

中信证券抓取(页码范围)
中信证券抓取(页码范围)
创建时间:2024年8月5日
一、完整代码
import re
import requests
from lxml import etree
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
}
url1 = 'http://www.cs.ecitic.com/newsite/cpzx/jrcpxxgs/zgcp/index.html'
res = requests.get(url=url1, headers=headers, verify=False)
res.encoding = res.apparent_encoding
total_num = int(re.search('var countPage = (?P<page>\d+)//共多少页', res.text).group('page'))
def get_data(url):
url = url.replace('\n', '')
print(url)
response = requests.get(url=url,
headers=headers, verify=False)
response.encoding = response.apparent_encoding
data = response.text
tree = etree.HTML(data)
rows = tree.xpath('/html/body/div[4]/div/ul/li')
for row in rows:
row_mc = row.xpath('./span[@class="th1"]/text()')
row_glr = row.xpath('./span[@class="th2"]/text()')
row_fxpj = row.xpath('./span[@class="th3"]/text()')
row_je = row.xpath('./span[@class="th4"]/text()')
row_gs = row.xpath('./span[@class="th5"]/text()')
sting = f"{row_mc}, {row_glr}, {row_fxpj}, {row_je}, {row_gs},'\n'"
sting = sting.replace("['", "").replace("']", "").replace("'", "")
with open('./zxzq/中信证券.txt', 'a+', encoding='utf-8') as f:
f.write(sting)
start_page = int(input('请输入需要抓取的页码开始:(1开始)'))
end_page = int(input(f'请输入需要抓取的页码结束:({total_num}结束)'))
for i in range(start_page - 1, end_page):
if end_page + 1 > total_num:
print('页码超过数据限制!!')
exit(-1)
if i == 0:
url = 'http://www.cs.ecitic.com/newsite/cpzx/jrcpxxgs/zgcp/index.html'
get_data(url)
else:
url = f'http://www.cs.ecitic.com/newsite/cpzx/jrcpxxgs/zgcp/index_{i}.html'
