Python面向对象详解
一、面向对象和面向过程

面向过程编程
核心是过程二字,过程指的是解决问题的步骤,即先干什么再干什么然后干什么。。。
基于该思想编写程序好比在设计一条流水线,是一种机械式的思维方式
优点:复杂的问题流程化、进而简单化
缺点:扩展性差
面向对象编程
核心对象二字,对象是特征与技能的结合体
基于该思想编写程序就好比是在创造一个世界,你就是这个世界的上帝,是一种上帝式的思维方式
优点:可扩展性强
缺点:编程的复杂度要高于面向过程
二、类
''' 类:种类、分类、类别 对象是特征与技能的结合体,类是一系列对象相似的特征与技能的结合体 强调:站的角度不同,总结出的类是截然不同的 在现实世界中:先有的一个个具体存在的对象,然后随着人类文明的发展才有了分类的概念 在程序中:必须先定义类,后调用类来产生对象 现实世界中对对象==》总结出现实世界中的类==》定义程序中的类==》调用类产生程序中的对象 站在老男孩选课系统的角度,先总结现实世界中的老男孩的学生对象(这些对象有相似的特征和技能) 对象1: 特征: 学校='oldboy' 姓名='耗哥' 年龄=18 性别='male' 技能: 选课 对象2: 特征: 学校='oldboy' 姓名='猪哥' 年龄=17 性别='male' 技能: 选课 对象3: 特征: 学校='oldboy' 姓名='帅翔' 年龄=19 性别='female' 技能: 选课 站在老男孩选课系统的角度,先总结现实世界中的老男孩学生类 老男孩学生类: 相似的特征: 学校='oldboy' 相似的技能 选课 ''' #在程序中 #1、先定义类 class OldboyStudent: #先定义类,定义阶段类体代码立刻执行,产生一个类的名称空间,将一系列相似的特征与技能的名字丢到类的名称空间中 school='oldboy' #将student名字丢到类的名称空间中,指向’oldboy'的内存地址 def choose_course(self): #将choose_course名字丢到类的名称空间中,指向函数的内存地址 print('is choosing course') #类体代码会在类定义阶段就立刻执行,会产生一个类的名称空间 # 类的本身其实就是一个容器/名称空间,是用来存放名字的,这是类的用途之一 # print(OldboyStudent.__dict__) #类的字典属性,里面存放了一堆名字 # print(OldboyStudent.__dict__['school']) #数据属性:字典通过key值,就可以取到对应的value值 # print(OldboyStudent.__dict__['choose_course']) #函数属性:字典通过key值,就可以取到对应的value值,value值是是函数的内存地址 # OldboyStudent.__dict__['choose_course']() #内存地址加括号就可以直接调用 # print(OldboyStudent.school) #OldboyStudent.__dict__['school'] #另外一种访问数据属性的方法,直接使用点就可以访问类的名称空间中的名字 # print(OldboyStudent.choose_course) #OldboyStudent.__dict__['choose_course']#另外一种访问函数属性的方法,直接使用点就可以访问类的名称空间中的名字 # OldboyStudent.choose_course(111) #类通过点直接访问的函数属性就是一个普通的函数,要遵循函数的传参的规则 # 类的增删改查 # 增 # OldboyStudent.country='China' #OldboyStudent.__dict__['country']='China' # 改 # OldboyStudent.country='CHINA' #OldboyStudent.__dict__['country']='China' # 删 # del OldboyStudent.school # 查 # print(OldboyStudent.__dict__) #2、后调用类产生对象,调用类的过程,又称为类的实例化,实例化的结果称为类的对象/实例 # stu1=OldboyStudent() # 调用类会得到一个返回值,该返回值就是类的一个具体存在的对象/实例 # stu2=OldboyStudent() # 调用类会得到一个返回值,该返回值就是类的一个具体存在的对象/实例 # stu3=OldboyStudent() # 调用类会得到一个返回值,该返回值就是类的一个具体存在的对象/实例 # 类的实例化过程都发生了哪些事? # 如何在实例化的过程中为对象定制自己独有的特征 # 程序中对象到底是什么,如何使用?
