python基础之数据类型及内置方法
一 数字类型int与float
1.1 定义
# 1.1 整型int的定义
age=10 # 本质age = int(10)
# 1.2 浮点型float的定义
salary=3000.3 # 本质salary=float(3000.3)
# 注意:名字+括号的意思就是调用某个功能,比如
# print(...)调用打印功能
# int(...)调用创建整型数据的功能
# float(...)调用创建浮点型数据的功能
1.2 类型转换
# 1、数据类型转换
# 1.1 int可以将由纯整数构成的字符串直接转换成整型,若包含其他任意非整数符号,则会报错
>>> s = '123'
>>> res = int(s)
>>> res,type(res)
(123, <class 'int'>)
>>> int('12.3') # 错误演示:字符串内包含了非整数符号.
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: invalid literal for int() with base 10: '12.3'
# 1.2 进制转换
# 十进制转其他进制
>>> bin(3)
'0b11'
>>> oct(9)
'0o11'
>>> hex(17)
'0x11'
# 其他进制转十进制
>>> int('0b11',2)
3
>>> int('0o11',8)
9
>>> int('0x11',16)
17
# 1.3 float同样可以用来做数据类型的转换
>>> s = '12.3'
>>> res=float(s)
>>> res,type(res)
(12.3, <class 'float'>)
1.3 使用
数字类型主要就是用来做数学运算与比较运算,因此数字类型除了与运算符结合使用之外,并无需要掌握的内置方法
二 字符串
2.1 定义:
# 定义:在单引号\双引号\三引号内包含一串字符
name1 = 'jason' # 本质:name = str('任意形式内容')
name2 = "lili" # 本质:name = str("任意形式内容")
name3 = """ricky""" # 本质:name = str("""任意形式内容""")
2.2 类型转换
# 数据类型转换:str()可以将任意数据类型转换成字符串类型,例如
>>> type(str([1,2,3])) # list->str
<class 'str'>
>>> type(str({"name":"jason","age":18})) # dict->str
<class 'str'>
>>> type(str((1,2,3))) # tuple->str
<class 'str'>
>>> type(str({1,2,3,4})) # set->str
<class 'str'>
2.3 使用
2.3.1 优先掌握的操作
>>> str1 = 'hello python!'
# 1.按索引取值(正向取,反向取):
# 1.1 正向取(从左往右)
>>> str1[6]
p
# 1.2 反向取(负号表示从右往左)
>>> str1[-4]
h
# 1.3 对于str来说,只能按照索引取值,不能改
>>> str1[0]='H' # 报错TypeError
# 2.切片(顾头不顾尾,步长)
# 2.1 顾头不顾尾:取出索引为0到8的所有字符
>>> str1[0:9]
hello pyt
# 2.2 步长:0:9:2,第三个参数2代表步长,会从0开始,每次累加一个2即可,所以会取出索引0、2、4、6、8的字符
>>> str1[0:9:2]
hlopt
# 2.3 反向切片
>>> str1[::-1] # -1表示从右往左依次取值
!nohtyp olleh
# 3.长度len
# 3.1 获取字符串的长度,即字符的个数,但凡存在于引号内的都算作字符)
>>> len(str1) # 空格也算字符
13
# 4.成员运算 in 和 not in
# 4.1 int:判断hello 是否在 str1里面
>>> 'hello' in str1
True
# 4.2 not in:判断tony 是否不在 str1里面
>>> 'tony' not in str1
True
# 5.strip移除字符串首尾指定的字符(默认移除空格)
# 5.1 括号内不指定字符,默认移除首尾空白字符(空格、\n、\t)
>>> str1 = ' life is short! '
>>> str1.strip()
life is short!
# 5.2 括号内指定字符,移除首尾指定的字符
>>> str2 = '**tony**'
>>> str2.strip('*')
tony
# 6.切分split
# 6.1 括号内不指定字符,默认以空格作为切分符号
>>> str3='hello world'
>>> str3.split()
['hello', 'world']
# 6.2 括号内指定分隔字符,则按照括号内指定的字符切割字符串
>>> str4 = '127.0.0.1'
>>> str4.split('.')
['127', '0', '0', '1'] # 注意:split切割得到的结果是列表数据类型
# 7.循环
>>> str5 = '今天你好吗?'
>>> for line in str5: # 依次取出字符串中每一个字符
... print(line)
...
今
天
你
好
吗
?
2.3.2 需要掌握的操作
1.strip, lstrip, rstrip
>>> str1 = '**tony***'
>>> str1.strip('*') # 移除左右两边的指定字符
'tony'
>>> str1.lstrip('*') # 只移除左边的指定字符
tony***
>>> str1.rstrip('*') # 只移除右边的指定字符
**tony
2.lower(),upper()
>>> str2 = 'My nAme is tonY!'
>>> str2.lower() # 将英文字符串全部变小写
my name is tony!
>>> str2.upper() # 将英文字符串全部变大写
MY NAME IS TONY!
3.startswith,endswith
>>> str3 = 'tony jam'
# startswith()判断字符串是否以括号内指定的字符开头,结果为布尔值True或False
>>> str3.startswith('t')
True
>>> str3.startswith('j')
False
# endswith()判断字符串是否以括号内指定的字符结尾,结果为布尔值True或False
>>> str3.endswith('jam')
True
>>> str3.endswith('tony')
False
4.格式化输出之format
之前我们使用%s来做字符串的格式化输出操作,在传值时,必须严格按照位置与%s一一对应,而字符串的内置方法format则提供了一种不依赖位置的传值方式
案例:
# format括号内在传参数时完全可以打乱顺序,但仍然能指名道姓地为指定的参数传值,name=‘tony’就是传给{name}
>>> str4 = 'my name is {name}, my age is {age}!'.format(age=18,name='tony')
>>> str4
'my name is tony, my age is 18!'
