

常用窗口函数以及应用场景
1、ROW_NUMBER
- 命令格式
row_number() over(partition by [col1, col2…] order by [col1[asc|desc], col2[asc|desc]…])
- 命令说明
该函数用于计算行号,从1开始。
- 参数说明
partition by [col1, col2..]:指定开窗口的列。order by col1[asc|desc], col2[asc|desc]:指定结果返回时的排序的值。
- 返回值说明
返回BIGINT类型。
- 用于去重
SELECT * FROM ( SELECT * , ROW_NUMBER() OVER (PARTITION BY t.去重字段 ORDER BY t.去重字段 DESC) AS rn FROM xxx t ) p WHERE p.rn = 1;
2、LAG
- 命令格式
lag(expr,Bigint offset, default) over(partition by [col1, col2…] [order by [col1[asc|desc], col2[asc|desc]…]])
- 命令说明
按偏移量取当前行之前第几行的值。如果当前行号为
rn,则取行号为rn-offset的值。
LAG()窗口函数返回分区中当前行之前行(可以指定第几行)的值。 如果没有行,则返回null。
- 参数说明
expr:任意类型。offset:BIGINT类型常量。输入值为STRING、DOUBLE到BIGINT的隐式转换,offset>0。default:当offset指定的范围越界时的缺省值,常量,默认值为NULL。partition by [col1, col2..]:指定开窗口的列。order by col1[asc|desc], col2[asc|desc]:指定返回结果的排序方式。
- 返回值说明
返回值类型同
expr类型。
3、LEAD
- 命令格式
lead(expr,Bigint offset, default) over(partition by [col1, col2…] [order by [col1[asc|desc], col2[asc|desc]…]])
- 命令说明
按偏移量取当前行之后第几行的值。如果当前行号为
rn,则取行号为rn+offset的值。
LEAD()窗口函数返回分区中当前行后面行(可以指定第几行)的值。 如果没有行,则返回null。
- 参数说明
expr:任意类型。offset:可选,BIGINT类型常量。输入值为STRING、DECIMAL、DOUBLE到BIGINT的隐式转换,offset>0。default:可选,当offset指定的范围越界时的缺省值,常量。partition by [col1, col2..]:指定开窗口的列。order by col1[asc|desc], col2[asc|desc]:指定返回结果的排序方式。
- 返回值说明
返回值类型同
expr类型。
window子句:
- PRECEDING:往前
- FOLLOWING:往后
- CURRENT ROW:当前行
- UNBOUNDED:起点,UNBOUNDED PRECEDING 表示从前面的起点, UNBOUNDED FOLLOWING:表示到后面的终点
select name,orderdate,cost, sum(cost) over() as sample1,--所有行相加 sum(cost) over(partition by name) as sample2,--按name分组,组内数据相加 sum(cost) over(partition by name order by orderdate) as sample3,--按name分组,组内数据累加 sum(cost) over(partition by name order by orderdate rows between UNBOUNDED PRECEDING and current row ) as sample4 ,--和sample3一样,由起点到当前行的聚合 sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING and current row) as sample5, --当前行和前面一行做聚合 sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING AND 1 FOLLOWING ) as sample6,--当前行和前边一行及后面一行 sum(cost) over(partition by name order by orderdate rows between current row and UNBOUNDED FOLLOWING ) as sample7 --当前行及后面所有行 from t_window;
应用场景
一、聚合
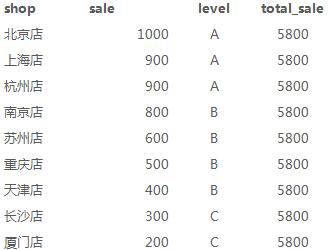
1、店铺19年总销量(sum)
sum是求和,over()没有参数,则对所有数据进行求和,输出的结果都是5800
select a.*, sum(sale)over() as total_sale from sale_detial a

2、店铺19年每个level总销量(sum)
用level分组求和,则每个level的输出结果一致
select a.*, sum(sale)over() as total_sale, sum(sale)over(partition by level) as level_sale from sale_detial a


3、店铺19年每个level按城市销量降序累加求和销量(sum)
当使用order by时,没有rows between则意味着窗口是从起始行到当前行,所以对不同level进行累加求和
select a.*, sum(sale)over() as total_sale, sum(sale)over(partition by level) as level_sale, sum(sale)over(partition by level order by sale desc) as level_cum_sale from sale_detial a


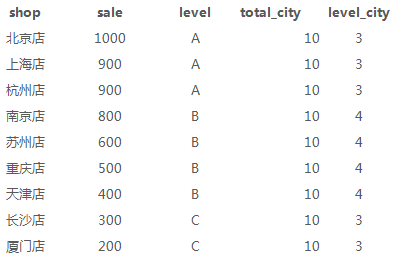
4、店铺19年总销售城市数量、每个level城市数量(count)
count()是计数,可以用count(distinct city)进行去重,如果partition by进行分组,则分组后计数
select a.*, count(city)over() as total_city, count(city)over(partition by level) as level_city from sale_detial a

