

抓取金投网文本数据(xpath练习)
抓取金投网文本数据(xpath练习)
创建时间:2024年8月5日
一、完整代码
import requests
from lxml import etree
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0'
}
url = 'https://cang.cngold.org/c/2024-05-21/c9310686.html'
res = requests.get(url=url, headers=header)
text = res.content.decode()
tree = etree.HTML(text)
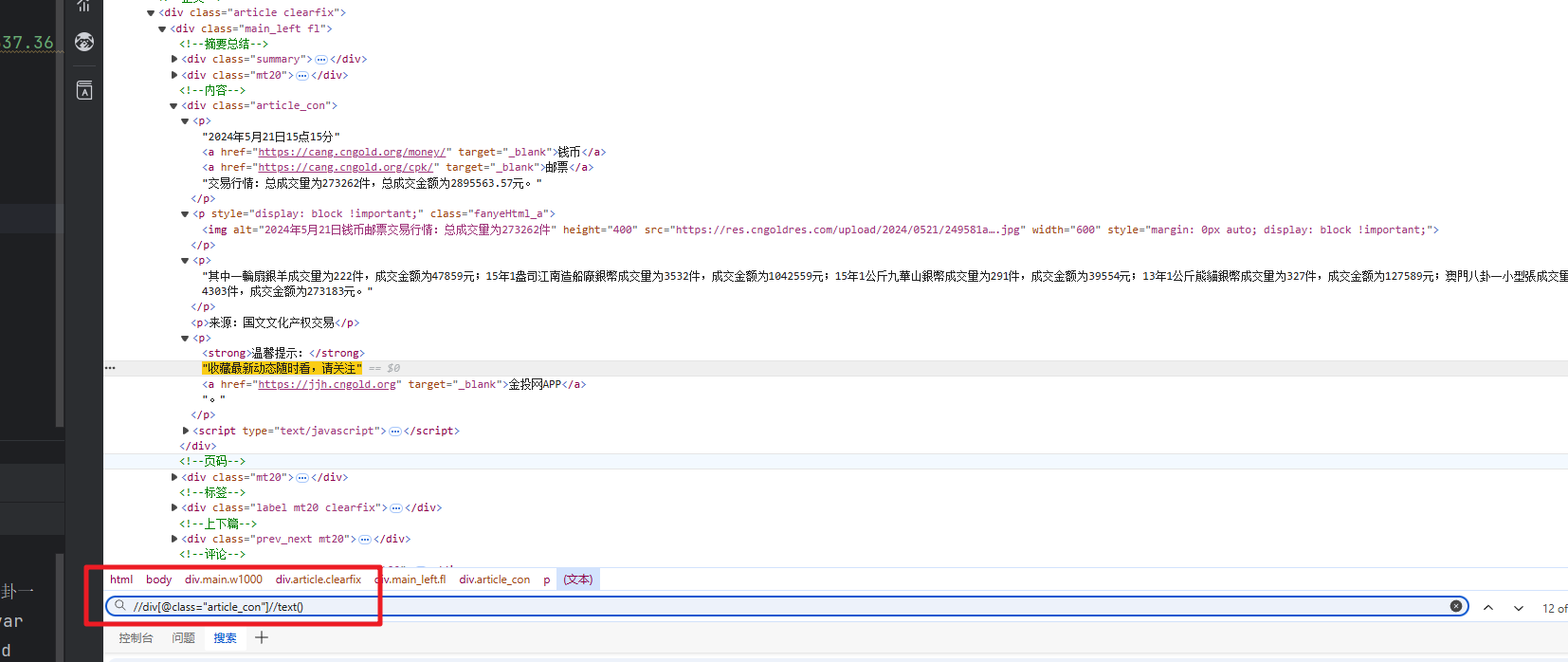
text = tree.xpath('//div[@class="article_con"]//text()')