>>> str4 = 'my name is {name}{name}{name}, my age is {name}!'.format(name='tony', age=18)
>>> str4
'my name is tonytonytony, my age is tony!'
format的其他使用方式(了解)
# 类似于%s的用法,传入的值会按照位置与{}一一对应
>>> str4 = 'my name is {}, my age is {}!'.format('tony', 18)
>>> str4
my name is tony, my age is 18!
# 把format传入的多个值当作一个列表,然后用{索引}取值
>>> str4 = 'my name is {0}, my age is {1}!'.format('tony', 18)
>>> str4
my name is tony, my age is 18!
>>> str4 = 'my name is {1}, my age is {0}!'.format('tony', 18)
>>> str4
my name is 18, my age is tony!
>>> str4 = 'my name is {1}, my age is {1}!'.format('tony', 18)
>>> str4
my name is 18, my age is 18!
5.split,rsplit
# split会按照从左到右的顺序对字符串进行切分,可以指定切割次数
>>> str5='C:/a/b/c/d.txt'
>>> str5.split('/',1)
['C:', 'a/b/c/d.txt']
# rsplit刚好与split相反,从右往左切割,可以指定切割次数
>>> str5='a|b|c'
>>> str5.rsplit('|',1)
['a|b', 'c']
6.join
# 从可迭代对象中取出多个字符串,然后按照指定的分隔符进行拼接,拼接的结果为字符串
>>> '%'.join('hello') # 从字符串'hello'中取出多个字符串,然后按照%作为分隔符号进行拼接
'h%e%l%l%o'
>>> '|'.join(['tony','18','read']) # 从列表中取出多个字符串,然后按照*作为分隔符号进行拼接
'tony|18|read'
7.replace
# 用新的字符替换字符串中旧的字符
>>> str7 = 'my name is tony, my age is 18!' # 将tony的年龄由18岁改成73岁
>>> str7 = str7.replace('18', '73') # 语法:replace('旧内容', '新内容')
>>> str7
my name is tony, my age is 73!
# 可以指定修改的个数
>>> str7 = 'my name is tony, my age is 18!'
>>> str7 = str7.replace('my', 'MY',1) # 只把一个my改为MY
>>> str7
'MY name is tony, my age is 18!'
8.isdigit
# 判断字符串是否是纯数字组成,返回结果为True或False
>>> str8 = '5201314'
>>> str8.isdigit()
True
>>> str8 = '123g123'
>>> str8.isdigit()
False
2.3.3 了解操作
# 1.find,rfind,index,rindex,count
# 1.1 find:从指定范围内查找子字符串的起始索引,找得到则返回数字1,找不到则返回-1
>>> msg='tony say hello'
>>> msg.find('o',1,3) # 在索引为1和2(顾头不顾尾)的字符中查找字符o的索引
1
# 1.2 index:同find,但在找不到时会报错
>>> msg.index('e',2,4) # 报错ValueError
# 1.3 rfind与rindex:略
# 1.4 count:统计字符串在大字符串中出现的次数
>>> msg = "hello everyone"
>>> msg.count('e') # 统计字符串e出现的次数
4
>>> msg.count('e',1,6) # 字符串e在索引1~5范围内出现的次数
1
# 2.center,ljust,rjust,zfill
>>> name='tony'
>>> name.center(30,'-') # 总宽度为30,字符串居中显示,不够用-填充
-------------tony-------------
>>> name.ljust(30,'*') # 总宽度为30,字符串左对齐显示,不够用*填充
tony**************************
>>> name.rjust(30,'*') # 总宽度为30,字符串右对齐显示,不够用*填充
**************************tony
>>> name.zfill(50) # 总宽度为50,字符串右对齐显示,不够用0填充
0000000000000000000000000000000000000000000000tony
# 3.expandtabs
>>> name = 'tony\thello' # \t表示制表符(tab键)
>>> name
tony hello
>>> name.expandtabs(1) # 修改\t制表符代表的空格数
tony hello
# 4.captalize,swapcase,title
# 4.1 captalize:首字母大写
>>> message = 'hello everyone nice to meet you!'
>>> message.capitalize()
Hello everyone nice to meet you!
# 4.2 swapcase:大小写翻转
>>> message1 = 'Hi girl, I want make friends with you!'
>>> message1.swapcase()
hI GIRL, i WANT MAKE FRIENDS WITH YOU!