三、为对象定制自己独有的属性
# # 例1 class OldboyStudent: #定义一个类,执行类体代码 school='oldboy' #在类的名称空间产生一个数据属性的名字(特征) def choose_course(self):#在类的名称空间产生一个函数属性的名字(技能) print('is choosing course') stu1=OldboyStudent() #实例化(调用类)产生一个空对象,对象就是一个名称名称空间,就是用来存放一堆自己独有的数据属性的 stu2=OldboyStudent() stu3=OldboyStudent() #对象本质也就是一个名称空间而已,对象名称空间(容器)是用存放对象自己------独有的名字/属性,而 #类中存放的是对象们---------------------------------------------------共有的属性 print(stu1.__dict__) #-----{},通过字典属性,可以查看字典是一个空字典{} print(stu2.__dict__) print(stu3.__dict__) # 问题点:以下产生的三个对象,有相似的特征与技能,首先想到的是将其放到一个函数中,减少代码冗余 stu1.name='耗哥' #本质stu1.__dict__['name']='耗哥' stu1.__dict__['name']='耗哥' #就是往空对象中加入了一个key:value stu1.age=18 stu1.sex='male' print(stu1.name,stu1.age,stu1.sex) #-----耗哥 18 male,通过点就可以访问对象名称空间中的名字,进而拿到与名字绑定的值 print(stu1.__dict__) #-----{'name': '耗哥', 'age': 18, 'sex': 'male'},可以看到对象中独有的数据属性 stu2.name='猪哥' stu2.age=17 stu2.sex='male' stu3.name='帅翔' stu3.age=19 stu3.sex='female' # # 例2--------------------------------------------------------------------------- class OldboyStudent: school='oldboy' def choose_course(self): print('is choosing course') stu1=OldboyStudent() stu2=OldboyStudent() stu3=OldboyStudent() '''在类之外定义类一个函数,将相似的特征封装成了一个函数,不同的对象来调用只需要直接传参就可以了''' def init(obj,x,y,z): #将对象和需要的实参按位置传给形参,将不同的对象传入都可以来调用 obj.name=x obj.age=y obj.sex=z # stu1.name='耗哥' # stu1.age=18 # stu1.sex='male' init(stu1,'耗哥',18,'male') #封装成函数后,上面的三行代码就可以不用写了,减少了代码冗余的目的 # # stu2.name='猪哥' # stu2.age=17 # stu2.sex='male' init(stu2,'诸哥',17,'male') #对象2来调用也只需要,将参传入即可 # stu3.name='帅翔' # stu3.age=19 # stu3.sex='female' init(stu3,'帅翔',19,'female') #对象3来调用也只需要,将参传入即可 print(stu1.__dict__) #--------{'name': '耗哥', 'age': 18, 'sex': 'male'} print(stu2.__dict__) #--------{'name': '诸哥', 'age': 17, 'sex': 'male'} print(stu3.__dict__) #--------{'name': '帅翔', 'age': 19, 'sex': 'female'} # 例3 # 在类体内定义一个__init__函数,将其名字存放在类的名称空间中,这样可以被所有调用类产生的对象引用 class OldboyStudent: school='oldboy' def __init__(obj, x, y, z): #会在调用类时自动触发,(调用类产生对象,将对象自动传入给obj,而此时的obj不在仅仅是一个形参,而是一个对象,对象就是一个容器,容器内存放很多名字,都可以被引用) obj.name = x #stu1.name='耗哥' (通过点拿到对象名称空间中的name) obj.age = y #stu1.age=18 #给对象添加独有的数据属性 obj.sex = z #stu1.sex='male' def choose_course(self): #choose_course是存放在类的名称空间中的,哪个对象来调用就会将其绑定给谁,并将对象当做第一个参数传入(精髓在与对象就是一个名称空间,这样对象中的名称空间的名字都可以被引用) print('is choosing course') #调用类时发生两件事 #1、创造一个空对象stu1 #2、自动触发类中__init__功能的执行,将stu1以及调用类括号内的参数一同传入 stu1=OldboyStudent('耗哥',18,'male') #本质就是:OldboyStudent.