J07-Java IO流总结七 《 InputStreamReader和OutputStreamWriter 》
前面在介绍FileReader和FileWriter的时候有说到,FileReader的读取字符功能,以及FileWriter的写出字符的功能,都不是它们自己实现的,而是,它们分别继承了InputStreamReader和OuputStreamWriter这两个转换流,利用这两个转换流,实现了字节数据与字符数据之间的转换,关于这点可以通过FileReader和FileWriter的源码看出来。
下面将介绍这两个转换流,并分别通过几个简单的应用场景来熟悉它们的用法。
1. InputStreamReader
1.1 概念介绍
InputStreamReader将底层的字节数据转换为字符数据,可以显式的或者使用平台默认的字符集进行转换。所有的字符流的转换工作都依赖于它来完成。
根据API文档的描述,InputStreamReader 是字节流通向字符流的桥梁,它使用指定的 charset 读取字节并将其解码为字符。它使用的字符集可以由名称指定或显式给定,或者可以接受平台默认的字符集。
每次调用 InputStreamReader 中的一个 read() 方法都会导致从底层输入流读取一个或多个字节。要启用从字节到字符的有效转换,可以提前从底层流读取更多的字节,使其超过满足当前读取操作所需的字节。
为了达到最高效率,可要考虑在 BufferedReader 内包装 InputStreamReader。例如:
BufferedReader in = new BufferedReader(new InputStreamReader(System.in));
关于源码:
InputStreamReader的源码比较简单,它有一个非常重要的成员变量:
private final StreamDecoder sd;
InputStreamReader的主要实现都调用了这个流解码类StreamDecoder,它只有这一个成员变量,而这一个类把它的所有操作都包括了。StreamDecoder的主要作用是获取一个字节输入流InputStream,然后根据给定的编码方案读取字符,如果没有给定,则默认是系统编码。
由源码可知,InputStreamReader的设计使用到了装饰设计模式,它本身并没有提供啥功能,具体的实现其实都由StreamDecoder来实现了。
源码中关于InputStreamReader的几个构造方法需要格外注意一下,因为通过它的构造方法,可以显式的指定解码所需的字符集:
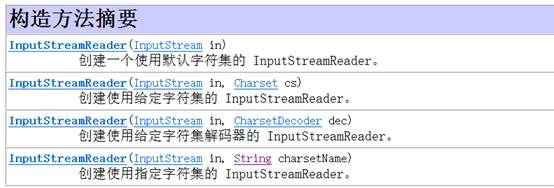
1.2 应用示例
System.in是字节流对象,代表键盘的输入,如果我们想按行接收用户的输入时,就必须用到缓冲字符流BufferedReader特有的方法readLine(),但是经过观察会发现在创建BufferedReader的构造方法的参数必须是一个Reader对象,如下:
public BufferedReader(Reader in)
这时候我们的转换流InputStreamReader就派上用场了。
示例代码如下所示:
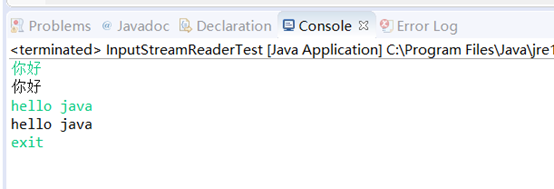
import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; public class InputStreamReaderTest { public static void main(String[] args) { BufferedReader br = null; String str = null; try { br = new BufferedReader(new InputStreamReader(System.in)); while(!"exit".equals(str = br.readLine())) { System.out.println(str); } } catch (IOException e) { e.printStackTrace(); } } }
代码运行效果:
2. OutputStreamWriter
2.1 概念介绍
OutputStreamWriter是将字符数据转换为字节数据的流。可以显式的或者使用平台默认的字符集进行转换。所有的字符输出流的转换工作都依赖于它来完成。
根据API文档的描述,OutputStreamWriter 是字符流通向字节流的桥梁:可使用指定的 charset 将要写入流中的字符编码成字节。它使用的字符集可以由名称指定或显式给定,否则将接受平台默认的字符集。
每次调用 write() 方法都会导致在给定字符(或字符集)上调用编码转换器。在写入底层输出流之前,得到的这些字节将在缓冲区中累积。可以指定此缓冲区的大小,不过,默认的缓冲区对多数用途来说已足够大。注意,传递给 write() 方法的字符没有缓冲。
为了获得最高效率,可考虑将 OutputStreamWriter 包装到 BufferedWriter 中,以避免频繁调用转换器。例如:
Writer out = new BufferedWriter(new OutputStreamWriter(System.out));
源码:
阅读OutputStreamWriter的源码,可以发现它跟InputStreamReader一样使用了装饰器模式,在它的类当中,持有了一个的引用StreamEncoder的应用,StreamEncoder可以理解为一个编码器,当调用OutputStreamWriter的write、close方法时,实际上底层调用的还是这个StreamEncoder的方法。
需要留意一下OutputStreamWriter的构造方法:

2.2 应用示例
System.out是字节流对象,代表输出到显示器,在上面的示例中按行读取用户的输入后,并且要将读取的一行字符串直接显示到控制台,就需要用到字符流的write(String str)方法,所以我们要使用OutputStreamWriter将字符流转化为字节流。
示例代码如下所示:
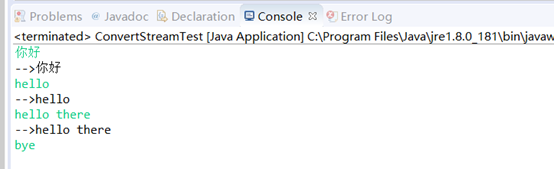