#4.3 title:每个单词的首字母大写
>>> msg = 'dear my friend i miss you very much'
>>> msg.title()
Dear My Friend I Miss You Very Much
# 5.is数字系列
#在python3中
num1 = b'4' #bytes
num2 = u'4' #unicode,python3中无需加u就是unicode
num3 = '四' #中文数字
num4 = 'Ⅳ' #罗马数字
#isdigt:bytes,unicode
>>> num1.isdigit()
True
>>> num2.isdigit()
True
>>> num3.isdigit()
False
>>> num4.isdigit()
False
#isdecimal:uncicode(bytes类型无isdecimal方法)
>>> num2.isdecimal()
True
>>> num3.isdecimal()
False
>>> num4.isdecimal()
False
#isnumberic:unicode,中文数字,罗马数字(bytes类型无isnumberic方法)
>>> num2.isnumeric()
True
>>> num3.isnumeric()
True
>>> num4.isnumeric()
True
# 三者不能判断浮点数
>>> num5 = '4.3'
>>> num5.isdigit()
False
>>> num5.isdecimal()
False
>>> num5.isnumeric()
False
'''
总结:
最常用的是isdigit,可以判断bytes和unicode类型,这也是最常见的数字应用场景
如果要判断中文数字或罗马数字,则需要用到isnumeric。
'''
# 6.is其他
>>> name = 'tony123'
>>> name.isalnum() #字符串中既可以包含数字也可以包含字母
True
>>> name.isalpha() #字符串中只包含字母
False
>>> name.isidentifier()
True
>>> name.islower() # 字符串是否是纯小写
True
>>> name.isupper() # 字符串是否是纯大写
False
>>> name.isspace() # 字符串是否全是空格
False
>>> name.istitle() # 字符串中的单词首字母是否都是大写
False
三 列表
3.1 定义
# 定义:在[]内,用逗号分隔开多个任意数据类型的值
l1 = [1,'a',[1,2]] # 本质:l1 = list([1,'a',[1,2]])
3.2 类型转换
# 但凡能被for循环遍历的数据类型都可以传给list()转换成列表类型,list()会跟for循环一样遍历出数据类型中包含的每一个元素然后放到列表中
>>> list('wdad') # 结果:['w', 'd', 'a', 'd']
>>> list([1,2,3]) # 结果:[1, 2, 3]
>>> list({"name":"jason","age":18}) #结果:['name', 'age']
>>> list((1,2,3)) # 结果:[1, 2, 3]
>>> list({1,2,3,4}) # 结果:[1, 2, 3, 4]
3.3 使用
3.3.1 优先掌握的操作
# 1.按索引存取值(正向存取+反向存取):即可存也可以取
# 1.1 正向取(从左往右)
>>> my_friends=['tony','jason','tom',4,5]
>>> my_friends[0]
tony
# 1.2 反向取(负号表示从右往左)
>>> my_friends[-1]
5
# 1.3 对于list来说,既可以按照索引取值,又可以按照索引修改指定位置的值,但如果索引不存在则报错
>>> my_friends = ['tony','jack','jason',4,5]
>>> my_friends[1] = 'martthow'
>>> my_friends
['tony', 'martthow', 'jason', 4, 5]
# 2.切片(顾头不顾尾,步长)
# 2.1 顾头不顾尾:取出索引为0到3的元素
>>> my_friends[0:4]
['tony', 'jason', 'tom', 4]
# 2.2 步长:0:4:2,第三个参数2代表步长,会从0开始,每次累加一个2即可,所以会取出索引0、2的元素
>>> my_friends[0:4:2]
['tony', 'tom']
# 3.长度
>>> len(my_friends)
5
# 4.成员运算in和not in
>>> 'tony' in my_friends
True
>>> 'xxx' not in my_friends
True
# 5.添加
# 5.1 append()列表尾部追加元素
>>> l1 = ['a','b','c']
>>> l1.append('d')
>>> l1
['a', 'b', 'c', 'd']
# 5.2 extend()一次性在列表尾部添加多个元素
>>> l1.extend(['a','b','c'])
>>> l1
['a', 'b', 'c', 'd', 'a', 'b', 'c']
# 5.3 insert()在指定位置插入元素
>>> l1.insert(0,"first") # 0表示按索引位置插值
>>> l1
['first', 'a', 'b', 'c', 'alisa', 'a', 'b', 'c']
# 6.删除
# 6.1 del
>>> l = [11,22,33,44]
>>> del l[2] # 删除索引为2的元素
>>> l
[11,22,44]
# 6.2 pop()默认删除列表最后一个元素,并将删除的值返回,括号内可以通过加索引值来指定删除元素
>>> l = [11,22,33,22,44]
>>> res=l.pop()
>>> res
44
>>> res=l.pop(1)
>>> res
22
# 6.3 remove()括号内指名道姓表示要删除哪个元素,没有返回值
>>> l = [11,22,33,22,44]
>>> res=l.remove(22) # 从左往右查找第一个括号内需要删除的元素
>>> print(res)
None
# 7.reverse()颠倒列表内元素顺序
>>> l = [11,22,33,44]
>>> l.reverse()
>>> l
[44,33,22,11]
# 8.sort()给列表内所有元素排序
# 8.1 排序时列表元素之间必须是相同数据类型,不可混搭,否则报错
>>> l = [11,22,3,42,7,55]
>>> l.sort()
>>> l
[3, 7, 11, 22, 42, 55] # 默认从小到大排序
>>> l = [11,22,3,42,7,55]
>>> l.sort(reverse=True) # reverse用来指定是否跌倒排序,默认为False
>>> l
[55, 42, 22, 11, 7, 3]
# 8.2 了解知识:
# 我们常用的数字类型直接比较大小,但其实,字符串、列表等都可以比较大小,原理相同:都是依次比较对应位置的元素的大小,如果分出大小,则无需比较下一个元素,比如
>>> l1=[1,2,3]
>>> l2=[2,]
>>> l2 > l1
True