__init__(stu1,'耗哥',18,'male')-----类点一个类体代码内的函数属性,就是跟访问一个普通函数没有任何区别,按照函数的属性给其传参即可 stu2=OldboyStudent('猪哥',17,'male') stu3=OldboyStudent('帅翔',19,'female') # print(stu1.__dict__) #------{'name': '耗哥', 'age': 18, 'sex': 'male'} print(stu2.__dict__) #------{'name': '猪哥', 'age': 17, 'sex': 'male'} print(stu3.__dict__) #------{'name': '帅翔', 'age': 19, 'sex': 'female'}
配图
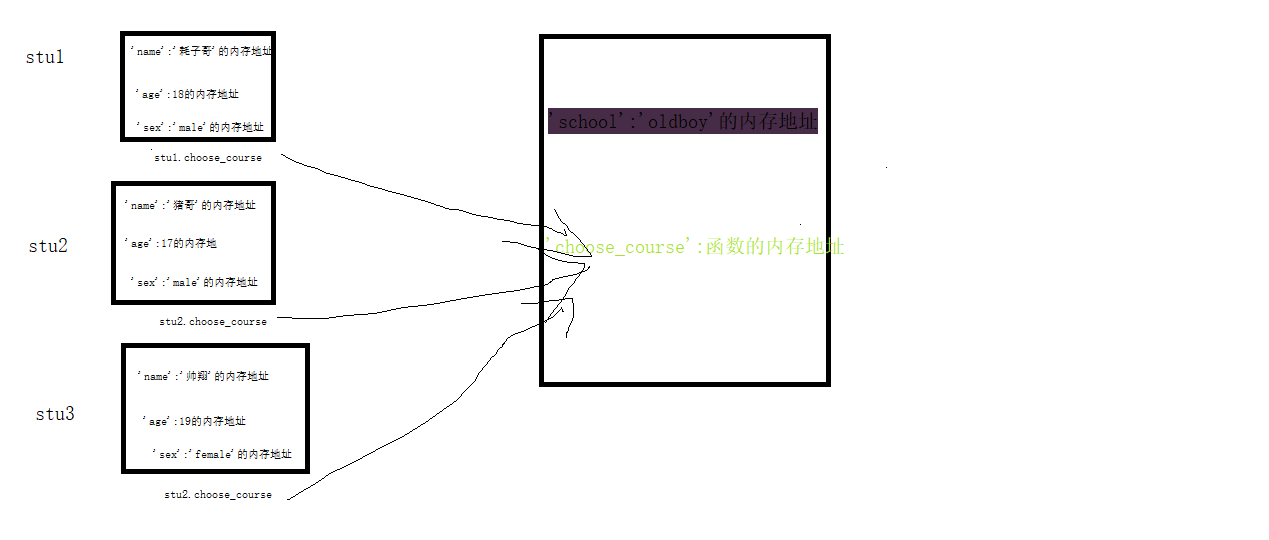
四、属性查找
class OldboyStudent: #------------------重点:类体代码产生的所用名字都放在类的名称空间中,这样可以被共享给所有的对象用,对象通过点就可以引用 school='oldboy' count=0 #这个count是放在类的名称空间中,可以给调用类产生的不同的对象引用 def __init__(self, x, y, z): #会在调用类时自动触发 self.name = x #stu1.name='耗哥' self.age = y #stu1.age=18 self.sex = z #stu1.sex='male' OldboyStudent.count+=1 #每调用一次类产生一个对象,count就加一,调用单词就加了三次 def choose_course(self): print('is choosing course') # 先从对象自己的名称空间找,没有则去类中找,如果类也没有则报错 stu1=OldboyStudent('耗哥',18,'male') stu2=OldboyStudent('猪哥',17,'male') stu3=OldboyStudent('帅翔',19,'female') print(OldboyStudent.count) #类直接点访问类名称空间中的名字 print(stu1.count) #-----类被调用了三次所以结果是3:对象点名字,会先从自己的名称空间找,没找到到自己类的名称空间找 print(stu2.count) print(stu3.count)
五、绑定方法
class OldboyStudent: school='oldboy' #-------------------------类中定义的数据属性是共享给所有对象用的 def __init__(self, x, y, z): #会在调用类时自动触发--------类中定义的所有函数属性是共享给所有对象用的 self.name = x #stu1.name='耗哥'======》stu1.__dict__['name']='耗哥' self.age = y #stu1.age=18 self.sex = z #stu1.sex='male' def choose_course(self,x): #-------------------------类中定义的所有函数属性是共享给所有对象用的,调用类会将对象自动传入,就可以应用对象下的数据属性 print('%s is choosing course' %self.name)#-----------通过点引用了对象下的name数据属性 # def func(): #类中定义的函数会默认传入一个self,如果不写调用类时会自动将产生的对象传入,此时就会报错,TypeError: func() takes 0 positional arguments but 1 was given # pass # 类名称空间中定义的数据属性和函数属性都是共享给所有对象用的 # 对象名称空间中定义的只有数据属性,而且是对象所独有的数据属性 stu1=OldboyStudent('耗哥',18,'male') #调用类,会将对象自动传入给self,参数会按位置传__init__函数的其他形参 stu2=OldboyStudent('猪哥',17,'male') stu3=OldboyStudent('帅翔',19,'female') print(stu1) # print(stu1.name) #访问对象下的数据属性 # print(stu1.school) # 类中定义的函数是类的函数属性,类可以使用,但使用的就是一个普通的函数而已,意味着需要完全遵循函数的参数规则,该传几个值就传几个 # print(OldboyStudent.choose_course) #打印结构是一个函数的内存地址,所以类通过点使用类中定义的函数,跟使用一个普通函数一样,需要参数传参即可 # OldboyStudent.choose_course(123) # 类中定义的函数是共享给所有对象的,对象也可以使用,而且是绑定给对象用的, #绑定的效果:绑定给谁,就应该由谁来调用,谁来调用就会将谁当作第一个参数自动传入(自动传入给self) # print(id(stu1.choose_course)) #2176273098184(每次运行同一个对象得到的id是不一样的,因为每次都要重新申请一个内存地址) # print(id(stu2.choose_course)) #2176273098184(将类的函数属性绑定给对象) # print(id(stu3.choose_course)) #2176273098184 #三个不同的对象应用了类的名称空间的函数属性,指向的是同一个内存地址,所以三者的id值一样的 # print(id(OldboyStudent.choose_course)) # # print(id(stu1.school)) #将类的数据属性绑定给对象 # print(id(stu2.school)) # print(id(stu3.school)) # # print(id(stu1.name),id(stu2.name),id(stu3.name)) # stu1.choose_course(1) #绑定给对象用的,所以会将对象当作第一个参数传入,即此时我们只需要再传入一个参数就可以了,并不是self没有被传参 # stu2.choose_course(2) # stu3.choose_course(3) # stu1.func() # 重点: # 补充:类中定义的函数,类确实可以使用,但其实类定义的函数大多情况下都是绑定给对象用的,所以在类中定义的函数都应该自带一个参数self
六、类即类型
#在python3中统一了类与类型的概念,类就是类型 class OldboyStudent: school='oldboy' def __init__(self, x, y, z): #会在调用类时自动触发 self.name = x #stu1.name='耗哥' self.age = y #stu1.age=18 self.sex = z #stu1.sex='male' def choose_course(self,x): print('%s is choosing course' %self.name) stu1=OldboyStudent('耗哥',18,'male') # stu1.choose_course(1) #OldboyStudent.choose_course(stu1,1) # OldboyStudent.choose_course(stu1,1) l=[1,2,3] #l=list([1,2,3]) #list即列表类型也即列表类,l就是调用列表类加括号产生的对象 print(type(l)) #<class 'list'> # l.append(4) #list.append(l,4) #类可以访问类中定义的函数属性,对象也可以访问类中定义的函数属性 list.append(l,4) # print(l)
七、小结
''' 重点 # 对象是一个高度整合的产物,整合数据与专门操作该数据的方法(绑定方法) class Foo: def __init__(self,host,port,db,chartset): self.host=host self.port=port self.db=db self.charset=charset def exc1(self,sql): conn = connect(self.host, self.port, self.db, self.charset) conn.execute(sql) return xxx def exc2(self,proc_name) conn = connect(self.host, self.port, self.db, self.charsett) conn.call_proc(sql) return xxx class Bar: def __init__(self,x,y,z,a,b,c): self.x=x self.y=y self.z=z self.a=a self.b=b self.c=c def exc3(self,xxx): pass def exc4(self,yyy) pass obj1=Foo('1.1.1.1',3306,'db1','utf-8') obj1.exc1('select * from t1') obj1.exc1('select * from t2') obj1.exc1('select * from t3') obj1.exc1('select * from t4') obj2=Foo('1.1.1.2',3306,'db1','utf-8') obj2.exc1('select * from t4') '''
八、继承与派生