print(text)
1.1 效果

二、代码讲解
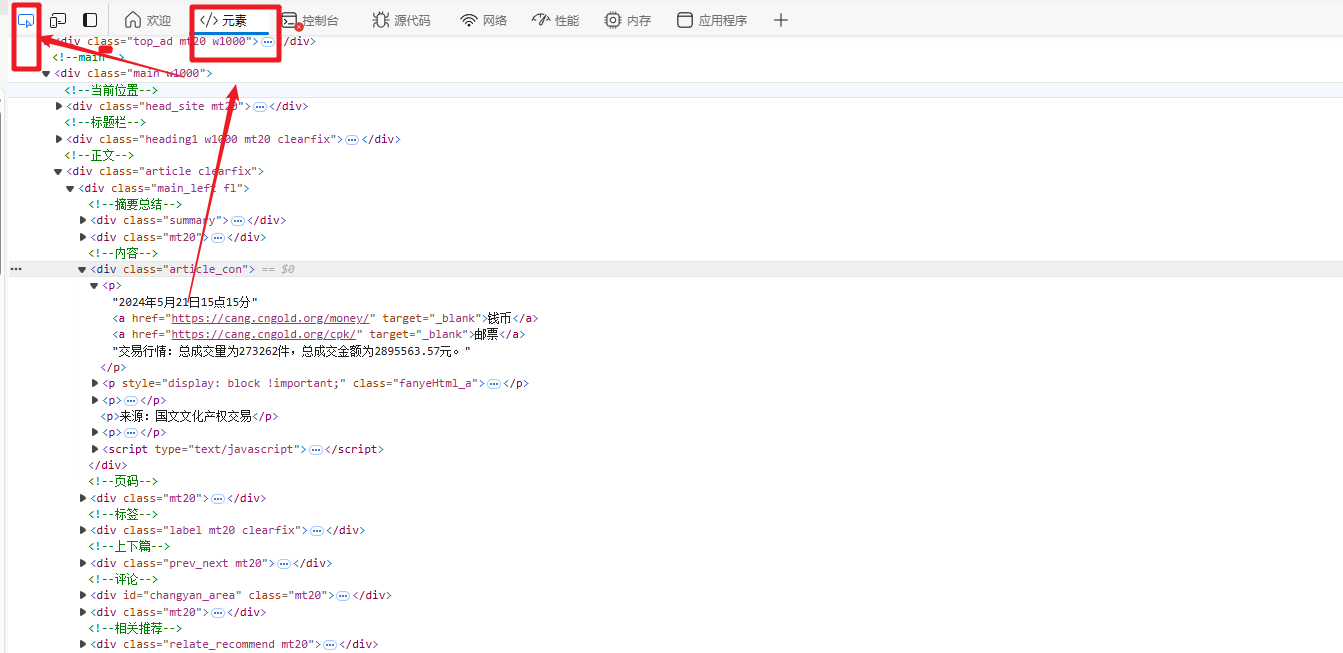
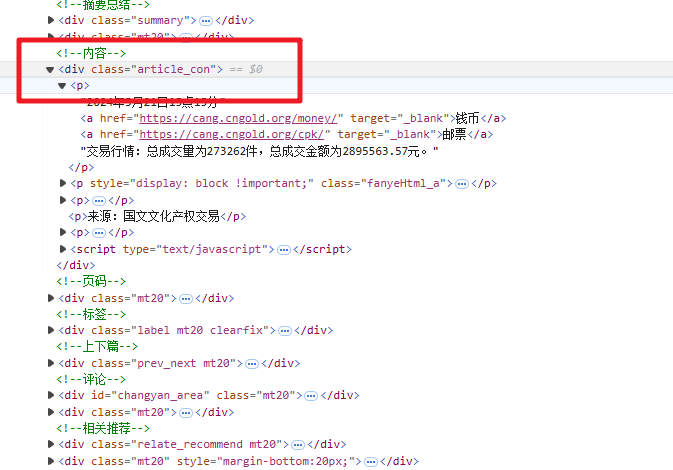
2.1 主要是分析文本在什么地方
f12打开网站。--》选择元素--》选择检查---》然后鼠标放在需要抓取的内容,即可看到页面代码对应位置,然后使用下面的xath解析
具体的地址:可先在元素界面使用 ctrl + f ,输入写的xpath检验是否正确。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· 写一个简单的SQL生成工具
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)