# 字符之间的大小取决于它们在ASCII表中的先后顺序,越往后越大
>>> s1='abc'
>>> s2='az'
>>> s2 > s1 # s1与s2的第一个字符没有分出胜负,但第二个字符'z'>'b',所以s2>s1成立
True
# 所以我们也可以对下面这个列表排序
>>> l = ['A','z','adjk','hello','hea']
>>> l.sort()
>>> l
['A', 'adjk', 'hea', 'hello','z']
# 9.循环
# 循环遍历my_friends列表里面的值
for line in my_friends:
print(line)
'tony'
'jack'
'jason'
4
5
3.3.2 了解操作
>>> l=[1,2,3,4,5,6]
>>> l[0:3:1]
[1, 2, 3] # 正向步长
>>> l[2::-1]
[3, 2, 1] # 反向步长
# 通过索引取值实现列表翻转
>>> l[::-1]
[6, 5, 4, 3, 2, 1]
四 元组
4.1 作用
元组与列表类似,也是可以存多个任意类型的元素,不同之处在于元组的元素不能修改,即元组相当于不可变的列表,用于记录多个固定不允许修改的值,单纯用于取
4.2 定义方式
# 在()内用逗号分隔开多个任意类型的值
>>> countries = ("中国","美国","英国") # 本质:countries = tuple("中国","美国","英国")
# 强调:如果元组内只有一个值,则必须加一个逗号,否则()就只是包含的意思而非定义元组
>>> countries = ("中国",) # 本质:countries = tuple("中国")
4.3 类型转换
# 但凡能被for循环的遍历的数据类型都可以传给tuple()转换成元组类型
>>> tuple('wdad') # 结果:('w', 'd', 'a', 'd')
>>> tuple([1,2,3]) # 结果:(1, 2, 3)
>>> tuple({"name":"jason","age":18}) # 结果:('name', 'age')
>>> tuple((1,2,3)) # 结果:(1, 2, 3)
>>> tuple({1,2,3,4}) # 结果:(1, 2, 3, 4)
# tuple()会跟for循环一样遍历出数据类型中包含的每一个元素然后放到元组中
4.4 使用
>>> tuple1 = (1, 'hhaha', 15000.00, 11, 22, 33)
# 1、按索引取值(正向取+反向取):只能取,不能改否则报错!
>>> tuple1[0]
1
>>> tuple1[-2]
22
>>> tuple1[0] = 'hehe' # 报错:TypeError:
# 2、切片(顾头不顾尾,步长)
>>> tuple1[0:6:2]
(1, 15000.0, 22)
# 3、长度
>>> len(tuple1)
6
# 4、成员运算 in 和 not in
>>> 'hhaha' in tuple1
True
>>> 'hhaha' not in tuple1
False
# 5、循环
>>> for line in tuple1:
... print(line)
1
hhaha
15000.0
11
22
33
五 字典
5.1 定义方式
# 定义:在{}内用逗号分隔开多元素,每一个元素都是key:value的形式,其中value可以是任意类型,而key则必须是不可变类型,详见第八小节,通常key应该是str类型,因为str类型会对value有描述性的功能
info={'name':'tony','age':18,'sex':'male'} #本质info=dict({....})
# 也可以这么定义字典
info=dict(name='tony',age=18,sex='male') # info={'age': 18, 'sex': 'male', 'name': 'tony'}
5.2 类型转换
# 转换1:
>>> info=dict([['name','tony'],('age',18)])
>>> info
{'age': 18, 'name': 'tony'}
# 转换2:fromkeys会从元组中取出每个值当做key,然后与None组成key:value放到字典中
>>> {}.fromkeys(('name','age','sex'),None)
{'age': None, 'sex': None, 'name': None}
5.3 使用
5.3.1 优先掌握的操作
# 1、按key存取值:可存可取
# 1.1 取
>>> dic = {
... 'name': 'xxx',
... 'age': 18,
... 'hobbies': ['play game', 'basketball']
... }
>>> dic['name']
'xxx'
>>> dic['hobbies'][1]
'basketball'
# 1.2 对于赋值操作,如果key原先不存在于字典,则会新增key:value
>>> dic['gender'] = 'male'
>>> dic
{'name': 'tony', 'age': 18, 'hobbies': ['play game', 'basketball'],'gender':'male'}
# 1.3 对于赋值操作,如果key原先存在于字典,则会修改对应value的值
>>> dic['name'] = 'tony'
>>> dic
{'name': 'tony', 'age': 18, 'hobbies': ['play game', 'basketball']}
# 2、长度len
>>> len(dic)
3
# 3、成员运算in和not in
>>> 'name' in dic # 判断某个值是否是字典的key
True
# 4、删除
>>> dic.pop('name') # 通过指定字典的key来删除字典的键值对
>>> dic
{'age': 18, 'hobbies': ['play game', 'basketball']}
# 5、键keys(),值values(),键值对items()
>>> dic = {'age': 18, 'hobbies': ['play game', 'basketball'], 'name': 'xxx'}
# 获取字典所有的key
>>> dic.keys()
dict_keys(['name', 'age', 'hobbies'])
# 获取字典所有的value
>>> dic.values()
dict_values(['xxx', 18, ['play game', 'basketball']])
# 获取字典所有的键值对
>>> dic.items()
dict_items([('name', 'xxx'), ('age', 18), ('hobbies', ['play game', 'basketball'])])
# 6、循环
# 6.1 默认遍历的是字典的key
>>> for key in dic:
... print(key)
...
age
hobbies
name
# 6.2 只遍历key
>>> for key in dic.keys():
... print(key)
...
age
hobbies
name
# 6.3 只遍历value
>>> for key in dic.values():
... print(key)
...
