

彼岸网壁纸抓取
彼岸网壁纸抓取
创建时间:2024-08-11
一、代码
1.1 代码
import os
import random
import time
import requests
from lxml import etree
url = 'http://pic.netbian.com/'
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0'
}
def get_html(url):
response = requests.get(url, headers=header)
response.encoding = response.apparent_encoding
# print(response.text)
tree = etree.HTML(response.text)
return tree
tree = get_html(url)
tp_urls = tree.xpath('//ul[@class="clearfix"]/li/a/@href')
titles = tree.xpath('//ul[@class="clearfix"]/li/a/@title')
for tp, title in zip(tp_urls, titles):
# 拼凑完整的url
img_url = 'http://pic.netbian.com' + tp
tree = get_html(img_url)
img_ = tree.xpath('//a[@id="img"]/img/@src')[0]
img_urls = 'http://pic.netbian.com' + img_
print(img_urls)
# exit()
path = os.path.join('./彼岸img', title.replace(" ", "_").replace("*", "") + '.jpg')
with open(path, 'wb') as f:
f.write(requests.get(img_urls).content)
print(title)
time.sleep(random.randint(1, 3))
1.2 代码
"""
地址:http://www.netbian.com/
"""
import os
# 导入 requests 和 etree 模块
import requests
from lxml import etree
classify = "meinv"
start_page = 1
end_page = 6
# 确保 "wallpaper" 文件夹存在,
folder_path = f"./wallpaper/{classify}"
if not os.path.exists(folder_path):
os.makedirs(folder_path)
# 循环下载n页的图片
for i in range(start_page-1, end_page):
url = f"http://www.netbian.com/{classify}/" # 网站上分类的url地址
# 第一页的地址和后面页的地址不同,需要分别处理
if i == 0:
url = url + "index.htm"
i += 1
else:
url = url + "index_" + str(i + 1) + ".htm"
# 设置协议头
headesp = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.35'}
# 发送get请求并获取响应且设置编码
resp = requests.get(url, headers=headesp)
resp.encoding = resp.apparent_encoding
# 将响应内容解析为etree对象
xp = etree.HTML(resp.text)
# 获取每页中的图片详情页链接
img_url = xp.xpath("/html/body/div[@class='wrap clearfix']/div[@id='main']/div[@class='list']/ul/li/a/@href")
print(img_url)
for n in img_url:
# 根据图片详情页链接再次发送get请求并获取图片地址和名称
resp = requests.get('http://www.netbian.com' + n)
resp.encoding = resp.apparent_encoding
xp = etree.HTML(resp.text)
img_urls = xp.xpath('//div[@class="pic"]/p/a/img/@src')
