
豆瓣短评榜单短评下载
豆瓣短评榜单短评下载
创建时间:2024-08-07
一、完整代码
import requests
from lxml import etree
def get_html(main_url):
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0'
}
# 拿链接
res = requests.get(url, headers=header)
res.encoding = res.apparent_encoding
html = res.text
return html
def get_url_lists(html):
tree = etree.HTML(html)
url_lists = tree.xpath('//div[@class="hd"]/a/@href')
return url_lists
def movie_concat(html):
tree = etree.HTML(html)
content = tree.xpath('//div[@id="hot-comments"]//p[@class=" comment-content"]/span/text()')
title = tree.xpath('//div[@class="mod-hd"]/h2/i/text()')
movie_concat = '\n' +title[0] + '\n' + '\n'.join(content)
return movie_concat
def save_concat(movie_concat):
with open('短评.txt', 'a+', encoding='utf-8') as f:
f.write(movie_concat)
if __name__ == '__main__':
url = 'https://movie.douban.com/top250?start=0'
for url in get_url_lists(get_html(url)):
save_concat(movie_concat(get_html(url)))
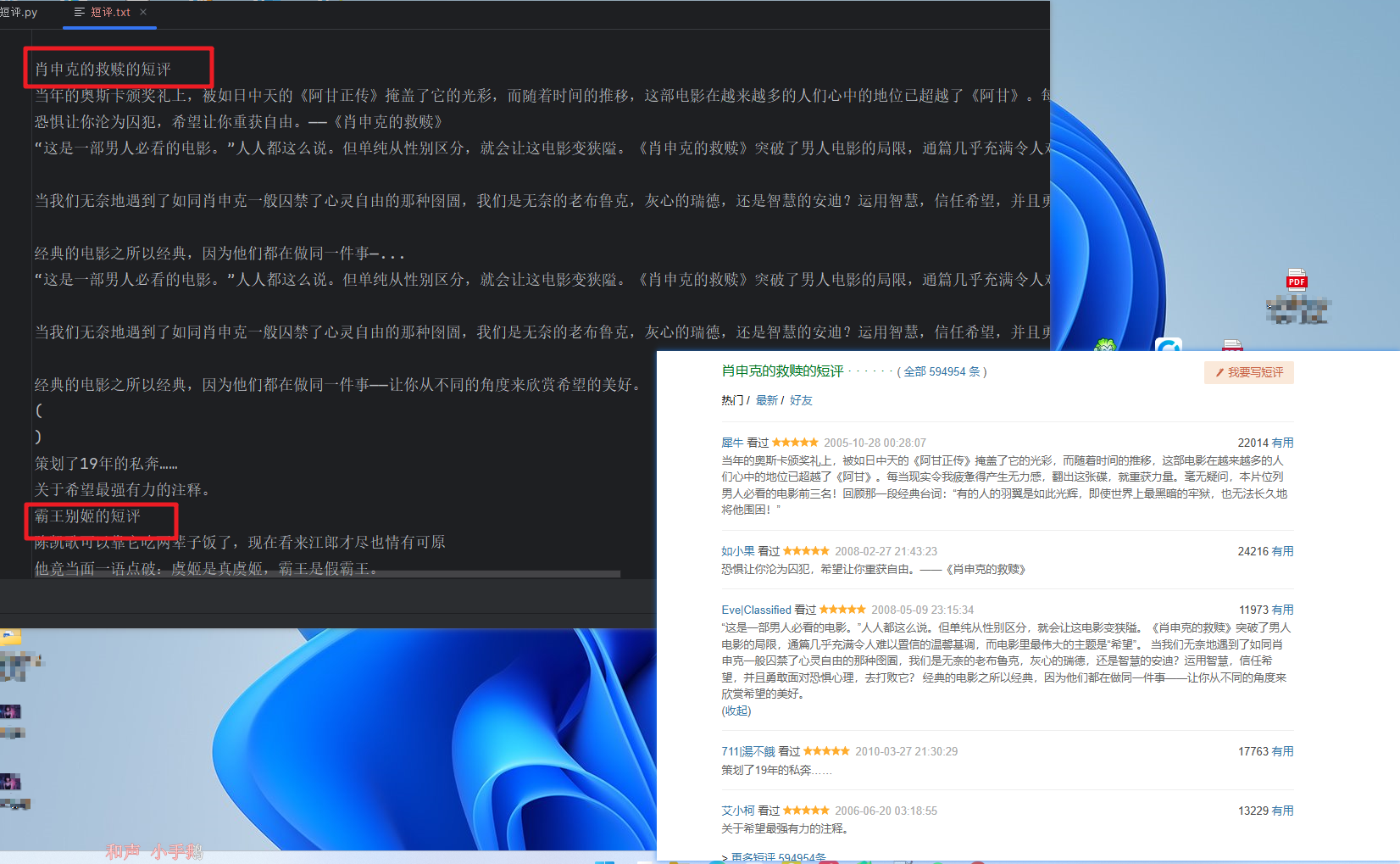
效果:
二、代码学习
以下是整个代码的主要逻辑和功能:
2.1 定义了一个 get_html 函数
用于获取网页的 HTML 内容。在这个函数中,我们设置了一个模拟浏览器的 User-Agent 头部信息,然后使用 requests.get 方法获取网页,并处理了编码问题。
def get_html(main_url):
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0'
}
# 拿链接
res = requests.get(url, headers=header)
res.encoding = res.apparent_encoding
html = res.text
return html
2.2get_url_lists 函数
通过 lxml 的 etree 模块,使用 xpath 表达式从 HTML 中提取出电影详情页的链接列表。
def get_url_lists(html):
tree = etree.HTML(html)
url_lists = tree.xpath('//div[@class="hd"]/a/@href')
return url_lists
2.3 movie_concat 函数
进一步从每个电影详情页的 HTML 中提取出电影的标题和热门短评内容,并进行整合。
def movie_concat(html):
tree = etree.HTML(html)
content = tree.xpath('//div[@id="hot-comments"]//p[@class=" comment-content"]/span/text()')
title = tree.xpath('//div[@class="mod-hd"]/h2/i/text()')
movie_concat = '\n' +title[0] + '\n' + '\n'.join(content)
return movie_concat
2.4 save_concat 函数
将整合好的电影短评内容保存到一个名为 短评.txt 的文件中。
def save_concat(movie_concat):
with open('短评.txt', 'a+', encoding='utf-8') as f:
f.write(movie_concat)
2.5 if __name__ == '__main__' 部分
我们指定了要爬取的豆瓣电影 top250 页面的初始链接,并通过循环遍历获取到的电影详情页链接,依次获取并保存短评内容。
if __name__ == '__main__':
url = 'https://movie.douban.com/top250?start=0'
for url in get_url_lists(get_html(url)):
save_concat(movie_concat(get_html(url)))
通过这样的代码实现,我们能够自动获取豆瓣电影的短评信息,为进一步的数据分析或其他应用提供了基础。