18
['play game', 'basketball']
xxx
# 6.4 遍历key与value
>>> for key in dic.items():
... print(key)
...
('age', 18)
('hobbies', ['play game', 'basketball'])
('name', 'xxx')
5.3.2 需要掌握的操作
1.get()
>>> dic= {'k1':'jason','k2':'Tony','k3':'JY'}
>>> dic.get('k1')
'jason' # key存在,则获取key对应的value值
>>> res=dic.get('xxx') # key不存在,不会报错而是默认返回None
>>> print(res)
None
>>> res=dic.get('xxx',666) # key不存在时,可以设置默认返回的值
>>> print(res)
666
# ps:字典取值建议使用get方法
2.pop()
>>> dic= {'k1':'jason','k2':'Tony','k3':'JY'}
>>> v = dic.pop('k2') # 删除指定的key对应的键值对,并返回值
>>> dic
{'k1': 'jason', 'kk2': 'JY'}
>>> v
'Tony'
3.popitem()
>>> dic= {'k1':'jason','k2':'Tony','k3':'JY'}
>>> item = dic.popitem() # 随机删除一组键值对,并将删除的键值放到元组内返回
>>> dic
{'k3': 'JY', 'k2': 'Tony'}
>>> item
('k1', 'jason')
4.update()
# 用新字典更新旧字典,有则修改,无则添加
>>> dic= {'k1':'jason','k2':'Tony','k3':'JY'}
>>> dic.update({'k1':'JN','k4':'xxx'})
>>> dic
{'k1': 'JN', 'k3': 'JY', 'k2': 'Tony', 'k4': 'xxx'}
5.fromkeys()
>>> dic = dict.fromkeys(['k1','k2','k3'],[])
>>> dic
{'k1': [], 'k2': [], 'k3': []}
6.setdefault()
# key不存在则新增键值对,并将新增的value返回
>>> dic={'k1':111,'k2':222}
>>> res=dic.setdefault('k3',333)
>>> res
333
>>> dic # 字典中新增了键值对
{'k1': 111, 'k3': 333, 'k2': 222}
# key存在则不做任何修改,并返回已存在key对应的value值
>>> dic={'k1':111,'k2':222}
>>> res=dic.setdefault('k1',666)
>>> res
111
>>> dic # 字典不变
{'k1': 111, 'k2': 222}
六 集合
6.1 作用