''' 1、什么是继承 继承是一种新建类的方式,新建的类称为子类,被继承的类称为父类 继承的特性是:子类会遗传父类的属性 强调:继承是类与类之间的关系 2、为什么用继承 继承的好处就是可以减少代码的冗余 3、如何用继承 在python中支持一个类同时继承多个父类 在python3中 如果一个类没有继承任何类,那默认继承object类 在python2中: 如果一个类没有继承任何类,不会继承object类 新式类 但凡继承了object的类以及该类的子类,都是新式类 经典类 没有继承object的类以及该类的子类,都是经典类 在python3中都是新式类,只有在python2中才区别新式类与经典类 新式类vs经典类? ''' class Parent1(object): pass class Parent2(object): pass class Sub1(Parent1,Parent2): pass print(Sub1.__bases__) #bases是查看类的所有父类(<class '__main__.Parent1'>, <class '__main__.Parent2'>) print(Parent1.__bases__) #(<class 'object'>,)-----没有父类,默认父类是object print(Parent2.__bases__) #(<class 'object'>,)-----没有父类,默认父类是object
九、继承的应用
#派生:子类中新定义的属性,子类在使用时始终以自己的为准 class OldboyPeople: #父类----------------将类与类相似的数据属性和函数属性放在父类中,这样可以减少代码冗余 school = 'oldboy' def __init__(self,name,age,sex): #定制对象自己独有的数据属性,哪个对象来调用,哪个对象就具有该数据属性,我们只需要给其添加属性值即可 self.name = name #tea1.name='egon' self.age = age #tea1.age=18 self.sex = sex #tea1.sex='male' class OldboyStudent(OldboyPeople):#子类-------子类内的就是派生类,就是除父类之外的自己独有的数据属性和函数属性 def choose_course(self): print('%s is choosing course' %self.name) class OldboyTeacher(OldboyPeople):#子类-------子类内的就是派生类,就是除父类之外的自己独有的数据属性和函数属性 # tea1,'egon',18,'male',10 def __init__(self,name,age,sex,level): # self.name=name #左边name是属性,右边name是变量 # self.age=age # self.sex=sex OldboyPeople.__init__(self,name,age,sex)#(实现代码的重用,实现代码的冗余)类点一个函数属性和引用一个普通的函数没有什么区别,按照位置传参就可以了,指名道姓,与继承无关 self.level=level def score(self,stu_obj,num):#传入要给的学生对象,和要改的分数,stu1是一个高度整合的产物,拿到self不仅拿到对象独有的数据属性还有公有的属性,还有处理数据的所有方法 print('%s is scoring' %self.name) stu_obj.score=num #这样就可以拿到学生对象的名称空间,将其数据属性score进行修改,实现不同类的数据属性进行交互 stu1=OldboyStudent('耗哥',18,'male') tea1=OldboyTeacher('egon',18,'male',10) #对象查找属性的顺序:对象自己-》对象的类-》父类-》父类。。。 # print(stu1.school) # print(tea1.school) # print(stu1.__dict__) # print(tea1.__dict__) tea1.score(stu1,99) #----egon is scoring,对象绑定到方法,会将对象自动传入,再将其他参数传入,再有该对象来调用该函数,执行函数体代码 # print(stu1.__dict__) #{'name': '耗哥', 'age': 18, 'sex': 'male', 'score': 99} # 在子类派生出的新功能中重用父类功能的方式有两种: #1、指名道姓访问某一个类的函数:该方式与继承无关
# class Foo: # def f1(self): # print('Foo.f1') # # def f2(self): # print('Foo.f2') # self.f1() # # class Bar(Foo): # def f1(self): # print('Bar.f1') # # #对象查找属性的顺序:对象自己-》对象的类-》父类-》父类。。。 # obj=Bar() # obj.f2() # ''' # Foo.f2 # Bar.f1 # '''
python之基础知识大全








【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?