按字寻址按字节寻址的理解
1.内存的逻辑结构
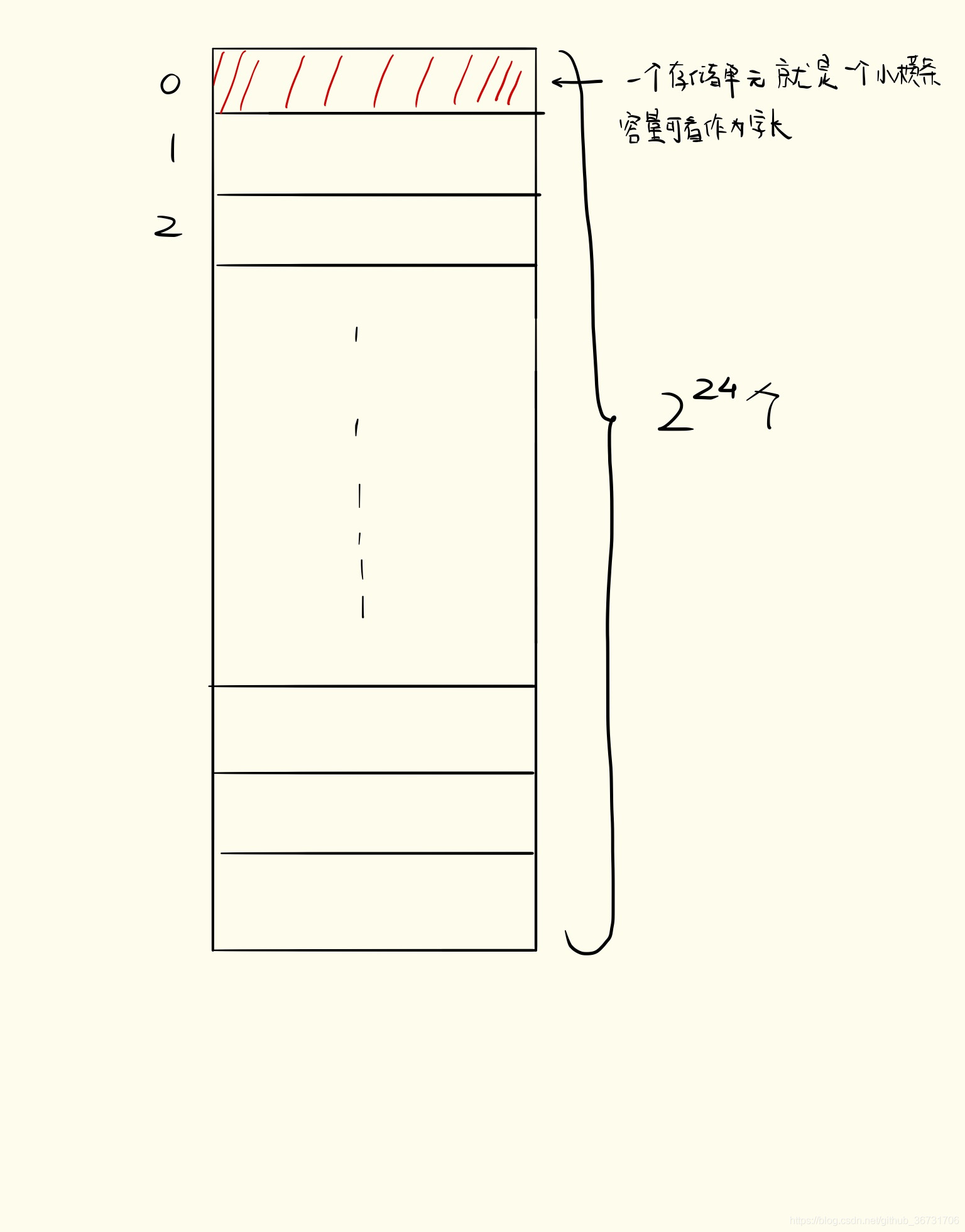
内存是由 一个个的存储单元构成的,一个存储单元里面呢可以存储一个二进制代码 如 00110110011111101,而这个单元里面存储的大小称为存储字长
2.地址线
地址线用于保存 CPU 所要处理的数值的地址
一根地址线为其通电,通高电压代表 1,低电压代表 0,一个地址线可以代表一位 0/1。两根地址线可以代表 00,01,10,11四个值,24根地址线组成的0,1排列组合可以代表 224 个值。
结合存储单元,24根地址线可以为 224个存储单元进行编址
3.数据线
数据线用于保存数据真正的值。32位的数据线可以保存32位大小的数据
通过地址线找到要处理数据的地址,再将数据写入数据线中,CPU 就可以处理数据
3.按字节寻址,按字寻址的区别
如果是按字节寻址,就是说这一个存储单元的内容我都要处理。如果说是按字寻址,则说明我只需要处理 存储单元中的某一部分
既然按字节寻址需要的是一个字节的某个部分,则还要保存它是第存储单元的第几个字节,那还要拿出相应个数的地址线说明所在字节
4.字节和字
一个字节普遍是8位二进制
以 ASCII 编码为例,一个字母占 1个字节,也就是说 ‘ a ’ 这个字母是 在ASCII 中的序号为96,转换成二进制进行存储‘01100001’ 组成的。一个汉字是 两个字节
字是由若干个字节构成
5.计算练习
一台 IBM370 字长为32位,主存的地址线为24位,分别计算按字节寻址,按字寻址的范围。如果是一台 PDP-11,地址线位数不变,那按字节寻址,按字寻址的范围分别又是多少。
首先看第一个机型