集合、list、tuple、dict一样都可以存放多个值,但是集合主要用于:去重、关系运算
6.2 定义
"""
定义:在{}内用逗号分隔开多个元素,集合具备以下三个特点:
1:每个元素必须是不可变类型
2:集合内没有重复的元素
3:集合内元素无序
"""
s = {1,2,3,4} # 本质 s = set({1,2,3,4})
# 注意1:列表类型是索引对应值,字典是key对应值,均可以取得单个指定的值,而集合类型既没有索引也没有key与值对应,所以无法取得单个的值,而且对于集合来说,主要用于去重与关系元素,根本没有取出单个指定值这种需求。
# 注意2:{}既可以用于定义dict,也可以用于定义集合,但是字典内的元素必须是key:value的格式,现在我们想定义一个空字典和空集合,该如何准确去定义两者?
d = {} # 默认是空字典
s = set() # 这才是定义空集合
6.3 类型转换
# 但凡能被for循环的遍历的数据类型(强调:遍历出的每一个值都必须为不可变类型)都可以传给set()转换成集合类型
>>> s = set([1,2,3,4])
>>> s1 = set((1,2,3,4))
>>> s2 = set({'name':'jason',})
>>> s3 = set('egon')
>>> s,s1,s2,s3
{1, 2, 3, 4} {1, 2, 3, 4} {'name'} {'e', 'o', 'g', 'n'}
6.4 使用
6.4.1 关系运算
我们定义两个集合friends与friends2来分别存放两个人的好友名字,然后以这两个集合为例讲解集合的关系运算
>>> friends1 = {"zero","kevin","jason","egon"} # 用户1的好友们
>>> friends2 = {"Jy","ricky","jason","egon"} # 用户2的好友们
两个集合的关系如下图所示
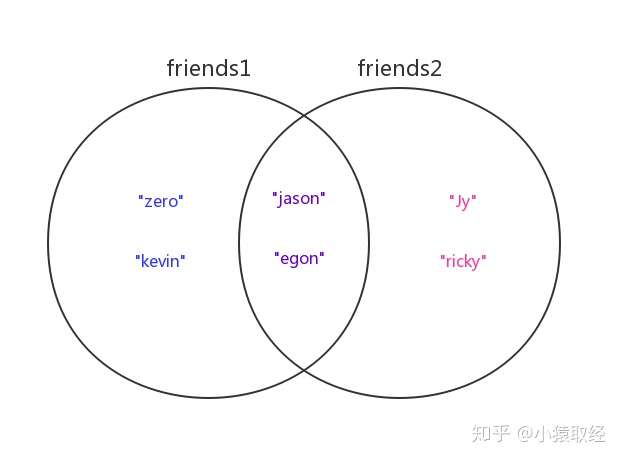
# 1.合集/并集(|):求两个用户所有的好友(重复好友只留一个)
>>> friends1 | friends2
{'kevin', 'ricky', 'zero', 'jason', 'Jy', 'egon'}
# 2.交集(&):求两个用户的共同好友
>>> friends1 & friends2
{'jason', 'egon'}
# 3.差集(-):
>>> friends1 - friends2 # 求用户1独有的好友
{'kevin', 'zero'}
>>> friends2 - friends1 # 求用户2独有的好友
{'ricky', 'Jy'}
# 4.对称差集(^) # 求两个用户独有的好友们(即去掉共有的好友)
>>> friends1 ^ friends2
{'kevin', 'zero', 'ricky', 'Jy'}
# 5.值是否相等(==)
>>> friends1 == friends2
False
# 6.父集:一个集合是否包含另外一个集合
# 6.1 包含则返回True
>>> {1,2,3} > {1,2}
True
>>> {1,2,3} >= {1,2}
True
