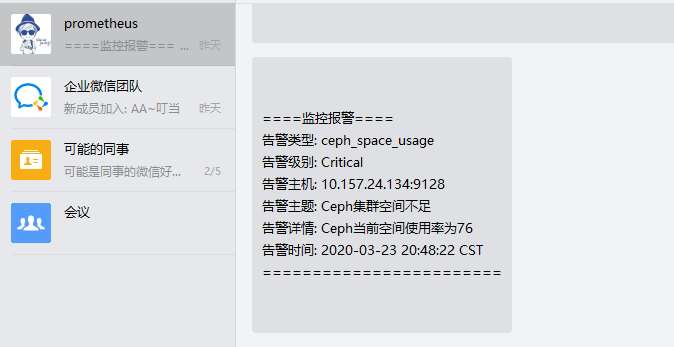
{{ define "wechat.default.message" }} #定义企业微信告警默认模板
{{ range .Alerts }}
====监控报警====
告警类型: {{ .Labels.alertname }}
告警级别: {{ .Labels.severity }} #对应prometheus配置文件alert.rules中定义的LABELS
告警主机: {{ .Labels.instance }}
告警主题: {{ .Annotations.summary }} #对应prometheus配置文件alert.rules中定义的ANNOTATIONS
告警详情: {{ .Annotations.description }}
告警时间: {{ .StartsAt.Format "2006-01-02 15:04:05" }} CST #格式化时间
========================
{{ end }}
{{ end }}
~]# cat deploy_alertmanager.sh
docker run -d \
--name alertmanager_test2 \
--log-driver=json-file --net host --restart always \
-v /data/alertmanager_v2:/data/alertmanager \
-v /data/config/alertmanager:/data/config \
prom/alertmanager:latest \
--storage.path=/data/alertmanager \
--config.file=/data/config/alertmanager.yml
~]# docker ps #确认容器启动,alertmanager 9093端口监听
可以浏览器访问http://10.157.27.41:9093查看
查看告警
手动修改prometheus的alert.rules的告警阀值,重启prometheus,让其产生告警,如下


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)