get_data(url)
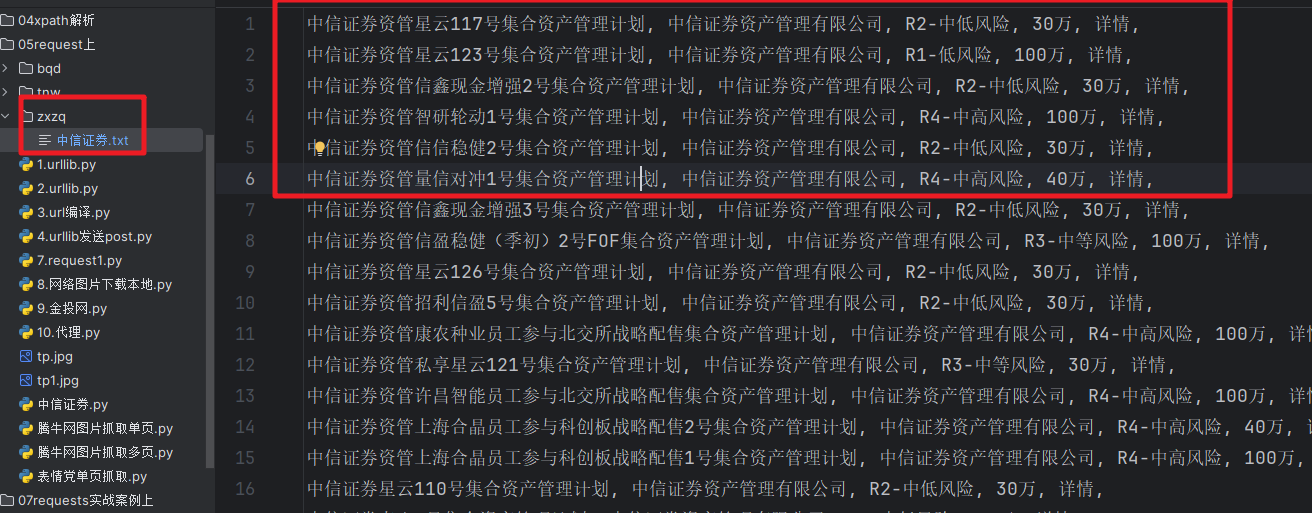
1.1 效果
二、学习点
2.1 verify 参数
verify关键字参数,在请求的时候不验证网站的ca证书
2.2 设置编码
res.encoding = res.apparent_encoding
# 大部分情况可以自动解码,实在不行可手动设置编码
res.encoding = 'utf-8'
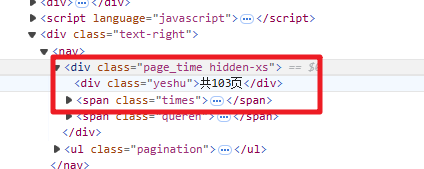
2.3 运用正则表达式获取页码
total_num = int(re.search('var countPage = (?P<page>\d+)//共多少页', res.text).group('page'))
# search(pattern, string, flags=0) 扫描字符串寻找匹配的模式,返回一个match对象,如果没有找到匹配则返回None。
页面源代码对应的页码位置:
2.4 xpath路径
rows = tree.xpath('/html/body/div[4]/div/ul/li')
for row in rows:
row_mc = row.xpath('./span[@class="th1"]/text()')
row_glr = row.xpath('./span[@class="th2"]/text()')
row_fxpj = row.xpath('./span[@class="th3"]/text()')
row_je = row.xpath('./span[@class="th4"]/text()')
row_gs = row.xpath('./span[@class="th5"]/text()')
sting = f"{row_mc}, {row_glr}, {row_fxpj}, {row_je}, {row_gs},'\n'"
sting = sting.replace("['", "").replace("']", "").replace("'", "")
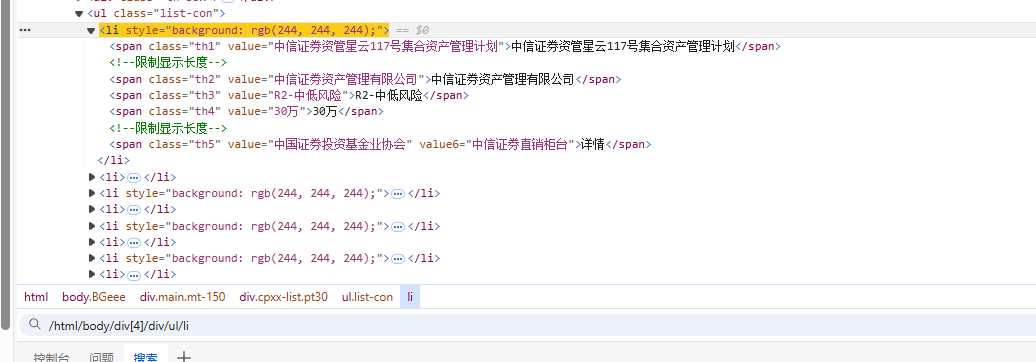
先解析到所有的数据,然后在遍历匹配出来
2.5 分页逻辑
start_page = int(input('请输入需要抓取的页码开始:(1开始)'))
end_page = int(input(f'请输入需要抓取的页码结束:({total_num}结束)'))
for i in range(start_page - 1, end_page):
if end_page + 1 > total_num:
print('页码超过数据限制!!')
exit(-1)
if i == 0:
url = 'http://www.cs.ecitic.com/newsite/cpzx/jrcpxxgs/zgcp/index.html'
get_data(url)
else:
url = f'http://www.cs.ecitic.com/newsite/cpzx/jrcpxxgs/zgcp/index_{i}.html'
get_data(url)
首页地址和第二页地址,第三页有规律,按照规律即可写出来


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· 写一个简单的SQL生成工具
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)