7.InfluxDB-InfluxQL基础语法教程--INTO子句
本文翻译自官网,官网地址:(https://docs.influxdata.com/influxdb/v1.7/query_language/data_exploration/)
通过INTO子句,可以将用户的查询结果插入到用户指定的measurement中。
语法
SELECT_clause
INTO <measurement_name>
FROM_clause [WHERE_clause] [GROUP_BY_clause]
INTO子句支持如下语法,使得用户可以使用不同方式来指定要插入数据的measurement:
| 子句 | 意义 |
|---|---|
| INTO <measurement_name> | 插入到指定measurement中。此时使用的是当前库、使用默认的retention policy |
| INTO <database_name>.<retention_policy_name>.<measurement_name> | 往全路径的measurement中插入数据。此时指定了库、指定retention policy、指定measurement |
| INTO <database_name>..<measurement_name> | 往指定库的指定measurement中插入数据,使用默认的retention policy |
| INTO <database_name>.<retention_policy_name>.:MEASUREMENT FROM /<regular_expression>/ | 往指定库、指定retentioin policy,并且符合FROM子句中的正则规则的measurement中插入数据 |
INTO示例sql
- 示例一
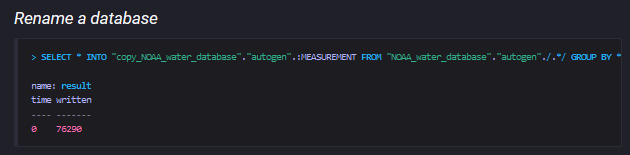
在InfluxDB中,是无法直接重命名一个库的,所以一个通常的做法是,像如上的sql那样,把一个库的所有数据全部复制到另一库中去。
其中 GROUP BY * 子句使得在源库中是tag key的字段,复制到目标库中之后依然是tag key。下面的sql就不维护tag的series上下文环境,如此一来在源库中的tag key在被复制到目标库之后,就变成fields了:
SELECT *
INTO "copy_NOAA_water_database"."autogen".:MEASUREMENT
FROM "NOAA_water_database"."autogen"./.*/
当需要复制大量的数据时,官方推荐一个一个measurement的进行复制,并且最好通过WHERE子句来指定时间区间,这样可以避免系统出现内存溢出的错误。如下面的sql就展示了通过指定时间区间来分批的进行数据复制操作:
SELECT *
INTO <destination_database>.<retention_policy_name>.<measurement_name>
FROM <source_database>.<retention_policy_name>.<measurement_name>
WHERE time > now() - 100w and time < now() - 90w GROUP BY *
SELECT *
INTO <destination_database>.<retention_policy_name>.<measurement_name>
FROM <source_database>.<retention_policy_name>.<measurement_name>}
WHERE time > now() - 90w and time < now() - 80w GROUP BY *
SELECT *
INTO <destination_database>.<retention_policy_name>.<measurement_name>
FROM <source_database>.<retention_policy_name>.<measurement_name>
WHERE time > now() - 80w and time < now() - 70w GROUP BY *
-
示例二
将一次查询结果写入到一个measurement中:

上面sql将它的查询结果插入到一个新建的名为h2o_feet_copy_1的measurement中。执行sql的结果显示总共插入了7604条结果数据到h2o_feet_copy_1中,时间戳1970-01-01T00:00:00Z则没有什么意思,前面说过,在InfluxDB中,使用1970-01-01T00:00:00Z来表示timestamp的null。 -
示例三
将查询结果插入到一个全路径的measurement中
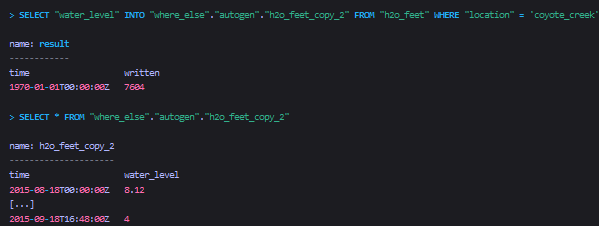
Note that both where_else and autogen must exist prior to running the INTO query. -
示例四
将聚合查询结果插入到measurement中(缩减取样)
SELECT MEAN("water_level") INTO "all_my_averages" FROM "h2o_feet"
WHERE "location" = 'coyote_creek'
AND time >= '2015-08-18T00:00:00Z'
AND time <= '2015-08-18T00:30:00Z'
GROUP BY time(12m)

- 示例五
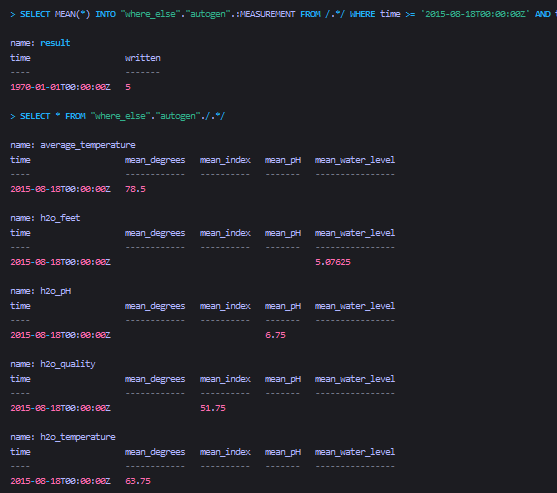
将多个表的汇总查询结果,复制到另一个库中
Sql
SELECT MEAN(*)
INTO "where_else"."autogen".:MEASUREMENT
FROM /.*/
WHERE time >= '2015-08-18T00:00:00Z'
AND time <= '2015-08-18T00:06:00Z'
GROUP BY time(12m)
查询结果
INTO子句常见问题
问题1:丢失数据
如果在一个INTO查询中,再把数据复制到目标库时会把源库的tag key转换为fields,这可能会导致influxdb覆盖先前由tag key区分的点。注意,此行为不适用于使用top()或bottom()函数的查询。在常见问题文档中可查看到该问题的详细描述。
为了防止源库的tag key复制到目标库之后编程fields,可以在INTO查询sql中使用group by有意义的tag key,或者group by \*.问题2:使用into子句自动化查询
本小节展示了如何通过into子句来实现手动插入复制数据的操作。可以在Continuous Queries的相关文档中查看到如何利用into子句实现实时的查询数据。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)