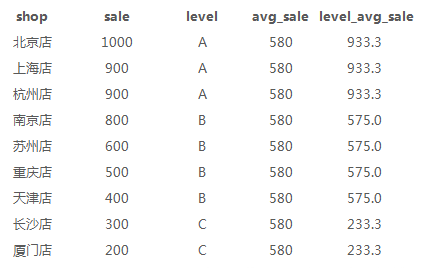
5、 店铺19年平均每个城市销量,各level平均销量(avg)
avg用法与sum基本一致
select a.*, avg(sale)over() as avg_sale, avg(sale)over(partition by level) as level_avg_sale from sale_detial a

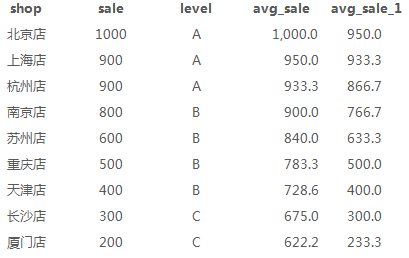
6、店铺19年按城市销量降序后,截止当前平均、移动平均(avg)
当用rows between指定窗口后可以计算移动平均
select a.*, avg(sale)over(order by sale desc) as avg_sale, avg(sale)over(order by sale desc rows between 1 preceding and 1 following) as avg_sale_1 from sale_detial a

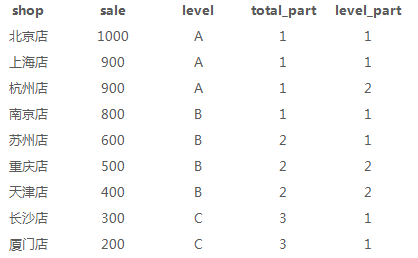
7、 店铺19年城市最高销量,各level最低销量(max/min)
max/min用法与sum一致
select a.*, max(sale)over() as max_sale, min(sale)over(partition by level) as level_min_sale from sale_detial a

二、排序
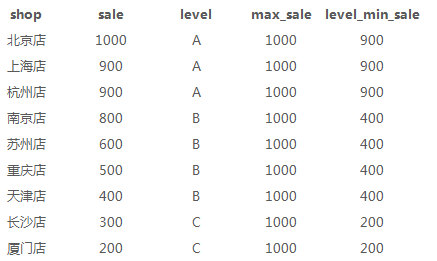
1、店铺19年各城市按销量排序(row_number,rank,dense_rank)
row_number——从1开始,按照顺序,生成分组内记录的序列
rank——成数据项在分组中的排名,排名相等会在名次中留下空位。
dense_rank——生成数据项在分组中的排名,排名相等会在名词中不会留下空位
select a.*, row_number()over(order by sale desc) as row_number, rank()over(order by sale desc) as rank, dense_rank()over(order by sale desc) as dense_rank from sale_detial a

三、极值
1、店铺19年销量最高最低城市,各level销量最低城市(first_value,last_value)
first_value,按分组排序后,取范围内第1个值,last_value,取最后1个值
因为默认窗口的关系,last_value会随着窗口的改变而改变,所以一般不用last_value,如果要用,则改变窗口为所有行
select a.*, first_value(city)over(order by sale desc) as max_city, first_value(city)over(order by sale asc) as min_city, last_value(city)over(order by sale desc) as min_city_1, last_value(city)over(partition by level order by sale desc rows between unbounded preceding and unbounded following) as level_min_city from sale_detial a


四、移动
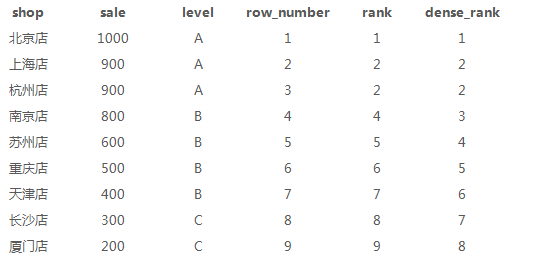
1、店铺19年按level分组后各城市销量前1位和后1位的城市(lag,lead)
lag/lead是按照排序规则,取前多少位和后多少位,参数有3个,第1个是要取出来的列,第2个移动多少位,第3个是如果取不到,赋予的值,默认取不到是NULL
select a.*, lag(city,1,null)over(partition by level order by sale desc) as lag_city, lead(city,1,'0')over(partition by level order by sale desc) as lead_city from sale_detial a

五、切片
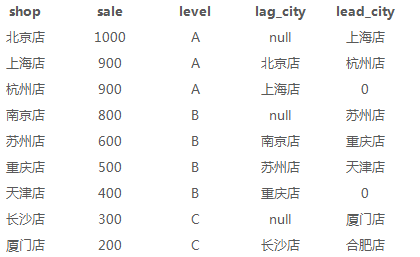
1、店铺19年按销量切片、各level按销量切片(ntile)
ntile(n),用于将分组数据按照顺序切分成N片,返回当前切片值。ntile不支持rows between,如果切片不均匀,默认增加第一个切片的分布。
ntile这个很强大,以前要获取一定比例的数据是非常困难的,ntile就是把有序分区中的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,ntile返回此行所属的组的编号
select a.*, ntile(3) over(order by sale desc) as total_part, ntile(2)over(partition by level order by sale desc) as level_part from sale_detial a

本文摘自:https://blog.csdn.net/cindy407/java/article/details/105394672