import java.io.BufferedReader; import java.io.BufferedWriter; import java.io.IOException; import java.io.InputStreamReader; import java.io.OutputStreamWriter; public class ConvertStreamTest { public static void main(String[] args) { BufferedReader br = null; BufferedWriter bw = null; String str = null; try { br = new BufferedReader(new InputStreamReader(System.in)); bw = new BufferedWriter(new OutputStreamWriter(System.out)); while(!"bye".equals(str = br.readLine())) { bw.write("-->" + str); bw.newLine(); bw.flush(); } } catch (IOException e) { e.printStackTrace(); } } }
代码运行效果:
3 转换流综合应用示例
下面的示例代码中定义了两个方法,分别为Utf8ToGbk()和gbkToUtf8(),其中,Utf8ToGbk()实现了从一个用UTF-8编码的源文件复制数据到一个用GBK编码的目标文件,gbkToUtf8()方法则正好反之。
示例代码:
import java.io.BufferedReader; import java.io.BufferedWriter; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.FileReader; import java.io.FileWriter; import java.io.IOException; import java.io.InputStreamReader; import java.io.OutputStreamWriter; import java.io.UnsupportedEncodingException; public class ConvertTest { public static void main(String[] args) { // gbkToUtf8(); Utf8ToGbk(); } //////////////////////////////////////////////////////////// private static void Utf8ToGbk() { BufferedReader br = null; BufferedWriter bw = null; try { br = new BufferedReader(new InputStreamReader(new FileInputStream("./src/res/2_copy.txt"), "utf-8")); bw = new BufferedWriter(new FileWriter("./src/res/2.txt")); // bw = new BufferedWriter(new OutputStreamWriter(new FileOutputStream("./src/res/2.txt"))); String str = null; while(null != (str = br.readLine())) { bw.write(str); bw.newLine(); } } catch (FileNotFoundException e) { e.printStackTrace(); } catch (UnsupportedEncodingException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } finally { if(null != bw) { try { bw.close(); } catch (IOException e) { e.printStackTrace(); } } if(null != br) { try { br.close(); } catch (IOException e) { e.printStackTrace(); } } } } //////////////////////////////////////////////////////////// private static void gbkToUtf8() { BufferedReader br = null; BufferedWriter bw = null; try { br = new BufferedReader(new FileReader("./src/res/2.txt")); // br = new BufferedReader(new InputStreamReader(new FileInputStream("./src/res/2.txt")));//使用默认字符集 bw = new BufferedWriter(new OutputStreamWriter(new FileOutputStream("./src/res/2_copy.txt"), "utf-8")); String str = null; while(null != (str = br.readLine())) { bw.write(str); bw.newLine(); } } catch (FileNotFoundException e) { e.printStackTrace(); } catch (UnsupportedEncodingException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } finally { if(null != bw) { try { bw.close(); } catch (IOException e) { e.printStackTrace(); } } if(null != br) { try { br.close(); } catch (IOException e) { e.printStackTrace(); } } } } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号