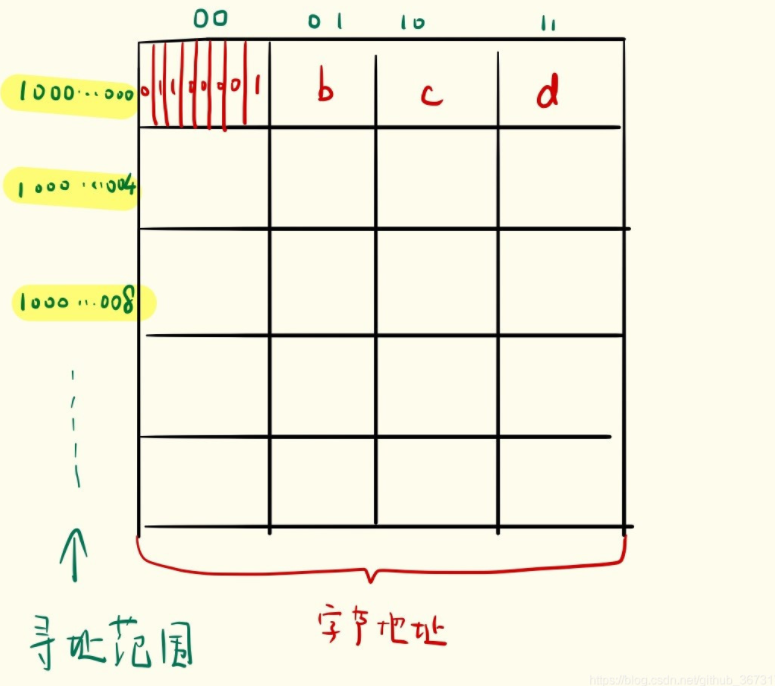
它是 IBM 370,字长为 32,我们可以理解为:它的数据线为 32根,也就是CPU 一次可以处理 32位的数据。按照八位一个字节这样一个长条可以将它的字长分为 4 个字节
那么按字节寻址,就是有几个长条
2^20^=1M
2^24^=2^20^*2^4^=1M * 16=16M
也就是说按字节寻址它的寻址范围是 16 M
如果是按字寻址,上面讲到要为字中的字节编码,这个字长为32,被分成 4 个字节,就需要地址线单独拿出最后的两根保存字节的地址。
于是乎,这24根要刨去两根,还有 22根用来按字寻址,所以按字寻址的范围是
2^22^=2^20^*2^2^=1M *4=4M
其次是第二个机型
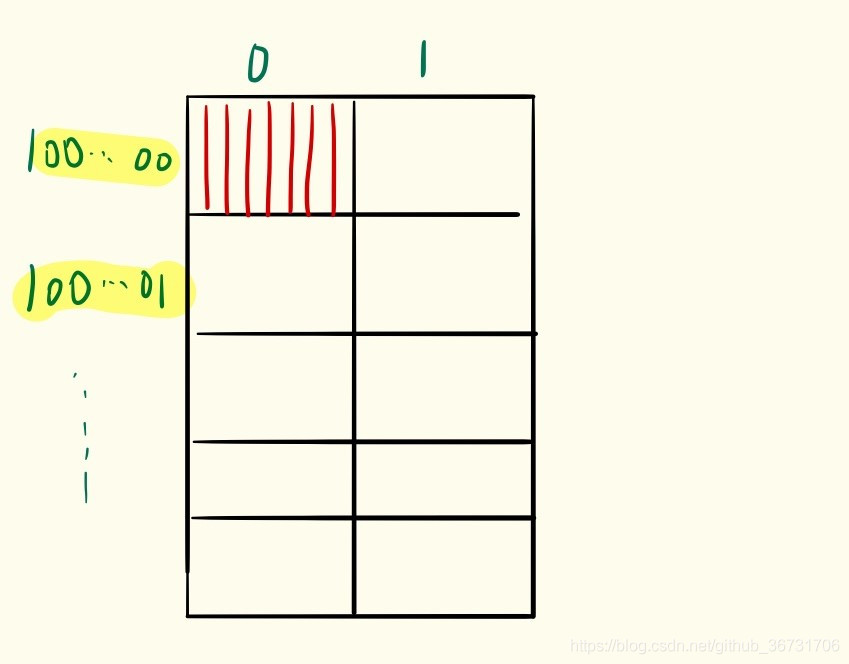
第二个结构与第一个结构的不同在于第二个结构它的字长为16,地址线个数没变,小横条的个数没变,变得是一个小横条中的字节个数。
如果小横条没变,那么按字节寻址的范围就没变,还是 16M
如果说数据线有 16根,则代表字长数为 16,8位一个字节,他可以被分为 2个字节,如果实在小横条第一个位置就用1表示,如果是小横条第二个位置用0表示。所以用一根地址线就可以了,剩下的 23根用来表示寻址范围
2^23^=2^20^ * 2^3^=8M
所以寻址范围是 8M
本文来自博客园,作者:随手一只风,转载请注明原文链接:https://www.cnblogs.com/suishou/p/14750461.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号