# 6.2 不存在包含关系,则返回False
>>> {1,2,3} > {1,3,4,5}
False
>>> {1,2,3} >= {1,3,4,5}
False
# 7.子集
>>> {1,2} < {1,2,3}
True
>>> {1,2} <= {1,2,3}
True
6.4.2 去重
集合去重复有局限性
# 1. 只能针对不可变类型
# 2. 集合本身是无序的,去重之后无法保留原来的顺序
示例如下
>>> l=['a','b',1,'a','a']
>>> s=set(l)
>>> s # 将列表转成了集合
{'b', 'a', 1}
>>> l_new=list(s) # 再将集合转回列表
>>> l_new
['b', 'a', 1] # 去除了重复,但是打乱了顺序
# 针对不可变类型,并且保证顺序则需要我们自己写代码实现,例如
l=[
{'name':'lili','age':18,'sex':'male'},
{'name':'jack','age':73,'sex':'male'},
{'name':'tom','age':20,'sex':'female'},
{'name':'lili','age':18,'sex':'male'},
{'name':'lili','age':18,'sex':'male'},
]
new_l=[]
for dic in l:
if dic not in new_l:
new_l.append(dic)
print(new_l)
# 结果:既去除了重复,又保证了顺序,而且是针对不可变类型的去重
[
{'age': 18, 'sex': 'male', 'name': 'lili'},
{'age': 73, 'sex': 'male', 'name': 'jack'},
{'age': 20, 'sex': 'female', 'name': 'tom'}
]
6.4.3 其他操作
# 1.长度
>>> s={'a','b','c'}
>>> len(s)
3
# 2.成员运算
>>> 'c' in s
True
# 3.循环
>>> for item in s:
... print(item)
...
c
a
b
6.5 练习
"""
一.关系运算
有如下两个集合,pythons是报名python课程的学员名字集合,linuxs是报名linux课程的学员名字集合
pythons={'jason','egon','kevin','ricky','gangdan','biubiu'}
linuxs={'kermit','tony','gangdan'}
1. 求出即报名python又报名linux课程的学员名字集合
2. 求出所有报名的学生名字集合
3. 求出只报名python课程的学员名字
4. 求出没有同时这两门课程的学员名字集合
"""
# 求出即报名python又报名linux课程的学员名字集合
>>> pythons & linuxs
# 求出所有报名的学生名字集合
>>> pythons | linuxs
# 求出只报名python课程的学员名字
>>> pythons - linuxs
# 求出没有同时这两门课程的学员名字集合
>>> pythons ^ linuxs
