自定义分词器-ik analyzer+html_strip
由于工作中的业务需要,需要定义这么一个分词器,用于对一个名为remark的字段进行分词。
其中,remark字段适用于存储富文本类型的信息, 比如 <p>这是一个<b>接口</b>啊</p>
如果直接使用ik_max_word对字段进行分词,那么得到的分词结果如下图所示:
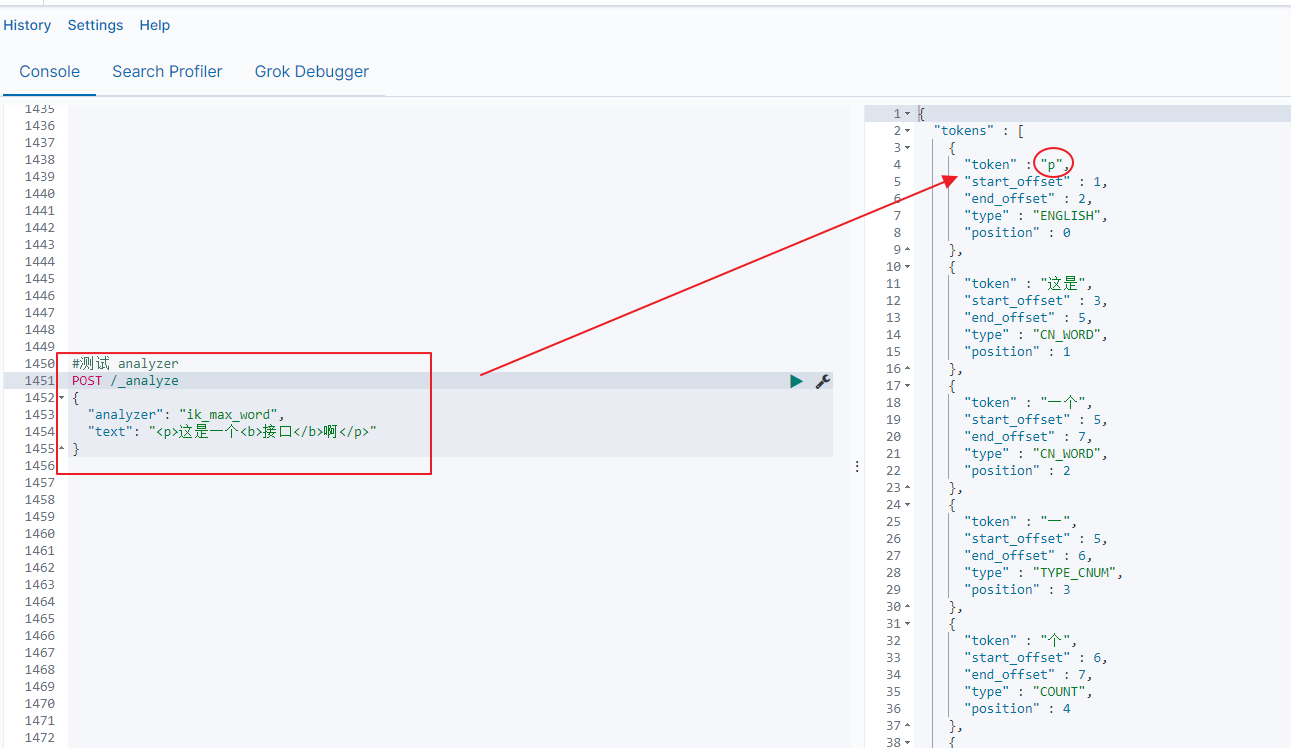
如上图,可以看到,富文本中的html标签<p> </p> 等,都被解析成一个token了,显然这不是我们想要的结果。
下面我们自定义一个名为my_custom_html_ik_analyzer,它基于ik_max_word创建,在ik_max_word的基础上,添加了html_strip的character filter,添加这个character filter,主要用于在分词前,先过滤掉字段中的html标签
