自定义分词器-基于ik_analyzer过滤json的key
由于工作需要,有时候字段中存储的值是诸如 {"name":"车辆vid"} 这样的值,并且我们只需要对json串中的value进行分词,而不需要对key也进行分词搜索
假设直接使用ik_max_word对json串进行分词,得到的结果如下所示:
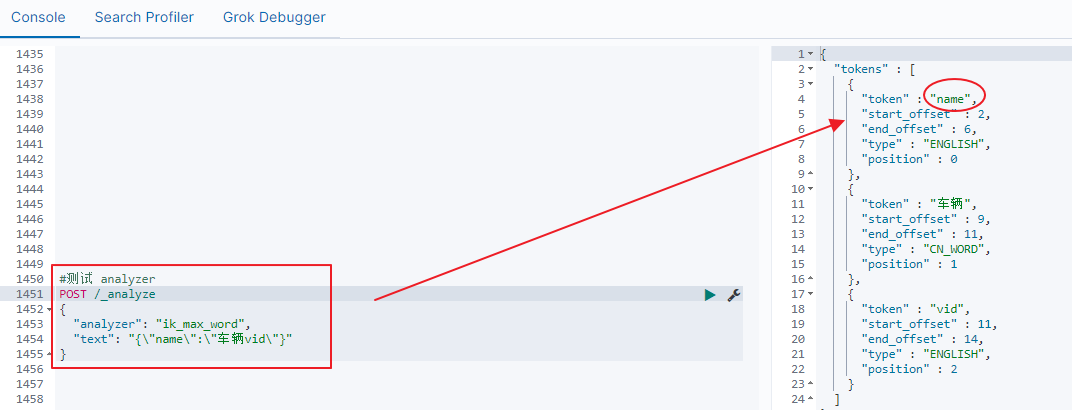
可以看到,json的key也被解析成一個token了,这显然不是我们要的结果。
下面自定义一个名为my_custom_json_ik_analyzer的分詞器
PUT susu_test2
{
"settings": {
"analysis": {
"analyzer": {
"my_custom_json_ik_analyzer": {
"char_filter": [
"json_key_char_filter"
],
"tokenizer": "ik_max_word"
}
},
"char_filter": {
"json_key_char_filter": {
"pattern": "(\"\\w*\")(\\s*)(:)",
"type": "pattern_replace",
"replacement": ""
}
}
}
}
}
如下图:
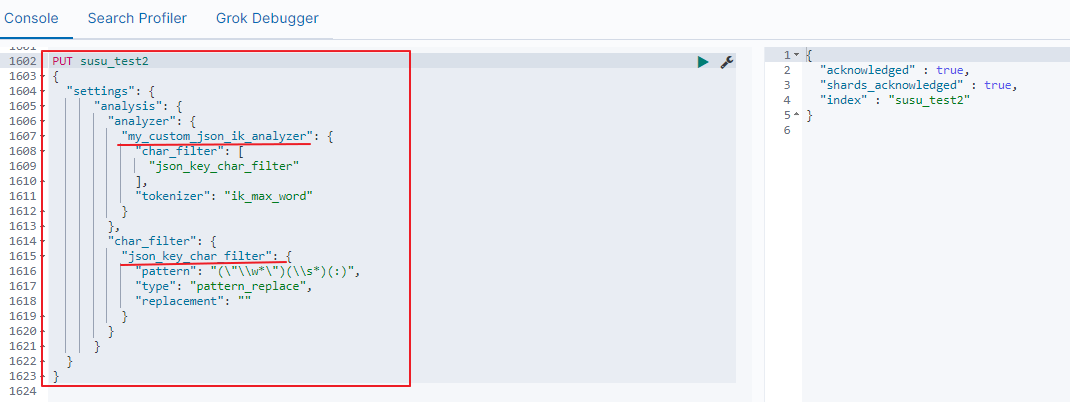
该分词器是在ik_max_word的基础上,添加了【自定义的】名为json_key_char_filter的character filter,用于在分词前,先过滤掉字段中的json字符串的key。
而json_key_char_filter的character filter,则是基于 pattern_replace,用正则表达式的方式来将json字符串中的key给替换为空的方式,将json串中的key给替换掉了。
接下来测试自定义的分词器:
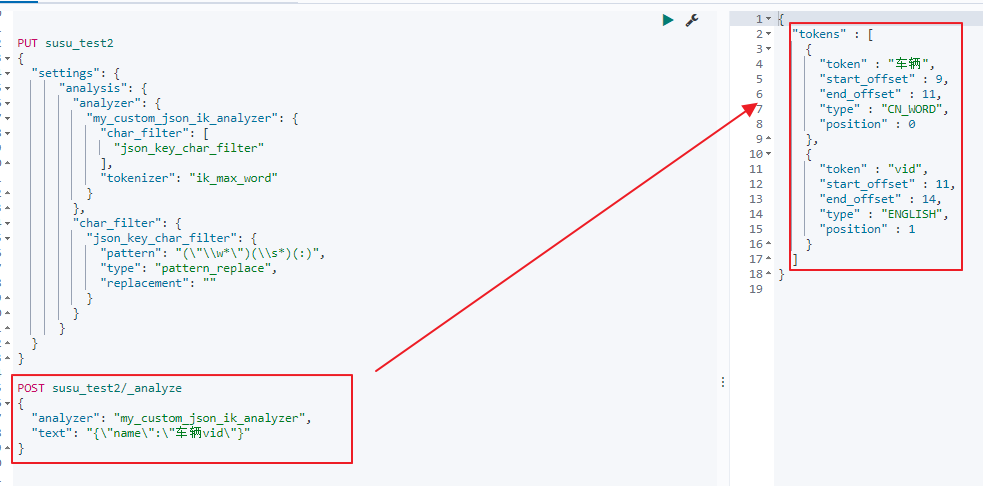
可以看到,自定义的分词器,只对json串的value进行分词。