七 可变类型与不可变类型
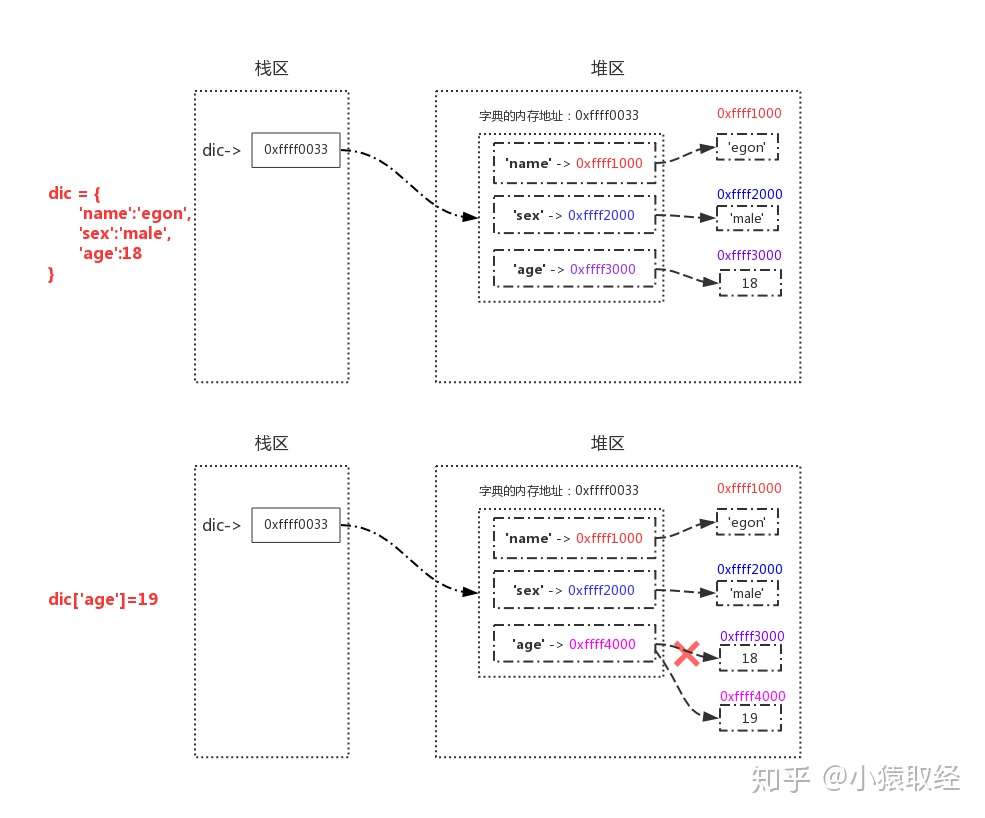
可变数据类型:值发生改变时,内存地址不变,即id不变,证明在改变原值
不可变类型:值发生改变时,内存地址也发生改变,即id也变,证明是没有在改变原值,是产生了新的值
数字类型:
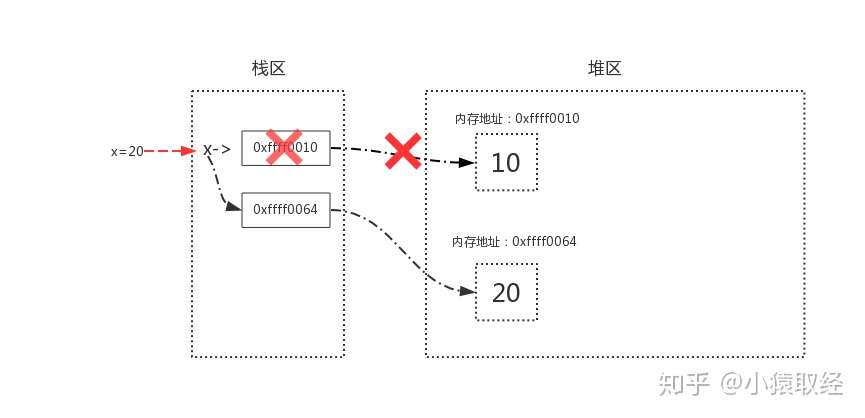
>>> x = 10
>>> id(x)
1830448896
>>> x = 20
>>> id(x)
1830448928
# 内存地址改变了,说明整型是不可变数据类型,浮点型也一样
字符串
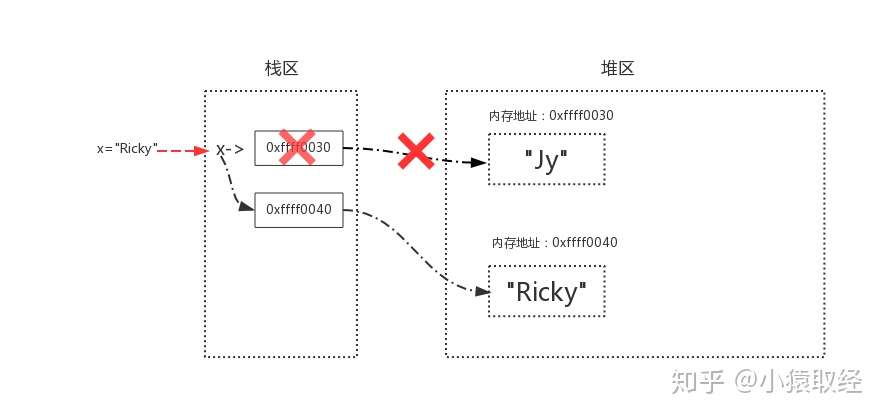
>>> x = "Jy"
>>> id(x)
938809263920
>>> x = "Ricky"
>>> id(x)
938809264088
# 内存地址改变了,说明字符串是不可变数据类型
列表
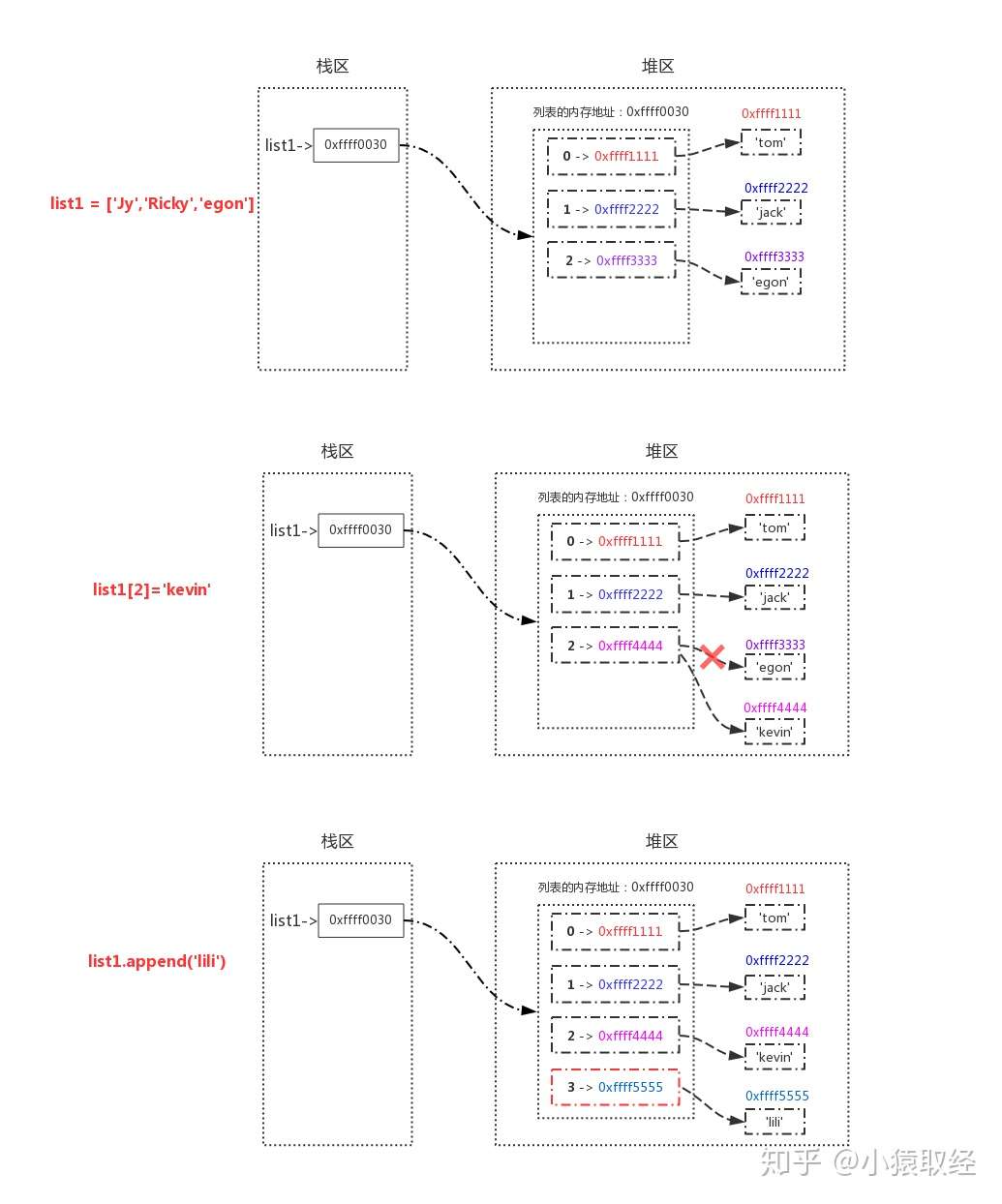
>>> list1 = ['tom','jack','egon']
>>> id(list1)
486316639176
>>> list1[2] = 'kevin'
>>> id(list1)
486316639176
>>> list1.append('lili')
>>> id(list1)
486316639176
# 对列表的值进行操作时,值改变但内存地址不变,所以列表是可变数据类型
元组
>>> t1 = ("tom","jack",[1,2])
>>> t1[0]='TOM' # 报错:TypeError
>>> t1.append('lili') # 报错:TypeError
# 元组内的元素无法修改,指的是元组内索引指向的内存地址不能被修改
>>> t1 = ("tom","jack",[1,2])
>>> id(t1[0]),id(t1[1]),id(t1[2])
(4327403152, 4327403072, 4327422472)
>>> t1[2][0]=111 # 如果元组中存在可变类型,是可以修改,但是修改后的内存地址不变
>>> t1
('tom', 'jack', [111, 2])
>>> id(t1[0]),id(t1[1]),id(t1[2]) # 查看id仍然不变
(4327403152, 4327403072, 4327422472)
字典
>>> dic = {'name':'egon','sex':'male','age':18}
>>>
>>> id(dic)
4327423112
>>> dic['age']=19
>>> dic
{'age': 19, 'sex': 'male', 'name': 'egon'}
>>> id(dic)
4327423112
# 对字典进行操作时,值改变的情况下,字典的id也是不变,即字典也是可变数据类型
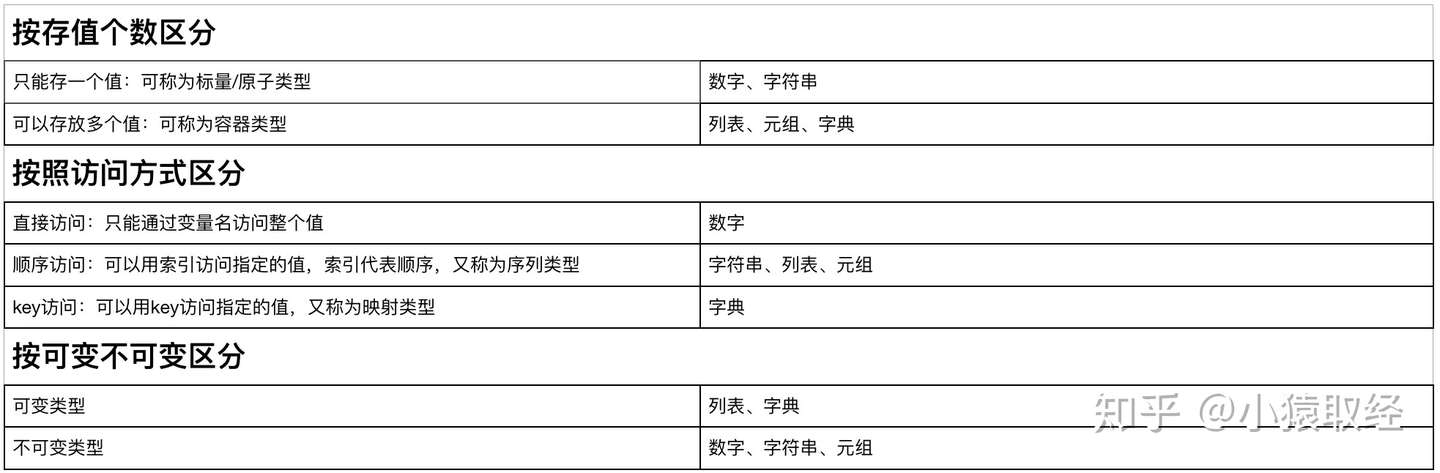
八 数据类型总结

 浙公网安备 33010602011771号
浙公网安备 33010602011771号