测试:
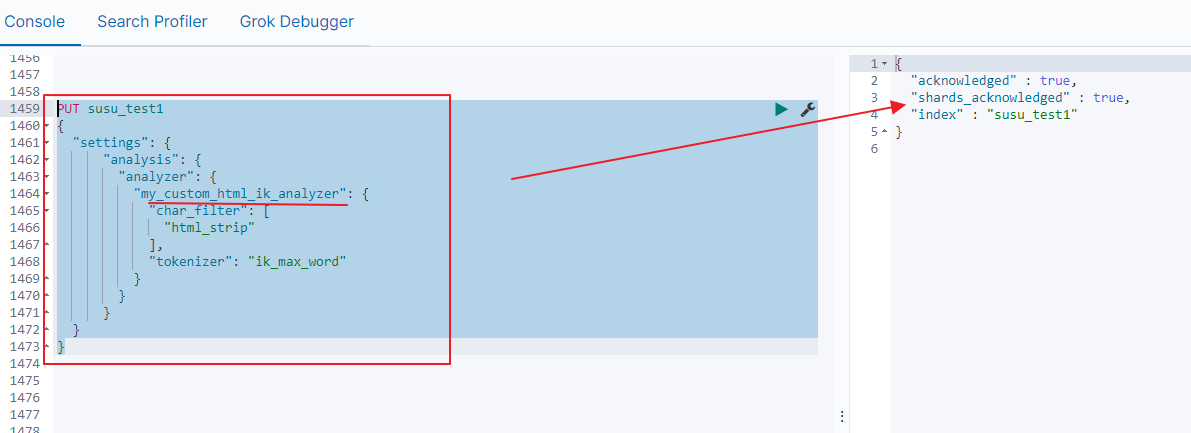
PUT susu_test1
{
"settings": {
"analysis": {
"analyzer": {
"my_custom_html_ik_analyzer": {
"char_filter": [
"html_strip"
],
"tokenizer": "ik_max_word"
}
}
}
}
}
如下图:
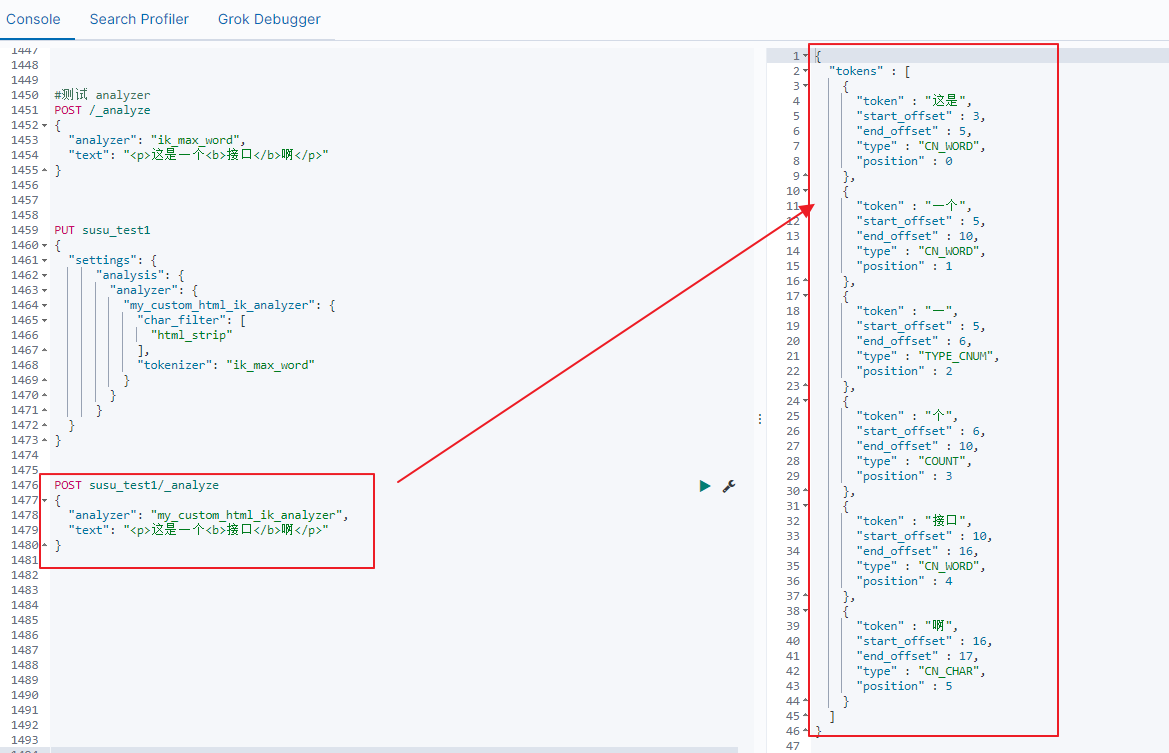
接着测试我们自定义个分词器,如下图
可以看到,诸如<p> </p> <b> </b>等html标签,都已经被过滤掉了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号