img_name = xp.xpath('//div[@class="pic"]/p/a/img/@alt')
# 下载并保存到目标文件夹
for u, n in zip(img_urls, img_name):
print(f'图片名:{n} 地址:{u}')
img_resp = requests.get(u)
with open(f'./{folder_path}/{n}.jpg', 'wb') as f:
f.write(img_resp.content)
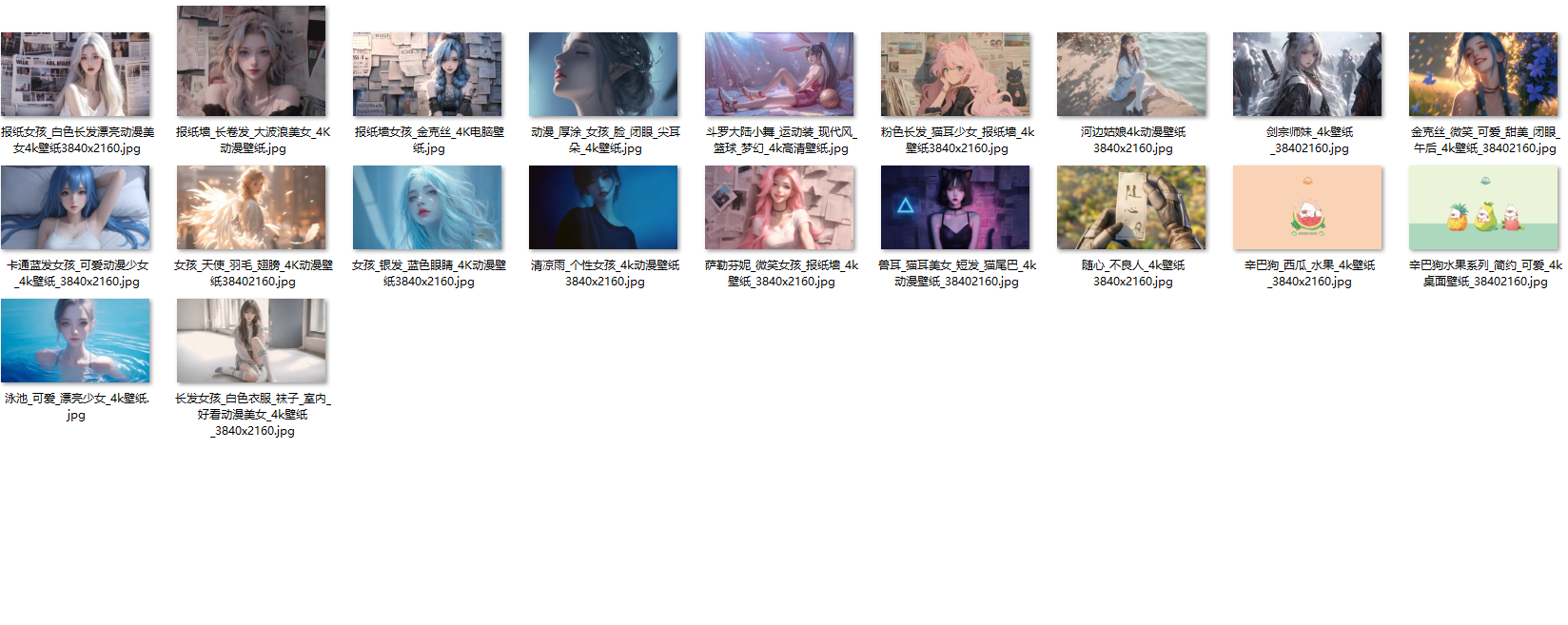
1.3 效果1
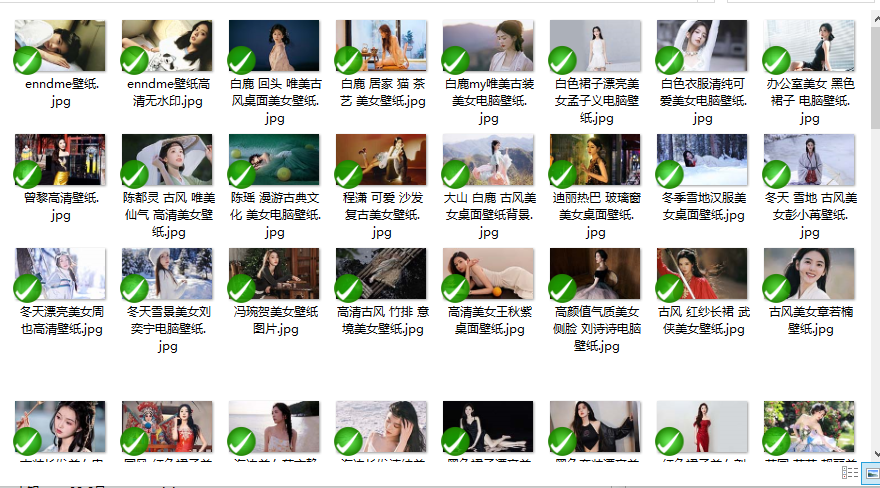
1.4 效果2
二、代码学习
2.1 设置了请求的头部信息,模拟浏览器访问。
url = 'http://pic.netbian.com/'
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0'
}
2.2 定义了一个 get_html 函数
用于获取网页的 HTML 内容,并处理编码问题,同时使用 lxml 的 etree 模块将其转换为可解析的树结构。
def get_html(url):
response = requests.get(url, headers=header)
response.encoding = response.apparent_encoding
# print(response.text)
tree = etree.HTML(response.text)
return tree
2.3 通过访问首页获取图片的链接和标题信息。
tree = get_html(url)
tp_urls = tree.xpath('//ul[@class="clearfix"]/li/a/@href')
titles = tree.xpath('//ul[@class="clearfix"]/li/a/@title')
2.4 处理获取到的每个图片详情页链接
再次请求获取真实的图片链接,并将图片保存到本地指定的路径。
for tp, title in zip(tp_urls, titles):
# 拼凑完整的url
img_url = 'http://pic.netbian.com' + tp
tree = get_html(img_url)
img_ = tree.xpath('//a[@id="img"]/img/@src')[0]
img_urls = 'http://pic.netbian.com' + img_
print(img_urls)
# exit()
path = os.path.join('./彼岸img', title.replace(" ", "_").replace("*", "") + '.jpg')
with open(path, 'wb') as f:
f.write(requests.get(img_urls).content)
print(title)
time.sleep(random.randint(1, 3))'
# 在保存图片的过程中,为了避免频繁请求对服务器造成过大压力,我们设置了随机的等待时间。
2.5 优化代码
- 定义了图片分类
classify以及起始页start_page和结束页end_page的变量,用于控制爬取的范围。 - 增加了根据分类创建文件夹的代码,以确保图片保存到特定分类的文件夹中。
- 针对不同页码构建了不同的 URL 格式,以处理第一页和后续页的 URL 差异。
三、每日一学
在爬取图片时如何避免被封禁?
- 控制访问频率:不要过于频繁地发送请求。就像前面代码中使用 time.sleep(random.randint(1, 3)) 来随机暂停 1 到 3 秒,这样可以模拟人类的正常访问行为。
例如,如果您在短时间内发送大量请求,网站可能会认为这是恶意攻击而封禁您的 IP 。 - 设置合理的请求头:确保 User-Agent 等请求头字段看起来像是正常的浏览器发送的请求。
比如,不同的浏览器和操作系统有不同的 User-Agent 特征。使用常见的浏览器 User-Agent 可以降低被识别为爬虫的风险。 - 使用代理 IP:如果您的访问频率较高,可以使用代理 IP 来切换访问的来源,避免单个 IP 被封禁。
但要注意使用合法可靠的代理服务。 - 逐步增加访问量:不要一开始就进行大量的请求,而是逐渐增加请求的数量和频率。
比如,先从少量的请求开始,观察网站的反应,然后再适当增加。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)